大模型介绍
1 大模型介绍
1.1 什么是大模型
大模型,全称「大语言模型」,英文「Large Language Model」,缩写 「LLM」。是一种基于机器学习和自然语言处理技术的模型,它通过对大量的文本 数据进行训练,来学习服务人类语言理解和生成的能力。eg: 一个人从小学到高中毕 业这整个的学习阶段 — 大模型的训练 。
介绍常见的大模型产品:
| 国家 | 对话产品 | 大模型 | 地址 |
|---|---|---|---|
| 美国 | OpenAI | GPT-4 Tuibo、GTP-4o | https://chat.openai.com/ |
| Microsoft Copilot | GPT-4、Phi-3(部分功能) | https://copilot.microsoft.com/ | |
| Google Gemini | Gemini Ultra、Gemini Pro | https://gemini.google.com/ | |
| Anthropic Clade | Claude3(Opus/Sonnet/Haiku) | https://claude.ai/ | |
| Inflection Pi | Inflection-2 | https://pi.ai/ | |
| xAI Grok | Grok-1.5 | https://grok.x.ai/ | |
| 中国 | 百度文心一言 | 文心大模型4.0 | https://yiyan.baidu.com/ |
| 讯飞星火 | 星火大模型V3.5 | https://xinghuo.xfyun.cn/ | |
| 智谱清言 | ChatGLM-4 | https://chatglm.cn/ | |
| 月之暗面 Kimi Chat | Moonshot V2(长文本支持 400万token) | https://kimi.moonshot.cn/ | |
| MiniMax星野 | abab6.5 | https://www.xingyai.com/ | |
| 零一万物万知 | Yi-Large | https://www.01.ai/cn | |
