1 磁盘监测 在 HDFS 上所有的文件都是以 Block 的形式存在的,如果在 HDFS 上存储了海量的数据文件,就会对应有海量的 Block 的存在,而这些 Block 难免会因为种种原因而存在损坏的情况。有什么办法可以去发现哪些块出现了问题呢?可以使用 fsck 命令。
1.1 fsck的选项
选项
描述
-move
移动损坏的文件到 /lost+found 目录下
-delete
删除损坏的文件
-files
输出正在被检测的文件
-openforwrite
输出检测中的正在被写入的文件
-includeSnapshots
检测的文件包括系统snapShot快照目录下的
-list-corruptfileblocks
输出损坏的块及所属的文件
-blocks
输出block的详细报告
-locations
输出block的位置信息
-racks
输出block的网络拓扑结构
-storagepolicies
输出block的存储策略
-blockId
输出指定blockId所属块的信息
1.2 常见用法
在 HDFS 上创建一个 /test 文件夹,其中上传一个 Hadoop 的安装包文件 hadoop-3.3.1.tar.gz 作为测试数据。
1.2.1 检查文件系统健康状态 hdfs fsck /
这个命令会检查整个文件系统的所有文件的健康状态,正常情况下,最后你会看到 The filesystem under path '/' is HEALTHY
1.2.2 -files -files 选项可以列举出来被检查的文件都有谁,以及健康状态信息,例如:
hdfs fsck /test -files
1 2 /test <dir >
1.2.3 -blocks -blocks 选项可以列举出来被检查的每一个文件的 Block 信息,例如:
hdfs fsck /test -files -blocks
1 2 3 4 5 6 7 /test <dir>3 .3 .1 .tar.gz 605187279 bytes, replicated: replication=3 , 5 block(s): OK0 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742165_1342 len=134217728 Live_repl=3 1 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742166_1343 len=134217728 Live_repl=3 2 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742167_1344 len=134217728 Live_repl=3 3 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742168_1345 len=134217728 Live_repl=3 4 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742169_1346 len=68316367 Live_repl=3
1.2.4 -locations -locations 选项可以列举出来每一个 Block 的位置信息,例如
hdfs fsck /test -files -blocks -locations
1 2 3 4 5 6 7 /test <dir>3 .3 .1 .tar.gz 605187279 bytes, replicated: replication=3 , 5 block(s): OK0 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742165_1342 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103 :9866 ,DS -4d 0d454b-3 cfb-40 fa-ac99-ce085773b234 ,DISK], DatanodeInfoWithStorage[192.168.10.102 :9866 ,DS -bf195ada-1901-4026 -8 e8c-25210 b517040,DISK], DatanodeInfoWithStorage[192.168.10.101 :9866 ,DS -e146d373 -21 ef-4d61-8464 -d02f8c347695 ,DISK]]1 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742166_1343 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.102 :9866 ,DS -bf195ada-1901-4026 -8 e8c-25210 b517040,DISK], DatanodeInfoWithStorage[192.168.10.103 :9866 ,DS -4d 0d454b-3 cfb-40 fa-ac99-ce085773b234 ,DISK], DatanodeInfoWithStorage[192.168.10.101 :9866 ,DS -e146d373 -21 ef-4d61-8464 -d02f8c347695 ,DISK]]2 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742167_1344 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.102 :9866 ,DS -bf195ada-1901-4026 -8 