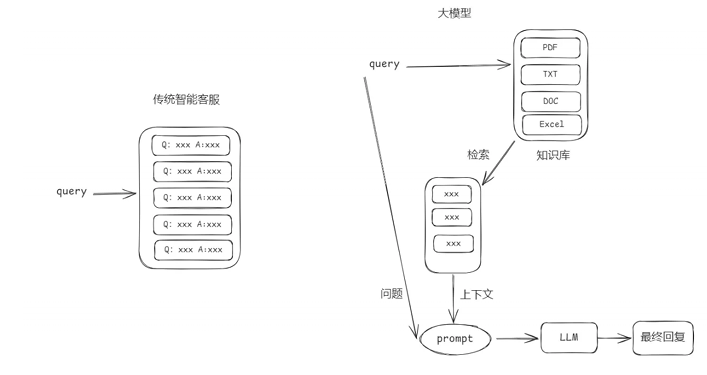
1 传统 VS 大模型
智能客服系统在没有大模型之前我们也是可以设计完成的只是实现的效果没有大模型那么好。下面是两则设计的原理
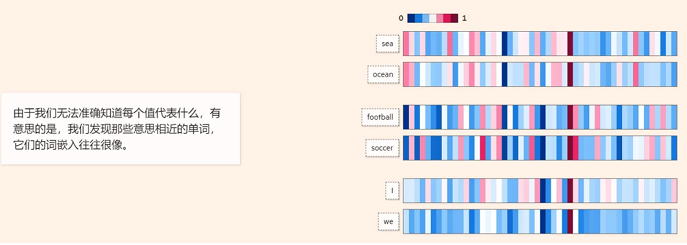
2 向量与Embeddings的定义
在数学中,向量(也称为欧几里得向量、几何向量),指具有大小 (magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表 向量的方向;线段长度:代表向量的大小。
text-embedding-3-large 是 OpenAI 推出的一个文本嵌入模型,属于 text embedding-3 系列中的大尺寸版本。是一个功能强大、灵活性高的文本嵌入模型, 适合处理复杂的自然语言任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public static float[] embedding(String prompt, String model){
if(model == null || model.isEmpty()){
model = "text-embedding-3-small";
}
OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, String.format("""{
"input": "%s",
"medel": "%s"
}""", prompt, model));
Request request = new Request.Builder()
.url(EMBEDDING_URL)
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer "+API_KEY)
.build();
ObjectMapper mapper = new ObjectMapper();
try {
Response response = client.newCall(request).execute();
ResponseBody responseBody = response.body();
String json = responseBody.string();
EmbeddingResponse embeddingResponse = mapper.readValue(json, EmbeddingResponse.class);
return embeddingResponse.getData().get(0).getEmbedding();
} catch (Exception e){
e.printStackTrace();
}
}
|
生成的数据信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| {
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.04382366,
0.02615503,
-0.019305877,
-0.021529805,
0.0016807369,
0.024040252,
-0.023835596,
0.0054643136
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 3,
"total_tokens": 3
}
}
|
3 向量间的相似度计算
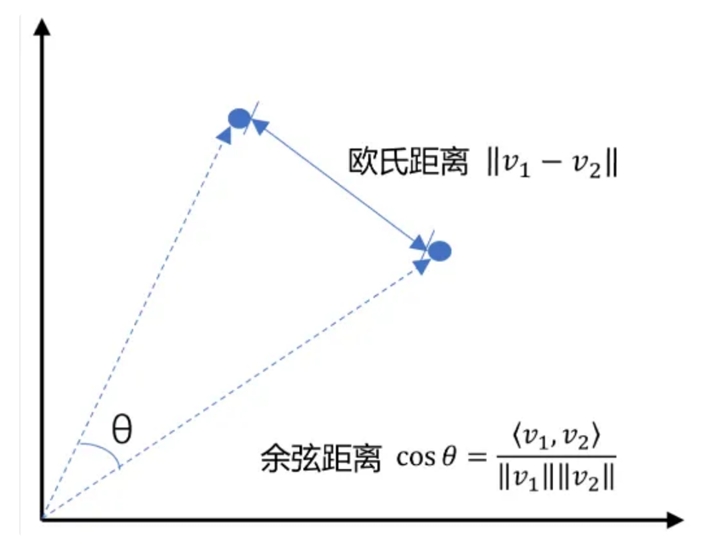
在处理向量数据时,计算向量之间的相似度是一个常见的需求。其中,欧式距离(Euclidean Distance)和余弦相似度(Cosine Similarity)是两种常用的计算方法。
欧式距离(Euclidean Distance)
欧式距离是指在n维空间中两个点之间的真实直线距离。它是基于几何学中的勾股定理来定义的。对于两个向量 ( A = [a_1, a_2, …, a_n] ) 和 ( B = [b_1, b_2, …, b_n]),它们之间的欧式距离 ( d(A, B) ) 可以通过以下公式计算:
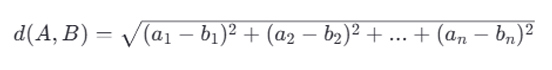
欧式距离越小,表示两个向量越接近。但是,欧式距离对数值大小非常敏感,如果向量的模长不一致,可能会导致不太准确的结果。
余弦相似度(Cosine Similarity)
余弦相似度衡量的是两个非零向量之间的角度差异。它关注的是向量的方向而非长度。对于两个向量 ( A ) 和 ( B ),它们之间的余弦相似度 ( \text{similarity}(A, B) ) 可以通过以下公式计算:
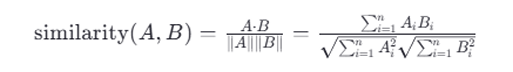
这里,( A \cdot B ) 表示向量 ( A ) 和 ( B ) 的点积,而 ( |A| ) 和 ( |B| ) 分别表示向量 ( A ) 和 ( B ) 的模长(即向量自身的平方和的平方根)。余弦相似度的值域为 [-1, 1],其中 1 表示完全相同的方向,-1 表示完全相反的方向,0 表示垂直或无相关性。
选择哪种方法?