| 抖音豆包 | 云雀大模型 | https://www.doubao.com/ | |
| 阿里巴巴 通义千问 | 通义千问2.0,3.0 | https://tongyi.aliyun.com/ |
上面表格中大模型也称为基座大模型。下面是现在主流的两个大模型和对应的公司和相关的核心版本的发布时间的介绍对快速理解大模型的常识性的内容很有帮助。
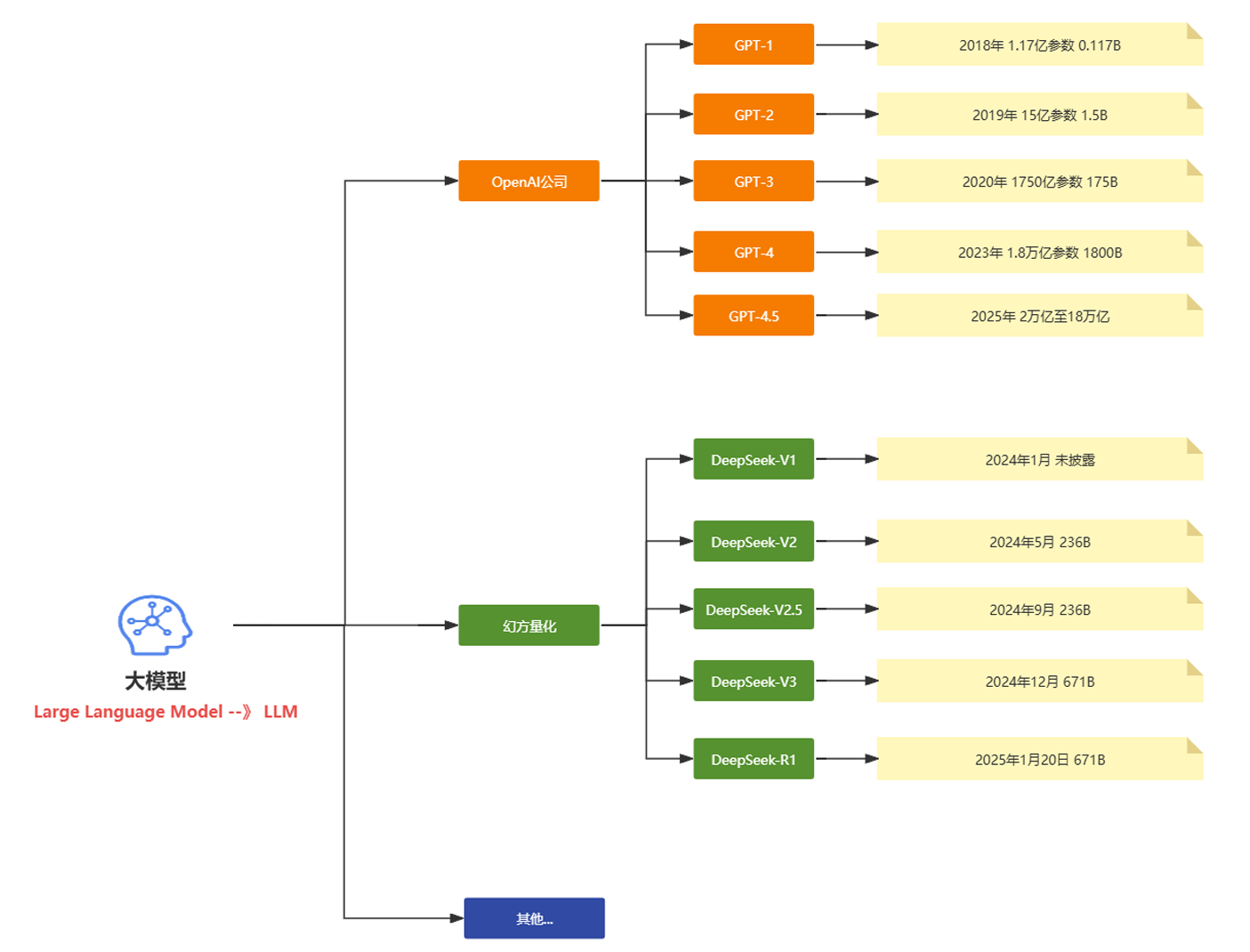
2025年国内外热门大模型分类表
| 类别 | 模型/产品 | 研发公司 | 核心亮点 | 典型应用场景 |
|---|---|---|---|---|
| 通用大模型 | GPT-4o | OpenAI | 全模态交互(文本/图像/ 视频),支持128k上下文窗口,动态参数分配降低30%推理成本 | 科研实验、创意产 业、跨模态生成 |
| Gemini 2.0 Pro | 集成实时搜索数据,支持20种语言无缝切换,响 应延迟<500ms | 教育个性化学 习、企业服务 | ||
| DeepSeek- R1 | 深度求索 | 开源可商用,训练成本仅为国际模型1/10,推理效率提升3倍 | 工业供应链优 化、全球化部署 | |
| 通义千问 2.5-Max | 阿里云 | 多模态生成+数学编程能力,低成本推理,支持视频理解与生成 | 智能制造、电商营销 | |
| 垂直领域模型 | Claude3- Opus | Anthropic | 200k超长上下文处理, 伦理审查模块误判率 <0.1% | 法律合同审查、医疗合规报告 |
| 星火X1 | 科大讯飞 | 基于国产算力平台,中文数学能力国内第一,支持深度推理 | 医疗诊断、教育解题 | |
| 华为云盘古 | 华为 | 中英文理解与多轮对话能力突出,适配复杂工程场景 | 工业质检、能源管理 | |
| 多模态模型 | Sora 2.0 | OpenAI | 扩散模型+Transformer架构,支持物理规律模拟与长视频生成 | 影视制作、广告创意 |
