3-MapReduce基础
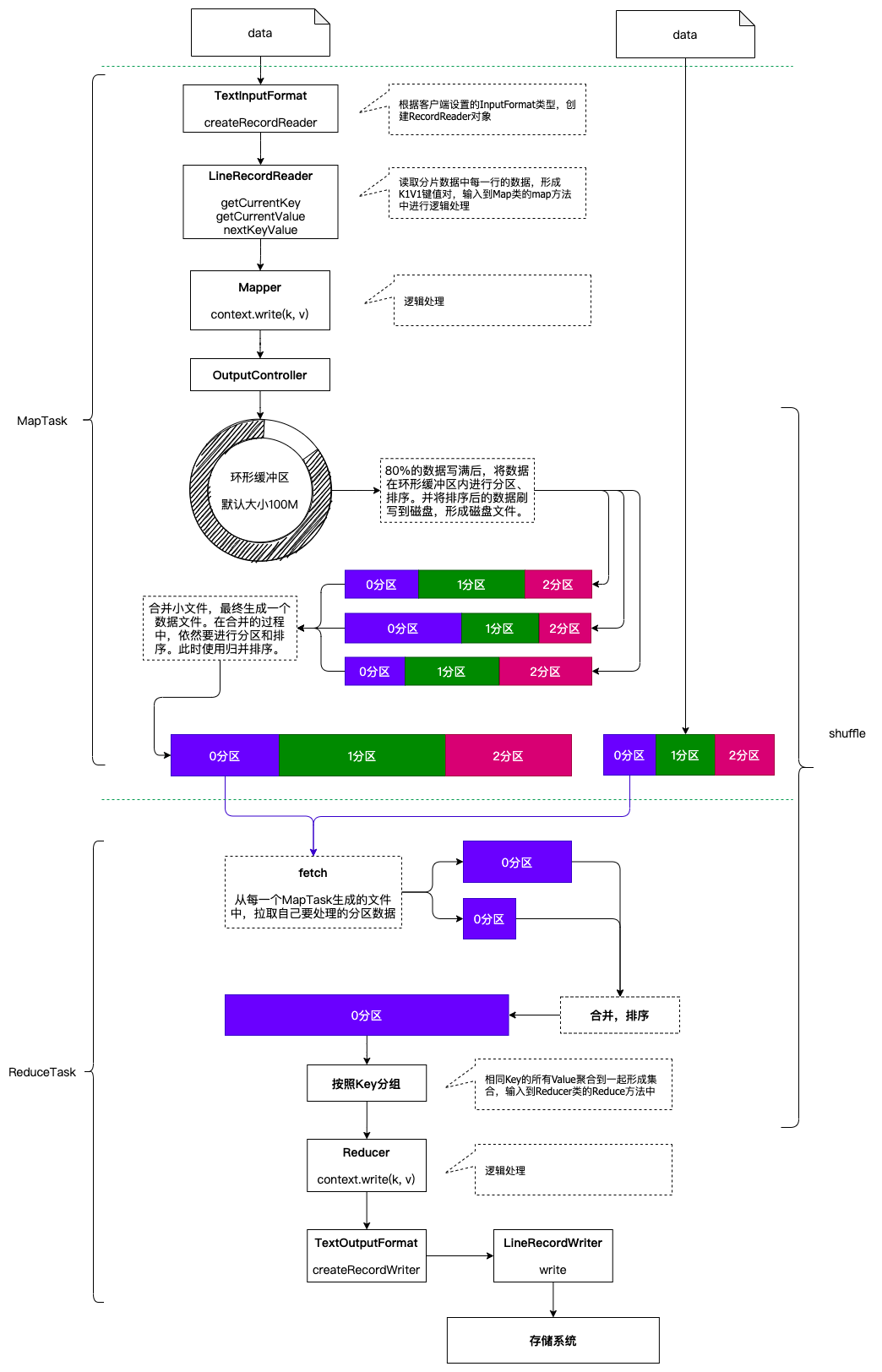
1 MapReduce运行流程概述
一个完整的MapReduce程序在分布式运行时有三类实例进程:
- MRAppMaster: 负责整个程序的过程调度及状态协调
- MapTask: 负责Map阶段的整个数据处理流程
- ReduceTask: 负责Reduce阶段的整个数据处理流程
当一个作业提交后(mr程序启动),大概流程如下:
- 一个mr程序启动的时候,会先启动一个进程Application Master,它的主类是MRAppMaster
- ApplicationMaster启动之后会根据本次job的描述信息,计算出inputSplit的数据,也就是MapTask的数量
- ApplicationMaster然后向ResourceManager来申请对应数量的Container来执行MapTask进程。
- MapTask进程启动之后,根据对应的inputSplit来进行数据处理,处理流程如下
- 利用客户指定的inputformat来获取recordReader读取数据,形成kv键值对。
- 将kv传递给客户定义的Mapper类的map方法,做逻辑运算,并将map方法的输出kv收集到缓存。
- 将缓存中的kv数据按照k分区排序后不断的溢出到磁盘文件
- ApplicationMaster监控mapTask进程完成之后,会根据用户指定的参数来启动相应的reduceTask进程,并告知reduceTask需要处理的数据范围
- ReduceTask启动之后,根据ApplicationMaster告知的待处理的数据位置,从若干的已经存到磁盘的数据中拿到数据,并在本地进行一个归并排序,然后,再按照相同的key的kv为一组,调用客户自定义的reduce方法,并收集输出结果kv,然后按照用户指定的outputFormat将结果存储到外部设备。
2 分片机制
2.1 概念
MapReduce在进行作业提交时,会预先对将要分析的原始数据进行划分处理,形成一个个等长的逻辑数据对象,称之为输入分片(inputSplit),简称“分片”。MapReduce为每一个分片构建一个单独的MapTask,并由该任务来运行用户自定义的map方法,从而处理分片中的每一条记录。
分片是一个逻辑概念,分块是一个物理概念。
HDFS上数据是按照块为单位进行存储的,我们是能够实实在在的看到每一个数据块的。而分片则不然,是一个逻辑概念,用来描述一个MapTask处理的数据是属于哪个文件的,从什么字节位置开始处理,处理多少个字节的数据等等信息。
2.2 分片的大小选择
每一个MapTask处理一个分片的数据,因此分片的数量就决定了MapTask的数量。拥有多个分片,就意味着会有多个MapTask并发执行处理数据集。那么一个MapTask处理多大的数据呢?这也是由分片的大小来决定的。
如果分片设置的太小,那么管理分片的时间和构建MapTask的总时间将在整个作业的时间占比较大,影响程序的执行效率。例如: 一个分片设置为1KB的大小,计算分片、构建MapTask耗时10ms的时间,处理数据耗时10ms的时间,那这样的程序的效率是非常低下的。我们更加乐意让一个任务初始化的时间在整个任务中的时间占比尽可能低。
如果分片设置的太大,那么分片所描述的数据可能会在两个数据块中存储,那就有可能会造成网络IO的产生,需要将数据移动到一个节点上进行处理,效率更低。
因此,最佳分片大小应该和HDFS的块大小一致。
2.3 分片源码解读
2.3.1 FileSplit
1 | |
2.3.2 FileInputFormat
1 | |
2.4 分片总结