- 欧式距离适用于当你关心向量的实际距离,且向量的尺度相对一致时。
- 余弦相似度更适合于比较文本、关键词向量等场景,因为这些情况下向量的方向比它们的模长更重要。
具体的案例演示代码,先添加对应的依赖: commons-math3来处理向量运算
1
2
3
4
5
| <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
|
LLMUtils中封装的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
public static double cosSim(RealVector a, RealVector b) {
return a.dotProduct(b) / (a.getNorm() * b.getNorm());
}
public static double l2(RealVector a, RealVector b) {
return a.subtract(b).getNorm();
}
public static double[] toDoubleArray(float[] floatArray){
if(floatArray == null){
return new double[0];
}
double[] doubleArray = new double[floatArray.length];
for (int i = 0; i < floatArray.length; i++) {
doubleArray[i] = floatArray[i];
}
return doubleArray;
}
public static void main(String[] args) {
String query = "人工智能伦理";
List<String> documents = new ArrayList<>();
documents.add("全球科技巨头联合发布AI伦理指南,强调透明度与公平性");
documents.add("欧盟通过新的法规,要求所有AI系统必须符合严格的隐私保护标准");
documents.add("科学家警告:如果不加以控制,AI可能会加剧社会不平等");
documents.add("国际会议讨论如何防止AI武器化,并呼吁制定国际条约");
documents.add("某国政府宣布将投资数十亿美元用于支持可持续发展的AI技术研究");
float[] embedding = LLMUtils.embedding(query, null);
RealVector embeddingVector = new ArrayRealVector(LLMUtils.toDoubleArray(embedding));
System.out.println("欧式距离");
System.out.println(LLMUtils.l2(embeddingVector,embeddingVector));
for (String document : documents) {
float[] documentEmbedding = LLMUtils.embedding(document, null);
double v = LLMUtils.l2(embeddingVector, new ArrayRealVector(LLMUtils.toDoubleArray(documentEmbedding)));
System.out.println(v);
}
System.out.println("余旋");
System.out.println(LLMUtils.cosSim(embeddingVector,embeddingVector));
for (String document : documents) {
float[] documentEmbedding = LLMUtils.embedding(document, null);
double v = LLMUtils.cosSim(embeddingVector, new ArrayRealVector(LLMUtils.toDoubleArray(documentEmbedding)));
System.out.println(v);
}
}
|
输出的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Cosine distance:
1.0000000000000002
0.5811625770172754
0.46230002404509946
0.49677067320389034
0.43804091372901155
0.3740802379939319
Euclidean distance:
0.0
0.9152458153492501
1.0370149440545149
1.0032240985379848
1.0601500863195614
1.1188563852278188
|
4 文档的加载和分割
4.1 基于文档的LLM回复系统搭建
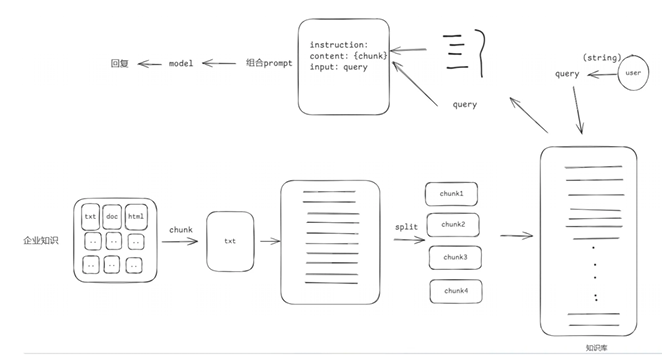
4.2 把文本切分成chunks
- 按照句子来切分
- 按照字符数来切分
- 按固定字符数结合overlapping window
- 递归方法 RecursiveCharacterTextSplitter
4.2.1按照句子来切分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ChineseSentenceSplitter{
public static List<String> splitChineseSentences(String text) {
String regex = "([。?!]|\\…\\…)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
List<String> sentences = new ArrayList<>();
List<String> punctuations = new ArrayList<>();
int lastEnd = 0;
while (matcher.find()) {
String sentence = text.substring(lastEnd, matcher.start() + 1);
sentences.add(sentence);
punctuations.add(matcher.group(1));
lastEnd = matcher.end();
}
if (lastEnd < text.length()) {
sentences.add(text.substring(lastEnd));
punctuations.add("");
}
List<String> result = new ArrayList<>();
for (int i = 0; i < sentences.size(); i++) {
String sentence = sentences.get(i);
String punctuation = (i < punctuations.size()) ? punctuations.get(i) : "";
result.add(sentence + punctuation);
}
return result;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
List<String> chunks = splitChineseSentences(text);
for (int i = 0; i < chunks.size(); i++) {
System.out.printf("块 %d: 长度 %d: %s%n", i + 1,
chunks.get(i).length(), chunks.get(i));
}
}
}
|
输出的结果
1
2
3
4
5
6
7
| 块 1: 55: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。