| Runway Gen-4 | Runway | 角色与场景一致性增强, 支持专业镜头语言控制 (如“子弹时间”) | 短视频创作、 动态分镜设计 | |
| Vidu 2.0 | 数生科技 &清华大 学 | 支持立体画面生成,成本低、速度快,风格一致性领先 | 虚拟现实、数字孪生 | |
| 对话应用 | 腾讯元宝 | 腾讯 | 双模型架构(混元 T1+DeepSeek V3),编 程与长文本处理能力提升,集成微信生态 | 企业办公、跨平台任务自动化 |
| 豆包 | 字节跳动 | 用户量突破1亿,支持短视频脚本生成与育儿场景交互 | 娱乐内容创作、家庭教育 | |
| Kimi Chat | 月之暗面 | 支持400万token长文本输入,适配学术研究与复杂文档解析 | 论文研读、法律条文分析 |
关键技术与趋势解析
- 开源生态崛起 DeepSeek-R1等国产开源模型打破技术垄断,支持MIT协议商用,推动中小企业低成本部署。 Meta Llama3、阿里Qwen2-VL等开源框架降低多模态开发门槛,加速行业创新。
- 端侧应用普及 腾讯元宝、豆包等产品通过轻量化模型实现手机端实时交互,日均使用时长超120分钟。 高通骁龙8 Gen4芯片支持千亿参数模型端侧推理,时延<10ms。
- 多模态深度融合 GPT-4o、Gemini 2.0 Pro实现文本/图像/视频跨模态生成,影视行业制作效率提升50%。 华为盘古大模型与优必选合作探索人形机器人交互,推动具身智能落地。
- 垂直场景深耕 医疗领域:星火X1通过FDA认证辅助生成临床试验报告,准确率92%。 工业领域:通义千问2.5-Max优化供应链管理,部署效率提升3倍。
市场格局与用户表现
| 指标 | 领先产品 | 数据表现 |
|---|---|---|
| 用户活跃度 | DeepSeek | 月活1.8亿(国内第一) |
| 豆包 | 日活突破1.01亿,抖音生态协同效应显著 | |
| 商业化能力 | 腾讯元宝 | 企业订阅收入超30亿元,覆盖金融/教育领域 |
| Claude3-Opus | 服务摩根大通、高盛等企业,合同审查效率+40% | |