e8c-25210 b517040,DISK], DatanodeInfoWithStorage[192.168.10.103 :9866 ,DS -4d 0d454b-3 cfb-40 fa-ac99-ce085773b234 ,DISK], DatanodeInfoWithStorage[192.168.10.101 :9866 ,DS -e146d373 -21 ef-4d61-8464 -d02f8c347695 ,DISK]]3 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742168_1345 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103 :9866 ,DS -4d 0d454b-3 cfb-40 fa-ac99-ce085773b234 ,DISK], DatanodeInfoWithStorage[192.168.10.101 :9866 ,DS -e146d373 -21 ef-4d61-8464 -d02f8c347695 ,DISK], DatanodeInfoWithStorage[192.168.10.102 :9866 ,DS -bf195ada-1901-4026 -8 e8c-25210 b517040,DISK]]4 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742169_1346 len=68316367 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.102 :9866 ,DS -bf195ada-1901-4026 -8 e8c-25210 b517040,DISK], DatanodeInfoWithStorage[192.168.10.103 :9866 ,DS -4d 0d454b-3 cfb-40 fa-ac99-ce085773b234 ,DISK], DatanodeInfoWithStorage[192.168.10.101 :9866 ,DS -e146d373 -21 ef-4d61-8464 -d02f8c347695 ,DISK]]
1.2.5 -list-corruptfileblocks -list-corruptfileblocks 选项可以列举出来损坏的 block 的信息,例如
hdfs fsck /test -list-corruptfileblocks
1 The file system under path '/test' has 0 CORRUPT files
1.3 场景模拟 1.3.1 模拟数据顺坏 通过 hdfs fsck /test -files -blocks 可以查看到文件的块信息如下
1 2 3 4 5 6 7 /test <dir>3 .3 .1 .tar.gz 605187279 bytes, replicated: replication=3 , 5 block(s): OK0 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742165_1342 len=134217728 Live_repl=3 1 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742166_1343 len=134217728 Live_repl=3 2 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742167_1344 len=134217728 Live_repl=3 3 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742168_1345 len=134217728 Live_repl=3 4 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742169_1346 len=68316367 Live_repl=3
可以直接到三个节点的存放块的文件夹下,使用rm命令删除数据块,来模拟块损坏的问题。
1 rm -f blk_1073742169_1346.meta blk_1073742169
当数据丢失以后,NameNode 需要等待 6 个小时,或者重启之后才会知道数据丢失。直接重启集群。
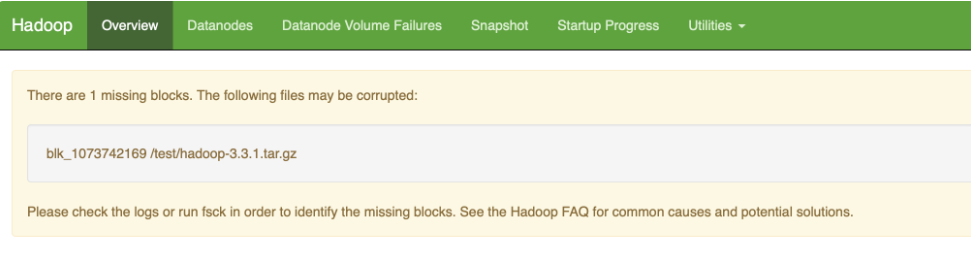
1.3.2 监测损坏 重启之后,在 WebUI 上会有警告信息,来提示我们数据有损坏。
也可以通过 hdfs fsck / 来查看到有数据损坏的情况出现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 /test/hadoop-3.3.1.tar.gz: MISSING 1 blocks of total size 68316367 B. Status: CORRUPT Number of data-nodes: 3 Number of racks: 1 Total dirs: 41 Total symlinks: 0 Replicated Blocks: Total size: 1153777167 B (Total open files size: 58 B) Total files: 70 (Files currently being written: 1 ) Total blocks (validated): 76 (avg. block size 15181278 B) (Total open file blocks (not