块 2: 21: 在这个领域,机器学习发挥着至关重要的作用。
块 3: 30: 利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。
块 4: 36: 从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。
块 5: 33: 随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。
块 6: 46: 如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。
块 7: 41: NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
|
4.2.2 按照字符数来切分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import java.util.ArrayList;
import java.util.List;
public class TextChunkSplitter {
public static List<String> splitByFixedCharCount(String text, int chunkSize) {
List<String> chunks = new ArrayList<>();
int length = text.length();
for (int i = 0; i < length; i += chunkSize) {
int end = Math.min(i + chunkSize, length);
chunks.add(text.substring(i, end));
}
return chunks;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
int chunkSize = 100;
List<String> chunks = splitByFixedCharCount(text, chunkSize);
for (int i = 0; i < chunks.size(); i++) {
String chunk = chunks.get(i);
System.out.printf("块 %d: 长度 %d: %s%n", i + 1,
chunk.length(), chunk);
}
}
}
|
输出结果
1
2
3
| 块 1: 100: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所
块 2: 100: 理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理
块 3: 62: 解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
|
4.2.3 按固定字符数加滑动窗口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import java.util.ArrayList;
import java.util.List;
public class SlidingWindowTextSplitter {
public static List<String> slidingWindowChunks(String text, int chunkSize, int stride) {
List<String> chunks = new ArrayList<>();
int length = text.length();
if (chunkSize <= 0 || stride <= 0) {
throw new IllegalArgumentException("chunkSize 和 stride 必须大于0");
}
for (int i = 0; i < length; i += stride) {
int end = Math.min(i + chunkSize, length);
String chunk = text.substring(i, end);
chunks.add(chunk);
}
return chunks;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
int chunkSize = 100;
int stride = 50;
List<String> chunks = slidingWindowChunks(text, chunkSize, stride);
for (int i = 0; i < chunks.size(); i++) {
String chunk = chunks.get(i);
System.out.printf("块 %d: 长度 %d: %s%n", i + 1,
chunk.length(), chunk);
}
}
}
|
输出的结果
1
2
3
4
5
6
| 块 1: 100: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所
块 2: 100: 言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术
块 3: 100: 理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理
块 4: 100: 的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和
块 5: 62: 解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
块 6: 12: 智能水平起到了关键作用。
|
4.2.4 递归方法
递归字符文本分割通过指定字符(或字符组)进行分割,逐层尝试,直到每个块的大小小于指定的阈值。这种方法善于保持文本的语义完整性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| import java.util.*;
public class RecursiveCharacterTextSplitter {
private final List<String> separators;
private final int chunkSize;
private final int chunkOverlap;
public RecursiveCharacterTextSplitter(int chunkSize, int chunkOverlap, List<String> separators) {
this.separators = separators;
this.chunkSize = chunkSize;
this.chunkOverlap = chunkOverlap;
}
public List<String> splitText(String text) {
List<String> chunks = new ArrayList<>();
splitRecursive(text, chunks, 0);
return chunks;
}
private void splitRecursive(String text, List<String> chunks, int currentOverlap) {
if (text.length() <= chunkSize) {
chunks.add(text);
return;
}
for (String sep : separators) {
List<Integer> indices = findAllIndices(text, sep);
for (int i = indices.size() - 1; i >= 0; i--) {
int idx = indices.get(i);