| 技术评测排名 | Gtp-4o | SuperCLUE总分89.7(全球第一) |
| DeepSeek-R1 | 中文大模型排名第一,推理效率国际领先 |
总结:2025年大模型竞争已从参数规模转向场景渗透力与用户体验。腾讯元宝凭借双模型架构和微信生态整合,成为C端与B端市场的“超级入口”;DeepSeek-R1以开源模式推动技术平权;GPT-4o和Gemini 2.0 Pro则在多模态领域持续领跑。未来竞争将聚焦于行业知识库建设与端云协同算力优化。
1.2 技术储备
学习大模型应该提前要储备哪些知识吗?比如python、机器学习、NLP等? 之前如果有这些基础肯定是更好的。如果没有也没有关系
1.3 大模型分类
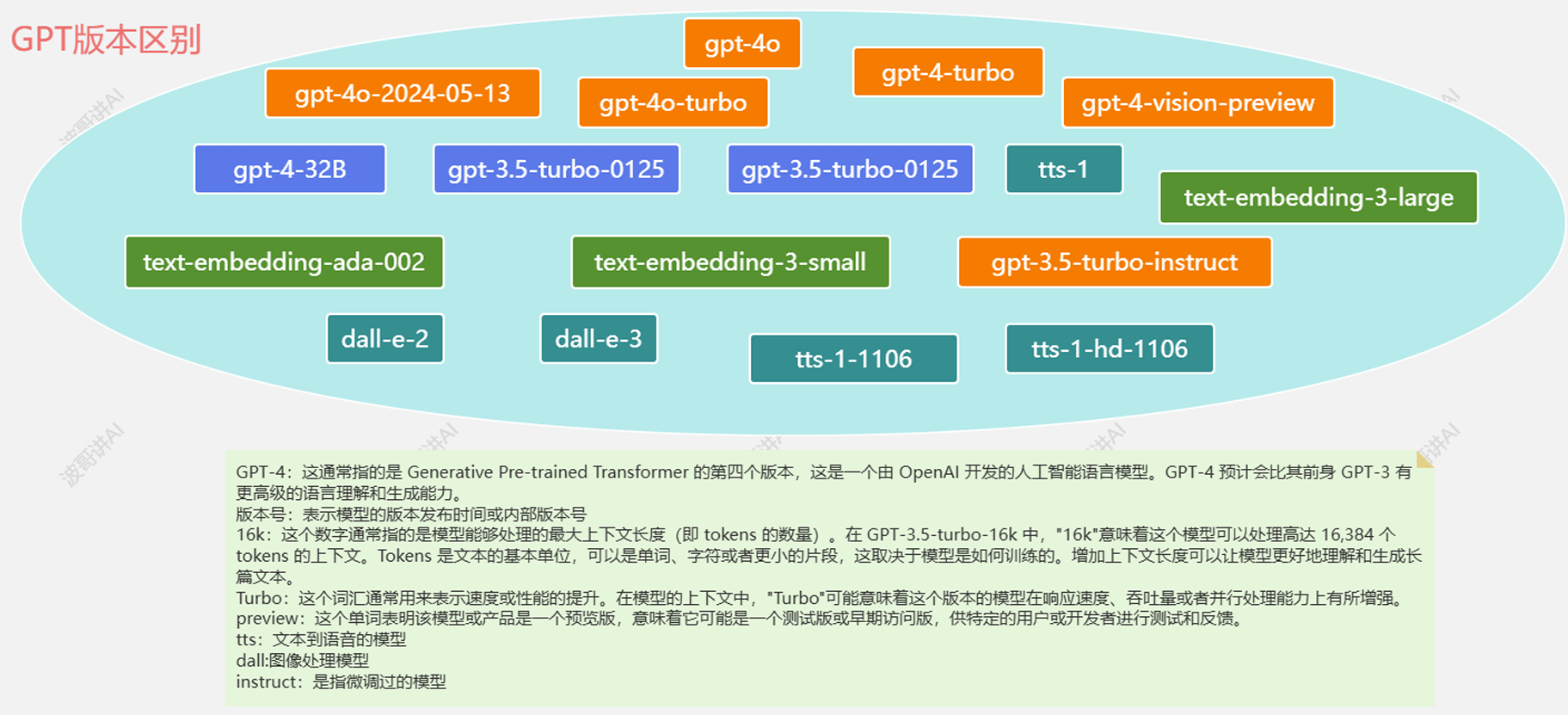
以下是OpenAI主要模型按功能分类的整理表格,综合技术参数、应用场景及发布时间信息:
| 类别 | 名称 | 参数规模/架构 | 核心功能 | 发布时间 | 典型应用场景 |
|---|---|---|---|---|---|
| 语言模型 | GPT-4o | 1.8万亿参数/MoE 架构 | 多模态交互,支持 文本、图像输入,推理速度提升8倍 | 2025.3 | 复杂问题解决、实时交互 |
| GPT-4o-min | 2360亿参数 | 轻量级推理,成本降低至GPT-4o的 1/30,支持本地部署 | 2025.3 | 客服机器人、 批量文本处理 | |
| GPT-3.5 Turbo | 1750亿参数 | 长上下文支持(16K tokens),优化对话流畅度 | 2023 | 日常对话、基 础编程辅助 | |
| 嵌入模型 | text-embedding-3-large | 3072维向量 | 支持语义搜索、文本聚类,支持降维至256维 | 2024.1 | 大规模文档检 索、跨语言匹 配 |
| text-embedding-3-small | 1536维向量 | 性价比高,性能优于前代ada-002 | 2024.1 | 短文本分类、 轻量级推荐系 统 | |