validated): 1 ) ******************************** UNDER MIN REPL'D BLOCKS: 1 (1.3157895 %) MINIMAL BLOCK REPLICATION: 1 CORRUPT FILES: 1 MISSING BLOCKS: 1 MISSING SIZE: 68316367 B ******************************** Minimally replicated blocks: 75 (98.68421 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 2.9605262 Missing blocks: 1 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Blocks queued for replication: 0
使用 hdfs fsck /test -files -blocks 查看到更加细致的块丢失的信息
1 2 3 4 5 6 7 /test <dir>3 .3 .1 .tar.gz 605187279 bytes, replicated: replication=3 , 5 block(s): MISSING 1 blocks of total size 68316367 B0 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742165_1342 len=134217728 Live_repl=3 1 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742166_1343 len=134217728 Live_repl=3 2 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742167_1344 len=134217728 Live_repl=3 3 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742168_1345 len=134217728 Live_repl=3 4 . BP-1433066220-192 .168.10.101 -1675649203021 :blk_1073742169_1346 len=68316367 MISSING!
1.3.3 损坏文件删除 使用 hdfs fsck /test -move 将损坏的文件移动到 /lost+found 目录
使用 hdfs fsck /test -delete 将损坏的文件删除
2 动态上线 HDFS支持在廉价硬件上部署分布式文件系统,来存储海量的数据,并且支持扩容。如果已有 HDFS 的集群容量已经不能满足存储数据的需求,此时可以在原有集群的基础上动态添加新的 DataNode 节点,来实现对集群的动态扩容。
2.1 集群规模规划 扩容之前的集群如下:
IP 地址
hostname
角色进程
192.168.10.101
qianfeng01
NameNode、DataNode
192.168.10.102
qianfeng02
SecondaryNameNode、DataNode
192.168.10.103
qianfeng03
DataNode
扩容之后的集群如下:
IP 地址
hostname
角色进程
192.168.10.101
qianfeng01
NameNode、DataNode
192.168.10.102
qianfeng02
SecondaryNameNode、DataNode
192.168.10.103
qianfeng03
DataNode
192.168.10.104
qianfeng04
DataNode
2.2 动态上线过程
准备一台新的虚拟机,准备如下工作:
1 2 3 4 5 6 1 、设置 IP 地址为 192 .168 .10 .104 2 、设置 hostname 为 qianfeng043 、设置防火墙关闭4 、设置时间同步5 、安装 JDK 并设置 JDK 的环境变量(可以直接从已有节点拷贝)6 、安装好 Hadoop 并设置 Hadoop 的环境变量
在qianfeng01节点进行修改操作,添加对qianfeng04的host映射,并同步给每一个节点
1 2 3 4 5 6 7 # 编辑 qianfeng01 节点上的 /etc/hosts 文件,添加映射 # 分发给其他的节点
设置qianfeng01到qianfeng04节点的免密登录
1 2 # 将 qianfeng01 节点生成的公钥拷贝到 qianfeng04 节点
修改 qianfeng01 节点上的 Hadoop 配置文件中的 workers 文件,添加 qianfeng04
1 2 3 4 # 编辑 workers 文件 # 添加qianfeng04
将编辑之后的 workers 文件分发到 qianfeng02 和 qianfeng03 节点
1 2 3 cd /usr/local/hadoop-3.3.1/etc/hadoop
将 qianfeng01 节点的 Hadoop 的配置文件直接拷贝到 qianfeng04 节点
1 2 cd /usr/local/hadoop-3.3.1/
在 qianfeng04 节点启动 DataNode
1 hdfs --daemon start datanode
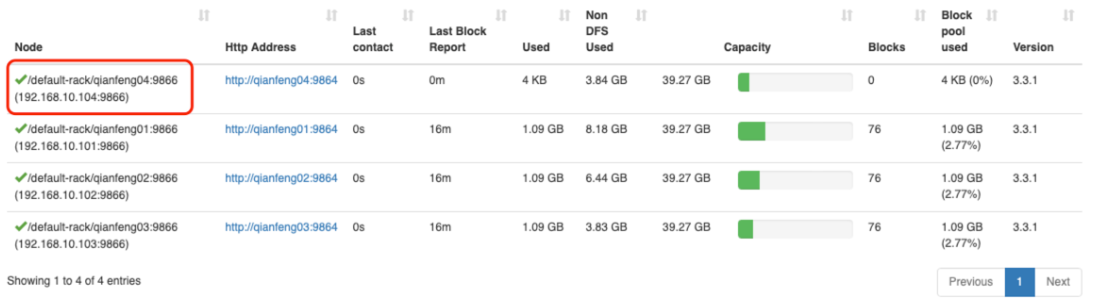
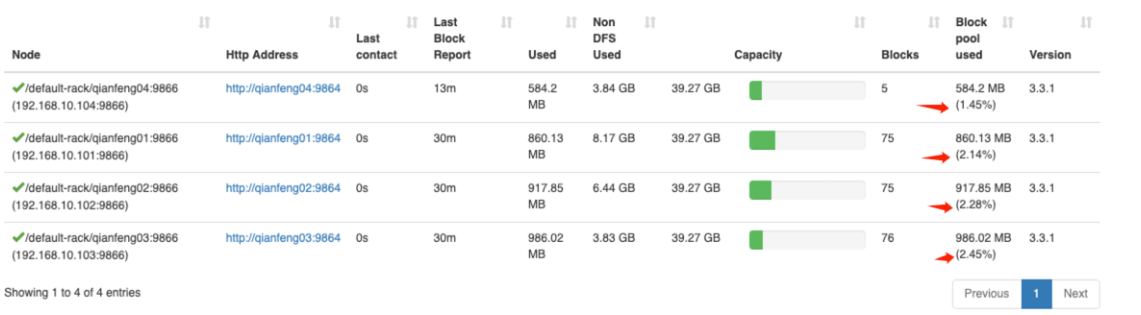
打开 WebUI 查看 DataNodes,发现 qianfeng04 节点已经上线!