if (idx + sep.length() + currentOverlap <= chunkSize) {
String firstChunk = text.substring(0, idx + sep.length());
String rest = text.substring(idx + sep.length());
chunks.add(firstChunk);
splitRecursive(rest, chunks, Math.max(0, firstChunk.length() - (chunkSize - chunkOverlap)));
return;
}
}
}
chunks.add(text.substring(0, Math.min(chunkSize, text.length())));
if (text.length() > chunkSize) {
splitRecursive(text.substring(chunkSize), chunks, Math.max(0, chunkSize - chunkOverlap));
}
}
private List<Integer> findAllIndices(String text, String separator) {
List<Integer> indices = new ArrayList<>();
int index = text.indexOf(separator);
while (index >= 0) {
indices.add(index);
index = text.indexOf(separator, index + separator.length());
}
return indices;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
RecursiveCharacterTextSplitter splitter = new RecursiveCharacterTextSplitter(50, 10, Arrays.asList("\n\n", "\n", "。", ",", " ", ""));
List<String> chunks = splitter.splitText(text);
for (int i = 0; i < chunks.size(); i++) {
System.out.printf("块 %d: 长度 %d: %s%n%n", i + 1, chunks.get(i).length(), chunks.get(i));
}
}
}
|
输出的结果
1
2
3
4
5
6
7
| 块 1: 长度 34: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,
块 2: 长度 42: 致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。
块 3: 长度 30: 利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。
块 4: 长度 36: 从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。
块 5: 长度 33: 随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。
块 6: 长度 46: 如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。
块 7: 长度 41: NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
|
5 向量检索
关键字搜索:通过用户输入的关键字来查找文本数据
语义搜索:不仅考虑关键词的匹配,还考虑词汇之间的语义关系,以提供更准确的搜索结果。
5.1 关键字搜索
需要把相关的信息存储在Redis中。创建对应的实体对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class FaqItem {
private String instruction;
private String input;
private String output;
public String getInstruction() {
return instruction;
}
public void setInstruction(String instruction) {
this.instruction = instruction;
}
public String getInput() {
return input;
}
public void setInput(String input) {
this.input = input;
}
public String getOutput() {
return output;
}
public void setOutput(String output) {
this.output = output;
}
@Override
public String toString() {
return "FaqItem{" +
"instruction='" + instruction + '\'' +
", input='" + input + '\'' +
", output='" + output + '\'' +
'}';
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import com.boge.ai.entity.FaqItem;
import com.fasterxml.jackson.databind.ObjectMapper;
import redis.clients.jedis.Jedis;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
public class FaqService {
private static final String REDIS_KEY_PREFIX = "faq:";
private static final ObjectMapper objectMapper = new ObjectMapper();
private final Jedis jedis;
public FaqService(Jedis jedis) {
this.jedis = jedis;
}
public void loadFaqDataToRedis() throws IOException {
InputStream inputStream = getClass().getClassLoader().getResourceAsStream("train_zh.json");
if (inputStream == null) {
throw new FileNotFoundException("File not found in resources: data.json");
}
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))) {
String line;
int index = 0;
while ((line = reader.readLine()) != null) {
if (line.trim().isEmpty()) continue;
FaqItem item = objectMapper.readValue(line, FaqItem.class);
String key = REDIS_KEY_PREFIX + index++;
jedis.set(key, line);
}
}
}
public List<FaqItem> searchInstructionByKeyword(String keyword,int topNum) throws IOException {