| text-embedding-ada-002 | 1536维向量 | 统一文本与代码嵌入,支持8192 tokens长文本 | 2022.12 | 代码搜索、多任务语义理解 | |
| 图像模型 | DALL·E 3 | 120亿参数/扩散模型 | 根据文本生成4K图像,支持图像编辑与扩展 | 2023.9 | 广告设计、艺术创作 |
| DALL·E 2 | 35亿参数 | 基础图像生成,分辨率较一代提升4倍 | 2022.4 | 快速原型设 计、社交媒体配图 | |
| 语言模型 | GPT-4o-transcribe | 基于GPT-4o架构优化 | 语音转文本,错误率较Whisper降低40%,支持100+语 言 | 2025.3 | 会议记录、多语种客服转录 |
| GPT-4o-mini-transcribe | GPT04o蒸馏版 | 实时转录延迟<200ms,成本降低50% | 2025.3 | 实时字幕生 成、移动端语 音输入 | |
| GPT-4o-mini-tts | 可控语音合成模型 | 支持情感参数调节(如兴奋/平静),音色定制 | 2025.3 | 有声书制作、 个性化语音助 手 | |
| Whisper v3 | 15亿参数(多任务架构) | 多语种语音识别与翻译,支持音频片段分类 | 2024 | 跨境会议翻 译、播客内容分析 |
补充说明
语言模型:GPT-4o系列新增多模态输入能力(如支持图像分析),而GPT-4o-mini专为低成本推理优化。
嵌入模型:text-embedding-3-large通过API支持动态降维,在保持精度的同时减少存储成本。
语音模型:最新发布的GPT-4o系列语音模型集成强化学习,显著降低复杂场景下的转录错误率。
HuggingFace: https://huggingface.co/models
魔塔社区: https://modelscope.cn/models
2 入门案例
可以通过Java代码的方式来实现和大模型的交互,创建一个普通的Maven项目,添加下对应的依赖
1 | |
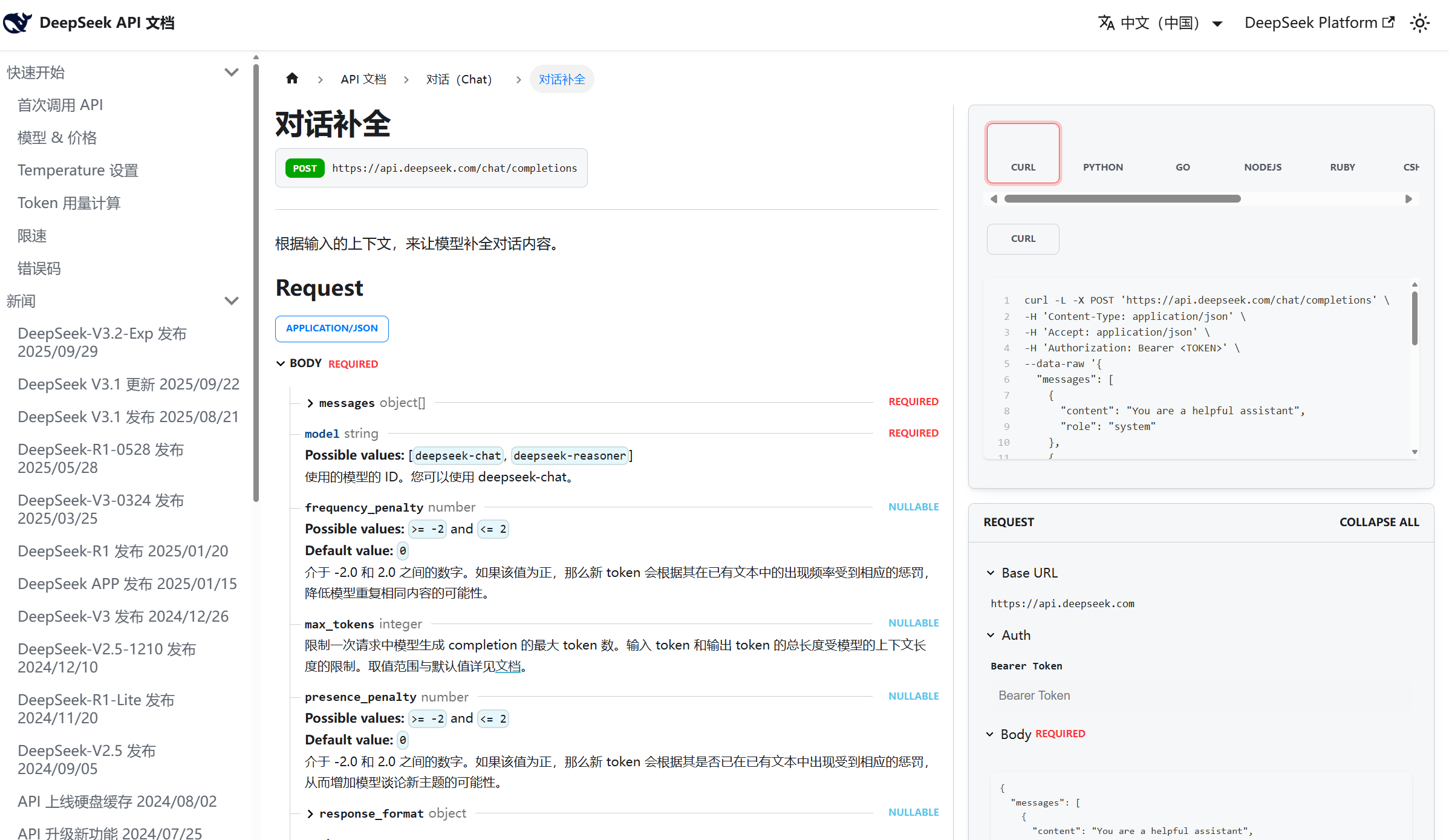