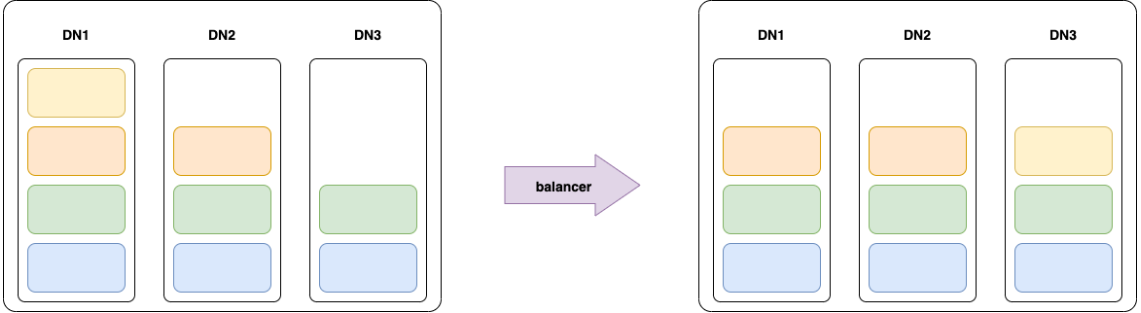
2.3 数据平衡 虽然现在已经上线了 qianfeng04 节点,但是这个新的节点上没有数据存储。可以在 WebUI 的 DataNodes 界面查看到这个新的节点上的 Blocks 的数量为 0,这样就使得集群的负载不均衡。因此需要对 HDFS 进行节点之间的数据均衡。
通过 balancer 可以实现这个效果! 在主节点 qianfeng01 上执行 balancer 命令,实现均衡不同的 DataNodes 之间的负载。
使用 balancer 的时候需要设置 threshold 参数,表示均衡的阈值。默认的阈值是 10,表示 10% 的阈值。那么这个阈值有什么用呢?它表示 balancer 在进行数据均衡的时候,将保证每个 DataNode 上的磁盘使用量与集群的总体使用量的差值不超过这个阈值。
例如:将阈值设置为 10%,
那么在做数据平衡的时候,如果集群中所有的 DataNode 节点总的使用占全部磁盘的 40%,那么就确保每一个 DataNode 的磁盘使用率在 30% 到 40% 之间。
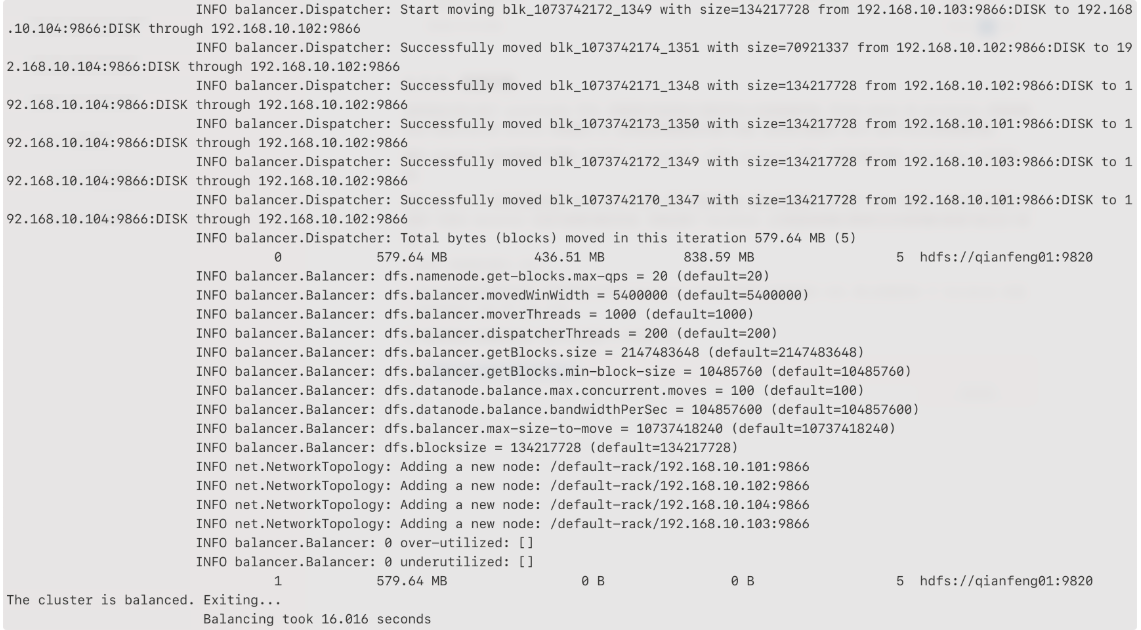
为了能够更加方便看到效果,使用 1 来设置平衡:
1 hdfs balancer -threshold 1
平衡之后的结果,可以在 WebUI 上查看到
3 动态下线 集群在使用的过程中,可能会遇到旧的服务器需要进行升级、更换的操作。HDFS 是支持动态的下线节点的,不需要停止 HDFS 的服务,即可动态的将某个节点下线。升级或者更换完成之后,再使用上述章节中的动态上线的技术重新上线即可。
3.1 集群规模规划 扩容之前的集群如下:
IP 地址
hostname
角色进程
192.168.10.101
qianfeng01
NameNode、DataNode
192.168.10.102
qianfeng02
SecondaryNameNode、DataNode
192.168.10.103
qianfeng03
DataNode
192.168.10.104
qianfeng04
DataNode
扩容之后的集群如下:
IP 地址
hostname
角色进程
192.168.10.101
qianfeng01
NameNode、DataNode
192.168.10.102
qianfeng02
SecondaryNameNode、DataNode
192.168.10.103
qianfeng03
DataNode