Set<String> keys = jedis.keys(REDIS_KEY_PREFIX + "*");
List<FaqItem> result = new ArrayList<>();
for (String key : keys) {
String json = jedis.get(key);
FaqItem item = objectMapper.readValue(json, FaqItem.class);
if (item.getInstruction().contains(keyword)) {
result.add(item);
}
if(result.size() >= topNum) {
break;
}
}
return result;
}
}
|
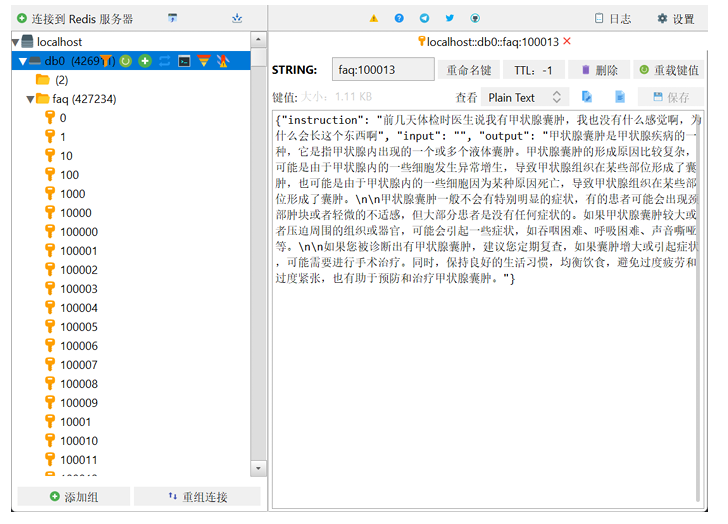
然后可以调用导入数据的方法
1
2
3
4
5
6
7
8
9
10
|
@Test
public void loadRedisFileData() throws Exception{
Jedis jedis = new Jedis("localhost", 6379);
FaqService faqService = new FaqService(jedis);
faqService.loadFaqDataToRedis();
}
|
然后就可以结合大模型来增强功能了, LLM 接⼝封装:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
public class LLMUtils {
private static final String BASE_URL = "https://api.openaihk.com/v1/chat/completions";
private static final String API_KEY = "hk-自己的key";
public static String completion(String prompt,String model){
OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
String messages = String.format("""
{
"messages":[{
"role": "user",
"content": "%s"
}],
"model":"%s"
}
""", StringEscapeUtils.escapeJson(prompt), model);
RequestBody body = RequestBody.create(mediaType, messages);
Request request = new Request.Builder()
.url(BASE_URL)
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer "+API_KEY)
.build();
Response response = null;
try {
response = client.newCall(request).execute();
ResponseBody responseBody = response.body();
String jsonString = responseBody.string();
System.out.println(jsonString);
ChatCompletionResponse chat = JsonToHashMapUtils.parseJsonToResponse(jsonString);
return chat.getChoices().get(0).getMessage().getContent();
}catch (Exception e){
e.printStackTrace();
}finally {
response.close();
}
return null;
}
}
|
Prompt模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
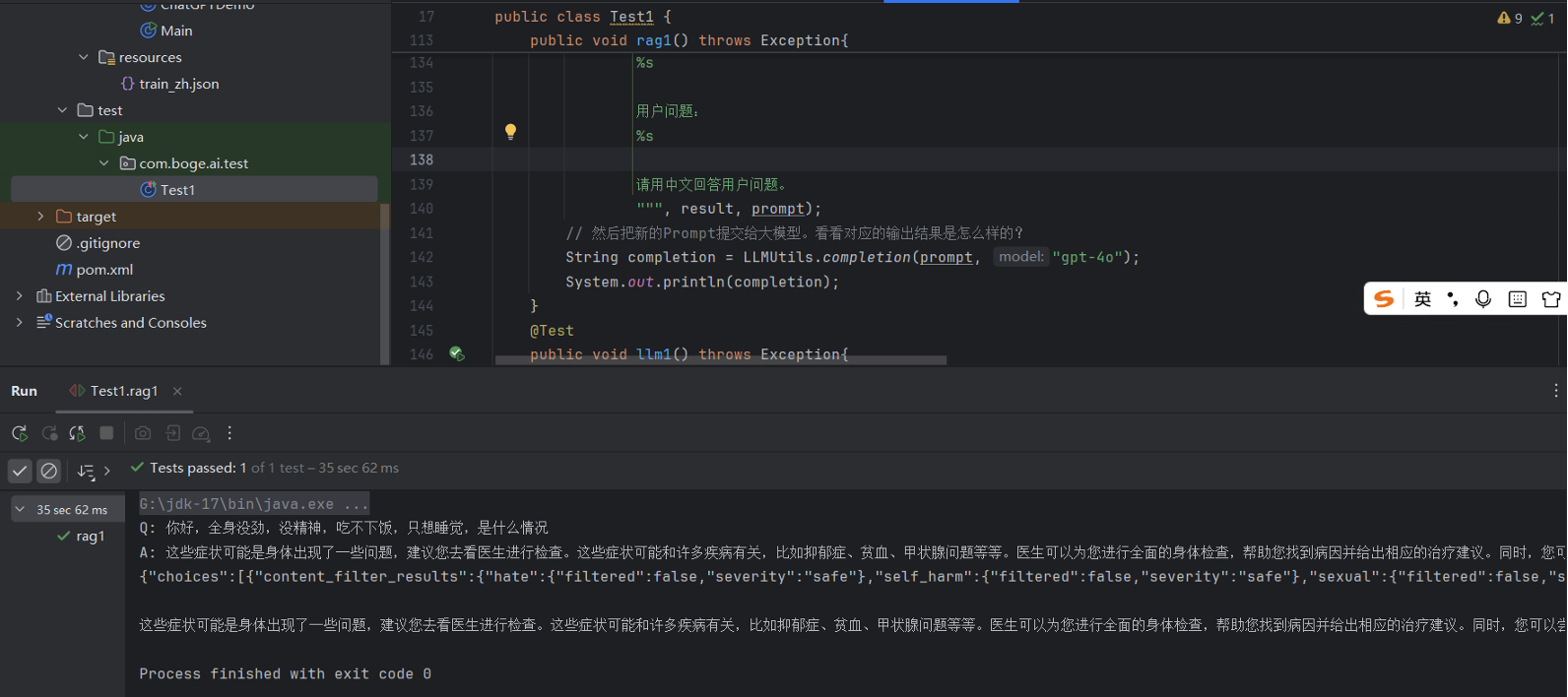
| @Test
public void rag1() throws Exception{
String prompt = "没精神,吃不下饭";
Jedis jedis = new Jedis("localhost", 6379);
FaqService faqService = new FaqService(jedis);
List<FaqItem> list = faqService.searchInstructionByKeyword(prompt, 3);
String result = list.stream()
.map(item -> "Q: " + item.getInstruction() + "\nA: " + item.getOutput())
.collect(Collectors.joining("\n"));
System.out.println(result);
prompt = String.format("""
# 角色
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
根据已知信息的内容推理给出用户问题的解决方案
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
%s
用户问题:
%s
请用中文回答用户问题。
""", result, prompt);
String completion = LLMUtils.completion(prompt, "gpt4o");
System.out.println(completion);
}
|
5.2 向量数据库
在人工智能时代,向量数据库已成为数据管理和AI模型不可或缺的⼀部分。向量数据库是⼀种专门设计用来存储和查询向量嵌入数据的数据库。这些向量嵌入是AI模型用于识别模式、关联和潜在结构的关键数据表示。
随着AI和机器学习应用的普及,这些模型生成的嵌入包含大量属性或特征,使得它们的表示难以管理。这就是为什么数据从业者需要⼀种专门为处理这种数据而开发的数据库,这就是向量数据库的用武之地。
Pinecone
Pinecone: www.pinecone.io/ ,关键特性包括:
- 重复检测:帮助用户识别和删除重复的数据
- 排名跟踪:跟踪数据在搜索结果中的排名,有助于优化和调整搜索策略
- 数据搜索:快速搜索数据库中的数据,支持复杂的搜索条件
- 分类:对数据进行分类,便于管理和检索
- 去重:自动识别和删除重复数据,保持数据集的纯净和⼀致性
Milvus
Milvus: www.milvus.io/ , 关键特性包括:
- 毫秒级搜索万亿级向量数据集
- 简单管理非结构化数据
- 可靠的向量数据库,始终可用
- 高度可扩展和适应性强
- 混合搜索
- 统⼀的Lambda结构
- 受到社区支持,得到行业认可
Chroma
Chroma: www.trychroma.com/ , 关键特性包括:
- 功能丰富:支持查询、过滤、密度估计等多种功能
- 即将添加的语言链(LangChain)、LlamaIndex等更多功能
- 相同的API可以在Python笔记本中运行,也可以扩展到集群,用于开发、测试和生产
Faiss
Faiss: https://github.com/facebookresearch/faiss ,关键特性包括:
- 不仅返回最近的邻居,还返回第⼆近、第三近和第k近的邻居
- 可以同时搜索多个向量,而不仅仅是单个向量(批量处理)
- 使用最大内积搜索而不是最小欧几里得搜索
- 也支持其他距离度量,但程度较低。
- 返回查询位置附近指定半径内的所有元素(范围搜索)
- 可以将索引存储在磁盘上,而不仅仅是RAM中
如何选型向量数据库
在选择适合项目的向量数据库时,需要根据项目的具体需求、团队的技术背景和资源情况来综合评估。以下是⼀些建议和注意事项:
向量嵌入的生成