- 分片大小参数
通过分析源码,在FileInputFormat中,计算分片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 分片主要由这几个值来运算决定
| 参数 | 默认值 | 属性 |
|---|---|---|
| minSize | 1 | mapreduce.input.fileinputformat.split.minsize |
| maxSize | Long.MAX_VALUE | mapreduce.input.fileinputformat.split.maxsize |
| blockSize | 128M | dfs.blocksize |
通过计算的逻辑分析可以得出,分片大小的计算,是取这三个值的中间值的,因此:
- 如果需要增大分片的大小: 调整minSize大于blockSize即可
- 如果需要减小分片的大小: 调整maxSize小于blockSize即可
分片创建过程总结
1
2
3
4
5
6
71. 获取文件大小及位置
2. 判断文件是否可以分片(压缩格式有的可以进行分片,有的不可以)
3. 获取分片的大小
4. 剩余文件的大小/分片大小>1.1时,循环执行封装分片信息的方法,具体如下:
封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)
5. 剩余文件的大小/分片大小<=1.1且不等于0时,封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理
的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)注意事项: 1.1倍的冗余
一个260M的文件,分几块?分几片?
- 分块是物理概念: 128M + 128M + 4M,因此一共有3个分块。
- 分片是逻辑概念:
- 第一个分片: 260M/128M > 1.1,因此第一个分片大小128M,剩余132M数据未分片。
- 第二个分片: 132M/128M < 1.1,因此第二个分片大小132M
- 因此这个文件有2个分片。
多分片文件读取
数据文件被分了多个分片,那么我们不能保证分片是正好按照行分开的,极大的可能性是一行的数据被分到了两个分片中。因此,我们在进行多个分片的数据读取的时候:
1
2
3- 第一个分片读到末尾再多读一行
- 既不是第一个分片也不是最后一个分片第一行数据舍弃,末尾多读一行
- 最后一个分片舍弃第一行,末尾多读一行
3 运行流程之MapTask
1 | |
MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,MapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
1 | |
4 运行流程之ReduceTask
1 | |
Reduce Task的并行度同样影响整个job的执行并发度和执行效率,但与Map Task的并发数由切片数决定不同,Reduc Task数量的决定是可以直接手动设置:默认值是1,手动设置为4
1 | |
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: Reduce Task数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个Reduce Task。尽量不要运行太多的Reduce Task。对大多数job来说,最好reduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。