3.2 节点动态下线 3.2.1 准备工作 节点的动态下线比起动态上线来说,稍微麻烦一些。因为动态下线的时候需要提前将数据移动到其他节点才可以。Hadoop 虽然提供了动态下线的功能,但是有一个前提条件就是需要再在 hdfs-site.xml 文件中配置属性: dfs.hosts.exclude 。这个属性的值需要指向一个文件,也就是需要下线的文件。也就是一个黑名单,在这个文件中的机器,会被 NameNode 移除集群。
但是这个hdfs-site.xml文件修改之后是需要重启集群才生效的。因此在生产环境中,我们需要提前将这个属性配置好,因为生产环境中的集群是不允许随意的关闭、重启的。我们直接修改这个文件,然后重启集群即可。
修改 qianfeng01 节点的 hdfs-site.xml 文件
1 2 3 4 <property > <name > dfs.hosts.exclude</name > <value > /usr/local/hadoop-3.3.1/etc/hadoop/exclude</value > </property >
创建这个 exclude 文件
1 2 # 这个文件是一个黑名单文件,为了操作起来方便、合理,我们将它放在 Hadoop 的配置文件目录中
重启HDFS集群
1 2 stop-dfs.sh
3.2.2 动态下线过程
将需要下线的节点,添加到exclude 文件中
1 echo "qianfeng04" > /usr/local/hadoop-3.3.1/etc/hadoop/exclude
注意事项: 下线之后的节点数量,不能少于副本数量。例如副本因子为 3,在线的节点数量是小于等于 3 的,此时是无法下线的。如果需要下线的话,需要修改副本数之后再下线。
刷新节点(需要在 NameNode 节点操作)
1 hdfs dfsadmin -refreshNodes
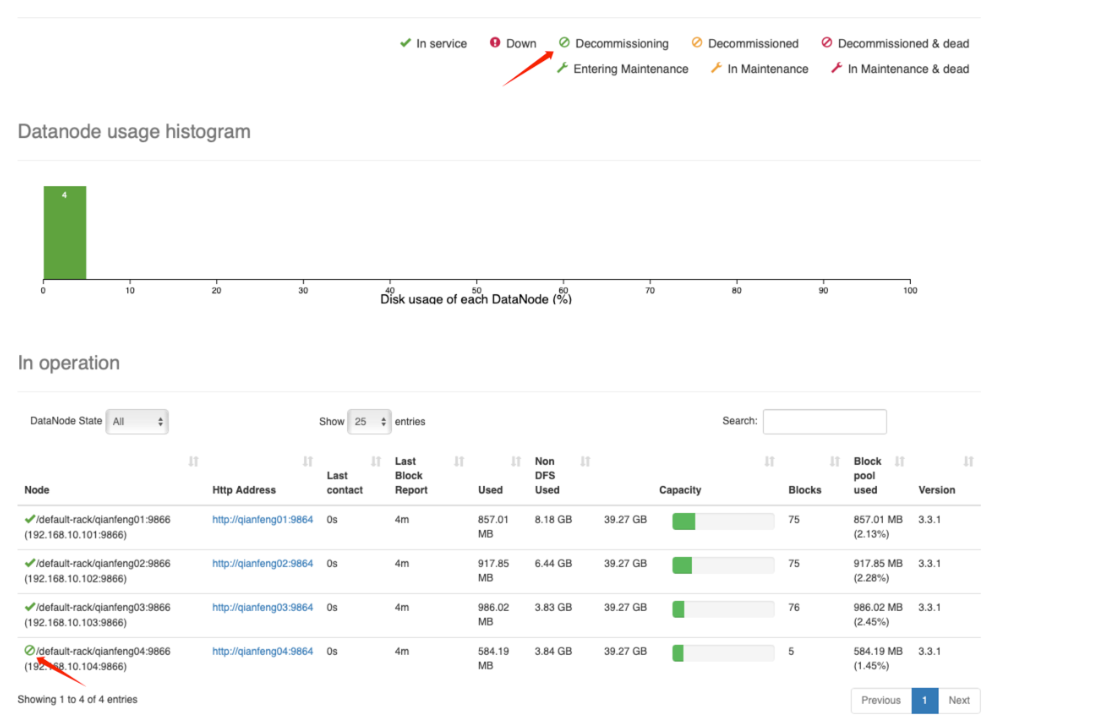
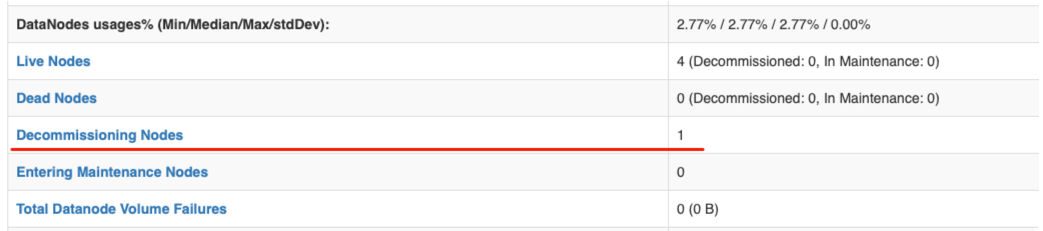
在 WebUI 查看节点状态
这里的 Decommissioning 表示正在“退役中”,此时会将这个节点上面的数据块拷贝到其他的节点。
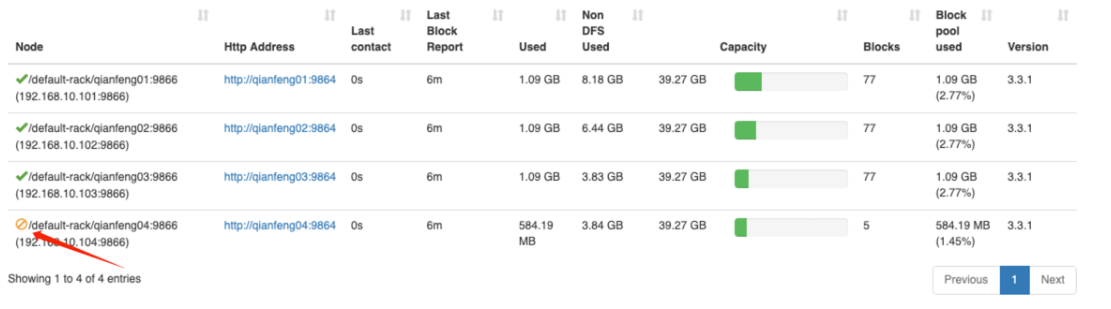
等待一会,即可完成退役。
退役完成,可以停止 qianfeng04 节点上的服务
1 hdfs --daemon stop datanode
其他的节点的数据如果不均衡的话,使用 balancer 命令平衡一下即可
注:
如果这个节点下线之后,从此就不再使用了。我们可以修改 workers 文件,从中删除掉这个节点。再修改 exclude 文件,将其从中删除即可。