- 如果已经有了自己的向量嵌入生成模型,那么需要的是⼀个能够高效存储和查询这些向量的数据库
- 如果需要数据库服务来生成向量嵌入,那么应该选择提供这类功能的产品
延迟要求
- 对于需要实时响应的应用程序,低延迟是关键。需要选择能够提供快速查询响应的数据库
- 如果应用程序允许批量处理,那么可以选择那些优化了大批量数据处理的数据库
开发人员的经验
- 根据团队的技术栈和经验,选择⼀个易于集成和使用的数据库
- 如果团队成员对某些技术或框架更熟悉,那么选择⼀个能够与之无缝集成的数据库会更有利
milvus演示
安装milvus服务, 下载地址
1
| https://github.com/milvusio/milvus/releases/download/v2.5.5/milvus-standalone-dockercompose.yml
|
需要在电脑上安装docker compose 然后进入到目录执行
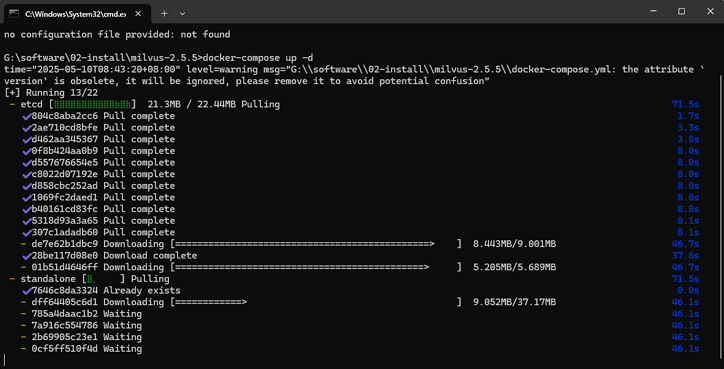
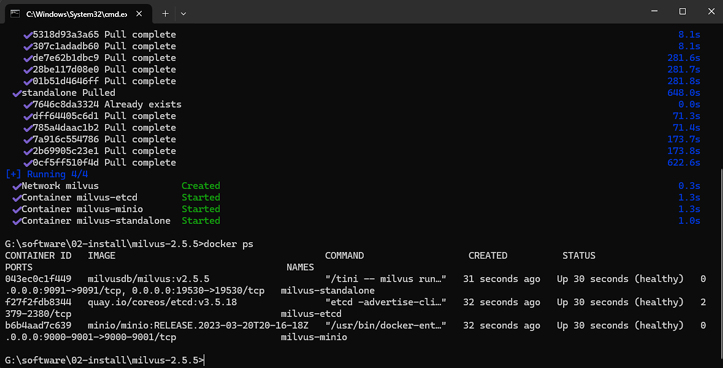
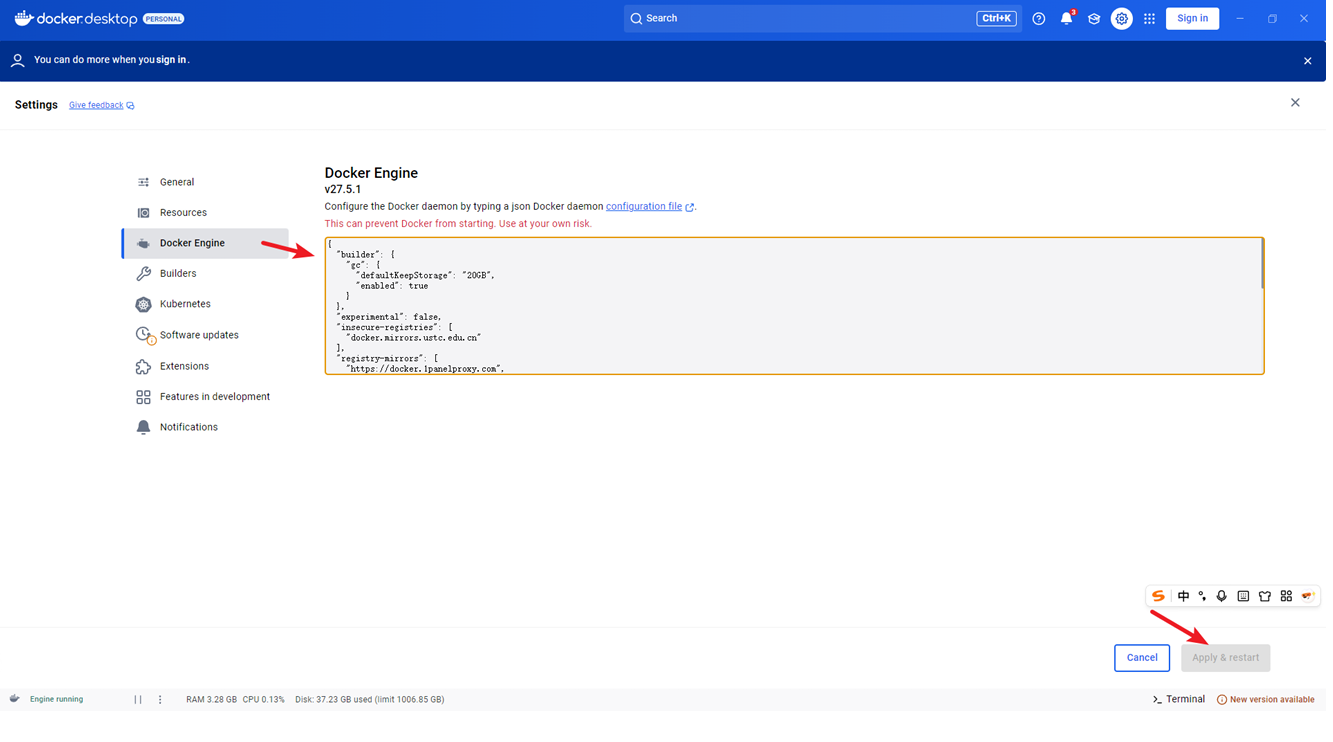
如果有提示镜像地址错误的话把dockerdesktop中的代理地址修改为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| {
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"insecure-registries": [
"docker.mirrors.ustc.edu.cn"
],
"registry-mirrors": [
"https://docker.1panelproxy.com",
"https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://your_preferred_mirror",
"https://dockerhub.icu",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}
|
添加两个的依赖
1
2
3
4
5
| <dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.2.10</version>
</dependency>
|
测试服务是否正常
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Test
public void testFun1() throws Exception {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost("localhost")
.withPort(19530)
.build();
MilvusServiceClient client = new MilvusServiceClient(connectParam);
HasCollectionParam hasCollectionParam = HasCollectionParam.newBuilder()
.withCollectionName("example")
.build();
System.out.println("Connected to Milvus: " + client.hasCollection(hasCollectionParam));
}
|
官方提供的webUI: http://127.0.0.1:9091/webui
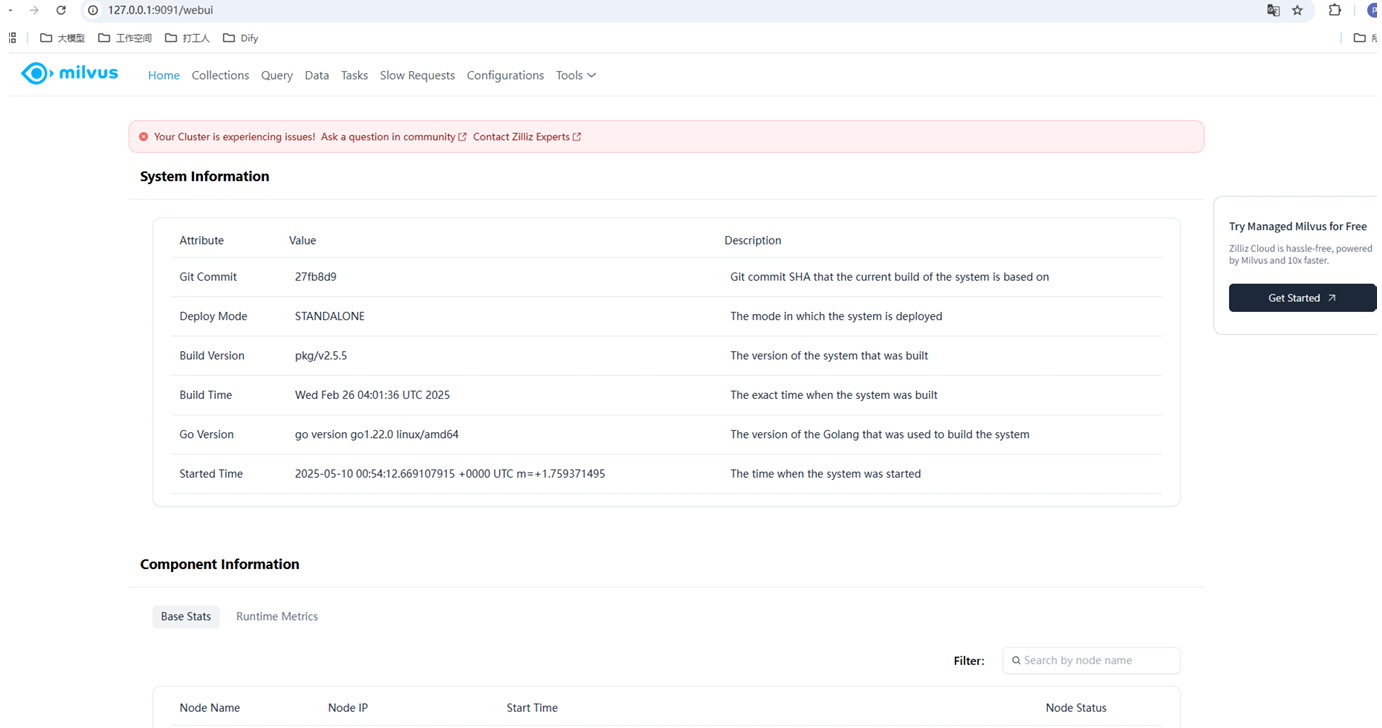
可视化工具Attu来连接milvus服务:https://github.com/zilliztech/attu/releases
把数据存储到向量数据库,并通过向量数据库完成了检索,先提供一个Milvus操作的工具方法,创建对应的实体对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class MilvusEntity{
public static final String DB_NAME = "default";
public static final String COLLECTION_NAME = "rag_collection";
public static final int SNARDS_NUM = 1;
public static final int PARTITION_NUM = 1;
public static final Integer FEATURE_DIM = 1536;
public static class Field{
public static final String ID = "id";
public static final String FEATURE = "feature";
public static final String TEXT = "instruction";
public static final String OUTPUT = "output";
}
}
|
提供的操作方法工具类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
| import com.boge.ai.entity.MilvusEntity;
import io.milvus.client.MilvusServiceClient;
import io.milvus.grpc.DataType;
import io.milvus.grpc.MilvusExt;
import io.milvus.grpc.SearchResults;
import io.milvus.param.ConnectParam;
import io.milvus.param.IndexType;
import io.milvus.param.MetricType;
import io.milvus.param.collection.CreateCollectionParam;
import io.milvus.param.collection.FieldType;
import io.milvus.param.dml.InsertParam;
import io.milvus.param.dml.SearchParam;
import io.milvus.param.index.CreateIndexParam;
import io.milvus.response.SearchResultsWrapper;
import okhttp3.*;
import org.apache.commons.math3.linear.RealVector;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class MilvusLLMUtils {
private MilvusServiceClient client ;
public MilvusLLMUtils() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost("localhost")
.withPort(19530)
.build();
client = new MilvusServiceClient(connectParam);
}
public void createCollection() throws Exception {
List<FieldType> fieldTypes = Arrays.asList(
FieldType.newBuilder()
.withName(MilvusEntity.Field.ID)
.withDescription("主键ID")
.withDataType(DataType.Int64)
.withPrimaryKey(true)
.withAutoID(true)