可以先以DeepSeek为例,进入DeepSeek官网,查看对应的API文档:https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
1 | |
输出成功:
1 | |
3 ChatGPT案例
如果想和ChatGPT来交互,这块的实现方式比较多,比如直接去OpenAi的官网申请账号并充值,但是这种方式需要科学上网,也可以通过国内的代理来实现,比如:
https://www.openai-hk.com/docs/getting-started.html
这两个站点的代理都可以,比如通过ddys来测试下:

1 | |
执行后可以看到对应的效果

4 Token的介绍
Token是什么?Token⼀定表示⼀个汉字么?可以在: https://platform.openai.com/tokenizer 这个网站中具体的测试下,比如:”我喜欢⾹蕉”的Token数量。

Token的定义:在大语言模型中,Token是模型进行语言处理的基本信息单元,它可以是⼀个字,⼀个词甚至是⼀个短语句子。Token并不是⼀成不变的,在不同的上下文中,他会有不同的划分粒度。
Token对我们有哪些影响: https://openai.com/api/pricing/
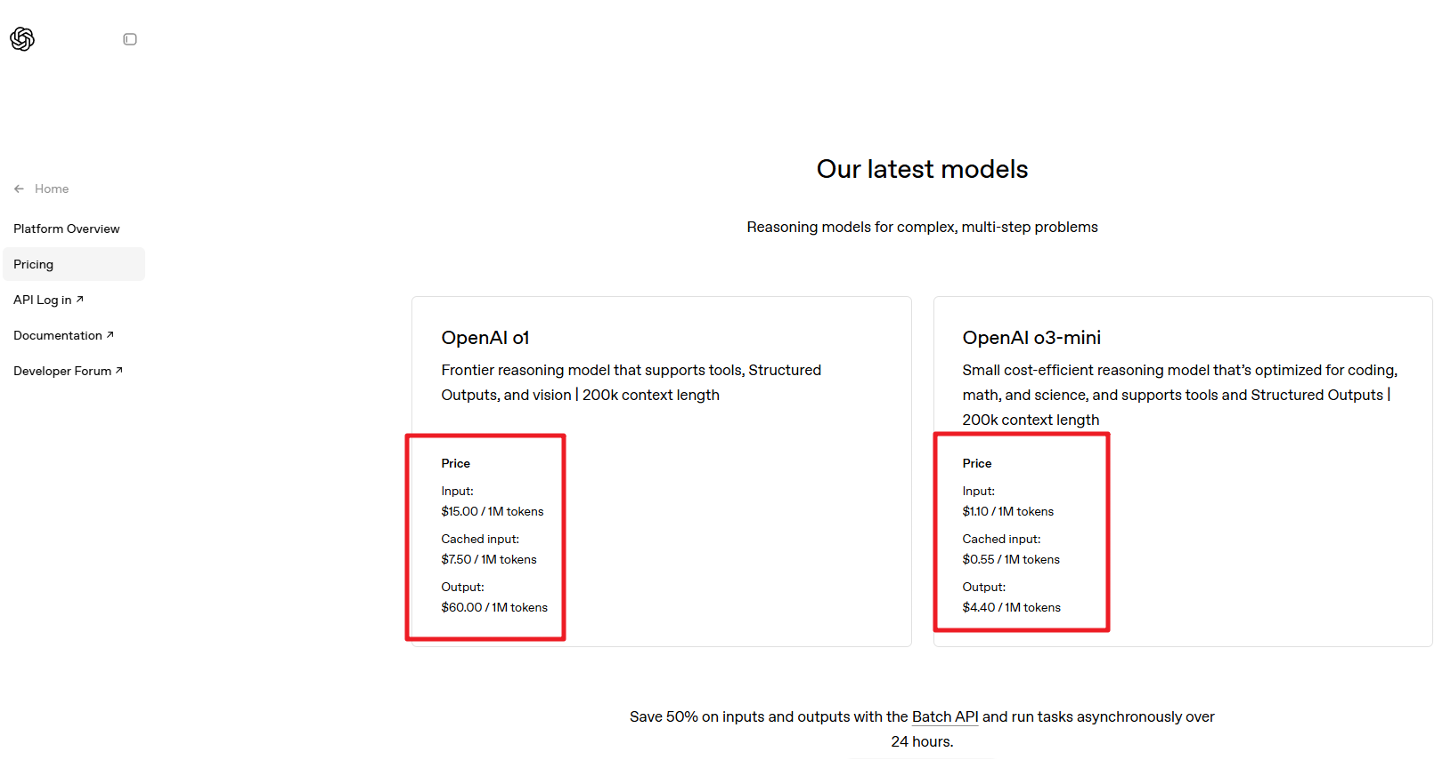
从官方文档中可以看到每个模型都有⼀个MAX TOKENS的参数,这个参数的意思就是在⼀次会话中,模型能基于整个上下文记忆的最大的Token数量,这个上下文既包含了输入,也包含了输出。
在上面这个解释中会有两个概念:
- ⼀次会话:所谓的⼀次会话是指打开了⼀个和ChatGPT的聊天窗口,只要⼀直在这个窗口内和ChatGPT聊天,那么这个窗口就是你和ChatGPT的⼀次会话, 无论你们已经聊了多久
- 上下文:所谓的上下文就是指在最新的⼀个提问之前所有的聊天记录
值得注意的是,这里的上下文记忆的最大Token数量,不仅仅是指你单次提问的语句的最大Token数量,而是整个会话中之前所有的输入和输出的Token数量.