4 磁盘平衡 HDFS 提供了一个balancer 命令,可以实现 DataNode 之间的负载均衡。但是一个 DataNode 节点上可能存在多个磁盘,而 balancer 是无法实现单个节点上的磁盘之间的均衡的。
在 HDFS 中,DataNode 是真正负责数据块的存储的,最终将数据以 Block 的形式存储在机器的磁盘上。在写入新的 Block 的时候,DataNode 将根据指定的策略,选择将数据块存储在什么磁盘上:
循环策略 round-robin: 这种策略会将新的 Block 均匀的分布在可用磁盘上。默认使用这个策略。可用空间策略 avaliable space: 这种策略会将新的 Block 会按照磁盘占用百分比,写入具有更多可用空间的磁盘上。
如果在长期运行的集群中采用默认的循环策略,可能会出现由于大量的删除操作,或者更换磁盘,而导致数据不均匀的填充在磁盘上。而使用可用空间策略的话,新增的数据块都会往新的磁盘上写,在此期间,其他的磁盘都处于空闲状态。那么这个新的磁盘将会是整个 HDFS 的瓶颈。
在 Hadoop3 中新增了一个 Disk Balancer 的工具,这个工具就是用来平衡 DataNode 中的数据在不同磁盘之间分布的。
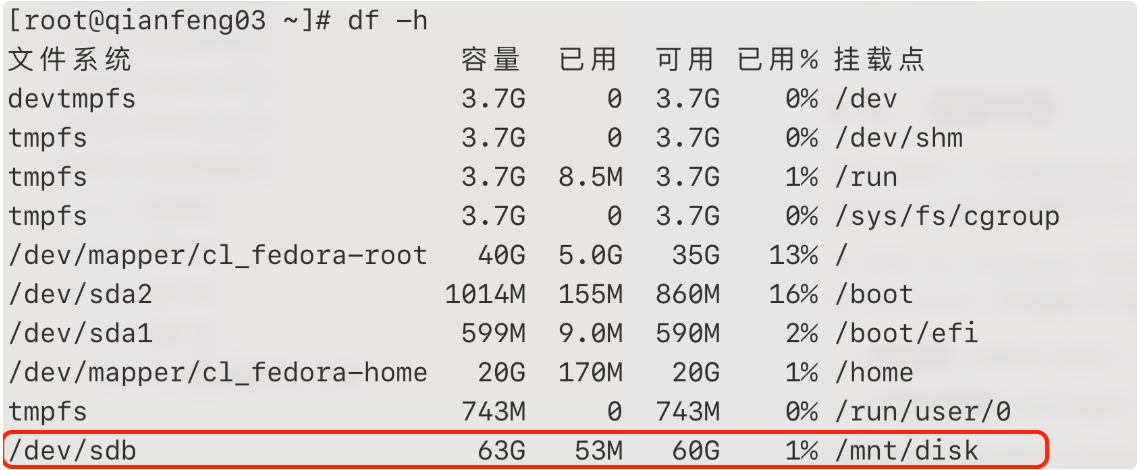
前提1: 以 qianfeng03 节点挂载一块新的硬盘为例,现在已经在 qianfeng03 节点挂载了一块新的硬盘,并将其挂载在 /mnt/disk 目录。
前提2: 修改 qianfeng03 节点的 DataNode 数据保存的目录,添加上这个新的磁盘。
1 2 3 4 5 <property > <name > dfs.datanode.data.dir</name > <value > file://${hadoop.tmp.dir}/dfs/data,/mnt/disk2/hadoop/dfs/data</value > </property >
在 qianfeng03 节点上,现在有两块硬盘,并且两块磁盘的数据并不均衡。此时可以使用磁盘平衡工具,来平衡两块磁盘。磁盘平衡工具 diskbalancer 在使用的时候分为 3 步:
生成平衡计划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 平衡的时候,默认的阈值是10%,表示平衡之后的磁盘间的数据使用占比差值不会超过10% # 这个阈值可以使用 -thresholdPercentage 来设置 # 可以从输出的日志中,看到生成了磁盘平衡计划,以 JSON 的形式保存在了 HDFS 的指定目录下