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.FEATURE)
.withDescription("特征向量")
.withDataType(DataType.FloatVector)
.withDimension(MilvusEntity.FEATURE_DIM)
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.TEXT)
.withDescription("输入数据")
.withDataType(DataType.VarChar)
.withTypeParams(Collections.singletonMap("max_length", "65535"))
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.OUTPUT)
.withDescription("问题答案数据")
.withDataType(DataType.VarChar)
.withTypeParams(Collections.singletonMap("max_length", "65535"))
.build());
CreateCollectionParam createCollectionReq = CreateCollectionParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withDescription("rag collection")
.withShardsNum(MilvusEntity.SHARDS_NUM)
.withFieldTypes(fieldTypes)
.build();
client.createCollection(createCollectionReq);
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withFieldName(MilvusEntity.Field.FEATURE)
.withIndexType(IndexType.IVF_FLAT)
.withMetricType(MetricType.L2)
.withExtraParam("{\"nlist\":128}")
.build();
client.createIndex(createIndexParam);
}
public void insertVectoryData(List<Float> vectorParam,String text,String output) throws Exception {
this.createCollection();
List<List<Float>> floats = new ArrayList<>();
floats.add(vectorParam);
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field(MilvusEntity.Field.FEATURE, floats));
fields.add(new InsertParam.Field(MilvusEntity.Field.TEXT, Arrays.asList(text)));
fields.add(new InsertParam.Field(MilvusEntity.Field.OUTPUT, Arrays.asList(output)));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withFields(fields)
.build();
client.insert(insertParam);
}
public SearchResultsWrapper search(List<Float> searchVectors) throws Exception {
List<List<Float>> floats = new ArrayList<>();
floats.add(searchVectors);
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withMetricType(MetricType.L2)
.withTopK(3)
.withVectors(floats)
.withVectorFieldName(MilvusEntity.Field.FEATURE)
.withOutFields(Arrays.asList(MilvusEntity.Field.ID,MilvusEntity.Field.OUTPUT))
.build();
SearchResults data = client.search(searchParam).getData();
if(data != null) {
SearchResultsWrapper resultsWrapper = new SearchResultsWrapper(data.getResults());
resultsWrapper.getRowRecords().forEach(result -> {
System.out.println("Search result: " + result);
});
return resultsWrapper;
}
return null;
}
}
|
然后可以加载文本数据,然后向量化之后存储到Milvus中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
@Test
public void fun1() throws Exception {
InputStream inputStream = getClass().getClassLoader().getResourceAsStream("train_zh.json");
MilvusLLMUtils milvusLLMUtils = new MilvusLLMUtils();
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))) {
String line;
int index = 0;
List<List<Float>> qaEmbedding = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList("得了白癜风怎么办?"));
while ((line = reader.readLine()) != null) {
if (line.trim().isEmpty()) continue;
FaqItem item = objectMapper.readValue(line, FaqItem.class);
String instruction = item.getInstruction();
List<List<Float>> embeddings = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList(instruction));
milvusLLMUtils.insertVectoryData(embeddings.get(0),instruction,item.getOutput());
}
SearchResultsWrapper searchResultsWrapper = milvusLLMUtils.search(qaEmbedding.get(0));
List<QueryResultsWrapper.RowRecord> rowRecords = searchResultsWrapper.getRowRecords();
if(rowRecords != null && !rowRecords.isEmpty()){
System.out.println(rowRecords);
}
}
}
|
可以用这个简化的方法来存储
1
2
3
4
5
6
7
8
9
10
11
12
| @Test
public void fun3() throws Exception {