执行平衡操作
1 2 # 在需要平衡磁盘的节点上执行
查看平衡结果
1 2 3 4 5 6 7 8 9 10 11 12 13 /system/ diskbalancer/XXX/ qianfeng03.plan.json63 d55420750b6657e608a67db7571ad171dfd5d8/system/ diskbalancer/XXX/ qianfeng03.plan.json63 d55420750b6657e608a67db7571ad171dfd5d8
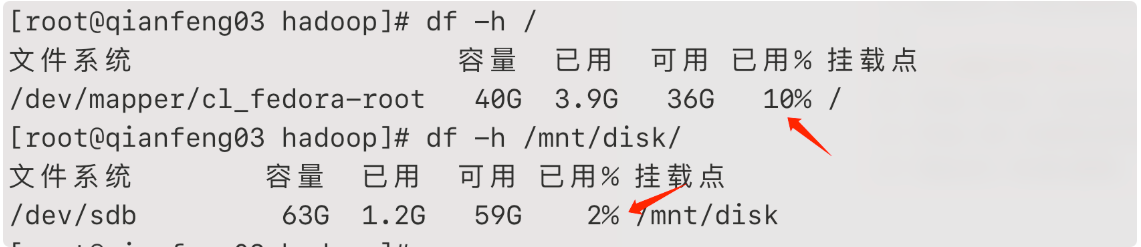
磁盘平衡结束后,我们可以使用 df -h 来查看各个磁盘的使用情况:
会发现两者之间被平衡到了 10% 的阈值以内,这个也是默认的阈值。磁盘平衡完成!
5 分布式拷贝 5.1 distcp的介绍 distcp 其实是两个单词的缩写拼接而成的:Distributed Copy,即分布式拷贝 。可以实现将一个分布式集群的数据拷贝到另外的一个分布式集群!distcp 命令的拷贝过程本质依然是 MapReduce 的任务,使用 MapReduce 实现文件分发、错误处理和恢复、报告生成。以文件或目录的列表作为 MapTask 的输入,每个 MapTask 都会拷贝原文件列表中指定路径下的文件。
应用场景: 数据迁移、异地容灾等。
使用 distcp 命令做分布式拷贝有如下优点:
可以使用 bandwidth 参数为每一个 MapTask 限流,控制 MapTask 并发数量以控制整个拷贝任务的带宽。防止出现拷贝任务将带宽占满,影响其他的业务。
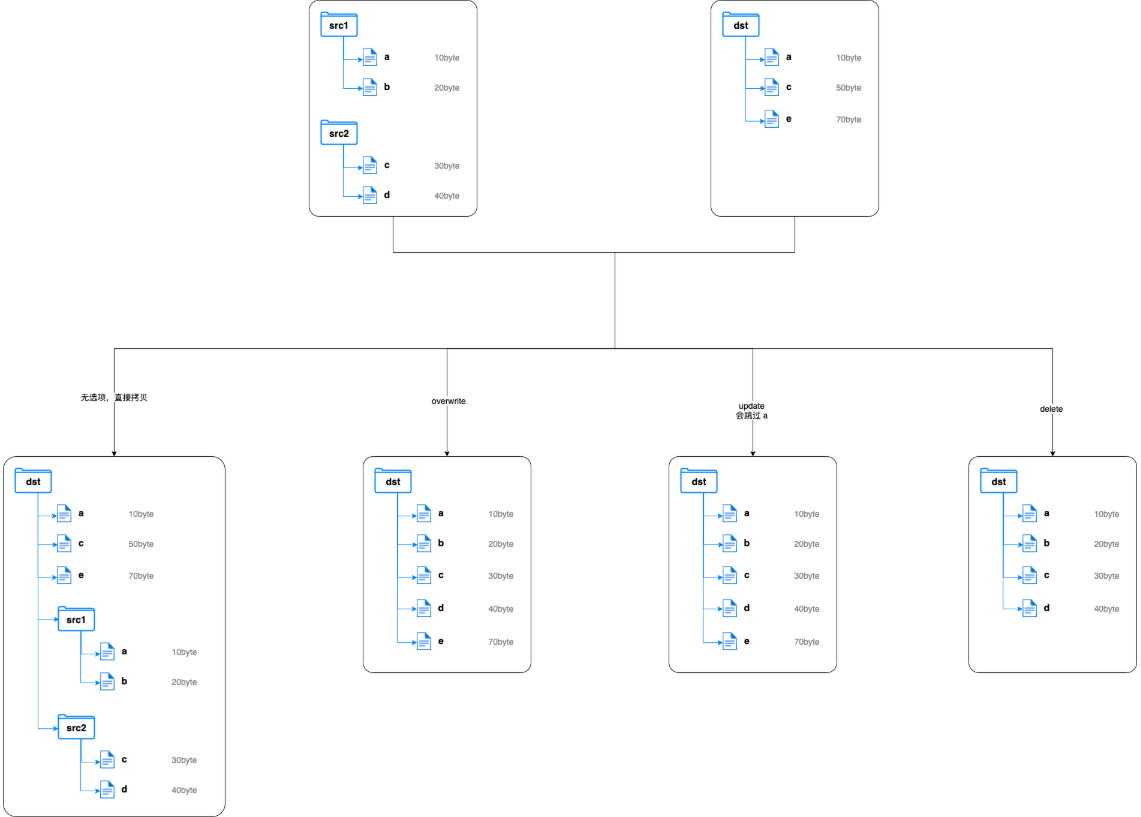
支持多种拷贝模式:
overwrite: 覆盖写,无条件覆盖目标文件
update: 增量写,如果目标文件的名称和大小与源文件不同,则覆盖;如果目标文件的名称和大小与源文件相同,则跳过
delete: 删除写,删除目标路径存在而原路径中不存在的文件。
5.2 distcp的使用 5.2.1 基础使用 在拷贝的时候,也可以指定多个源路径
1 hadoop distcp hdfs://namenode01:9820/src hdfs://namenode02:9820/dst
5.2.2 多数据源目录 在拷贝的时候,也可以指定多个源路径
1 hadoop distcp hdfs://namenode01:9820/src1 hdfs://namenode01:9820/src2 hdfs://namenode02:9820/dst