MilvusLLMUtils milvusLLMUtils = new MilvusLLMUtils();
int index = 0;
List<List<Float>> qaEmbedding = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList("得了白癜风怎么办?"));
String instruction = "这段时间去上厕所本来想小便的可是每次都会拉大便";
List<List<Float>> embeddings = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList(instruction));
milvusLLMUtils.insertVectoryData(embeddings.get(0),instruction,"这可能是因为你的饮食习惯或者消化系统的问题导致的。建议你试着调整一下饮食,增加膳食纤维的摄入量,多喝水,避免过度依赖泻药。同时,如果问题持续存在,建议去医院检查一下,排除肠道疾病等可能性。");
}
|
然后可以结合查询的操作来检索关联的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void fun4() throws Exception {
MilvusLLMUtils milvusLLMUtils = new MilvusLLMUtils();
List<List<Float>> qaEmbedding = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList("得了白癜风怎么办?"));
SearchResultsWrapper searchResultsWrapper = milvusLLMUtils.search(qaEmbedding.get(0));
List<QueryResultsWrapper.RowRecord> rowRecords = searchResultsWrapper.getRowRecords();
if(rowRecords != null && !rowRecords.isEmpty()){
for (QueryResultsWrapper.RowRecord rowRecord : rowRecords) {
Map<String, Object> fieldValues = rowRecord.getFieldValues();
System.out.println(fieldValues.get("output"));
}
}
}
|
可以看到检索到的结果
输出的结果
1
2
3
| 白癜风的治疗费用因个体差异和治疗方案的不同而有所差异。初期治疗主要以口服药物和外用药物为主,费用相对较低,一般几百元左右。但是,如果采用激光治疗、光疗等高端治疗方法,费用会更高。建议您咨询专业医生,根据自己的情况进行治疗方案的选择,同时了解相关的费用情况。
您好,白癜风是一种自身免疫性疾病,主要特征是皮肤色素细胞的损伤和缺失,导致皮肤出现白斑。其遗传规律目前尚未完全明确,但一般认为是由多种基因和环境因素共同作用引起的。
虽然您的白癜风是半路起的,不是遗传的,但是由于您的儿子和儿媳妇并没有白癜风,所以您的孙子遗传白癜风的可能性很小。不过,如果您的孙子确实有遗传白癜风的风险,建议您与您的儿子和儿媳妇一起咨询医生,了解如何降低孙子患白癜风的风险,以及如何进行早期预防和治疗。同时,孕期保健和生活方式也对孩子的健康有很大影响,建议您的儿媳妇在孕期注意饮食、休息和避免吸烟等不良习惯,以保证孩子的健康成长。根据您提供的信息,孩子身上的白斑可能是多种原因导致的,例如真菌感染、色素脱失、营养不良等。白癜风是一种色素脱失性疾病,其特征是皮肤上出现白色斑块,但白斑界线不明显的情况不太符合白癜风的特点。建议您带孩子到医院皮肤科就诊,由专业医生进行诊断和治疗。
|
5.3 基于向量检索的RAG实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| @Test
public void rag1() throws Exception {
String prompt = "得了白癜风怎么办?";
MilvusLLMUtils milvusLLMUtils = new MilvusLLMUtils();
List<List<Float>> qaEmbedding = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList("得了白癜风怎么办?"));
SearchResultsWrapper searchResultsWrapper = milvusLLMUtils.search(qaEmbedding.get(0));
List<QueryResultsWrapper.RowRecord> rowRecords = searchResultsWrapper.getRowRecords();
List<FaqItem> list = new ArrayList<>();
if(rowRecords != null && !rowRecords.isEmpty()){
for (QueryResultsWrapper.RowRecord rowRecord : rowRecords) {
Map<String, Object> fieldValues = rowRecord.getFieldValues();
String output = fieldValues.get(MilvusEntity.Field.OUTPUT).toString();
String instrcution = fieldValues.get(MilvusEntity.Field.TEXT).toString();
FaqItem item = new FaqItem();
item.setInstruction(instrcution);
item.setOutput(output);
list.add(item);
}
}
String result = list.stream()
.map(item -> "Q: " + item.getInstruction() + "\nA: " + item.getOutput())
.collect(Collectors.joining("\n"));
prompt = String.format("""
# 角色
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
根据已知信息的内容推理给出用户问题的解决方案
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
%s
用户问题:
%s
请用中文回答用户问题。
""", result, prompt);
String completion = LLMUtils.completion(prompt, "gpt-4o");
System.out.println(completion);
}
}
|
输出的结果
1
2
3
4
5
6
| 根据已知信息,得了白癜风后,建议您采取以下措施:
1. **尽快就医**:白癜风是一种自身免疫性疾病,建议您及时前往专业医院的皮肤科就诊。医生会根据您的具体情况进行诊断,并制定个性化的治疗方案。
2. **选择合适的治疗方式**:根据目前的医学建议,白癜风初期治疗通常以口服药物和外用药物为主,费用相对较低。如果需要进一步治疗,激光治疗、光疗等高端方法也会被考虑,但费用较高。具体治疗应由专业医生根据病情决定。
3. **保持良好的生活习惯**:治疗期间,注意饮食健康、规律作息,避免过度劳累和情绪波动,增强免疫力。同时避免暴晒和皮肤损伤,减少外界刺激。
4. **具体问题咨询专业医生**:每个人的病情和身体条件不同,有任何疑问或治疗上的选择,建议直接与医生沟通,以获得适合自己的指导。
白癜风虽然可能影响生活,但早期治疗可以提高疗效,建议积极面对并配合医生进行治疗。
|