如果需要拷贝的源路径比较多,不方便直接写到命令中的,也可以将其做成文件
1 2 3 4 5 6 7 8 # 1. 在 HDFS 上创建一个文件,用来存储源路径 # 例如在 hdfs://namenode01:9820/distcp/src 文件中书写 # 2. 执行拷贝操作
5.2.3 常用选项
选项
描述
备注
-i
忽略错误
-log <logdir>
生成日志到logdir目录中
这里其实就是 MapTask 的输出
-m <num_maps>
最大同时拷贝的数量
可以确定 MapTask 的数量
-bandwidth
为每个 MapTask 设置带宽,单位是MB/s
-overwrite
覆盖目标路径
会改变源目录复制到目标目录的路径
-update
跳过目标路径下的同名、同大小的文件
会改变源目录复制到目标目录的路径
-delete
删除目标路径存在、源路径不存在的文件
6 归档 6.1 archives命令介绍 HDFS 在使用的时候有一个缺点:不适合小文件存储。因为每一个小文件都会占用一个块来存储,而每一个块也都会有固定大小的元数据需要保存在 NameNode 的内存中。如果 HDFS 中有大量的小文件的话,会带来非常大的内存开销。此时就可以使用 archives 来处理这个问题。
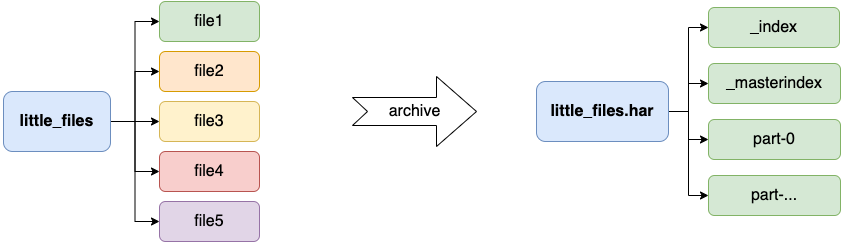
archives 就是归档的意思,它可以将 HDFS 的多个文件归档成为一个扩展名为.har的文件,而且归档之后的文件还可以透明的访问每一个文件,并且可以作为 MapReduce 任务的输入。
6.2 创建归档 6.2.1 创建归档语法 归档的用法: hadoop archive -archiveName name -p <parent> [-r <replication factor>] <src>* <dest>
-archiveName: 指定归档后文件的名称,需要以.har结尾
-p: 指定需要归档的文件的父级路径
-r: 指定归档文件的副本因子,默认是 3
<src>: 指定所有需要归档的文件
<dest>: 指定归档后的文件存放的位置
6.2.2 创建归档操作 1 2 3 4 5 # 1. 准备工作:在 HDFS 的 /little_files 目录下,上传了若干小文件 file1、file2、file3、file4、file5 # 2. 将file1、file2归档到一起,归档文件存放于 /archives # 3. 如果需要将某个文件夹下的所有文件都进行归档,可以直接这样做
创建归档的时候,会生成一个 MapReduce 的任务,如果已经设置了 YARN 调度,需要保证 YARN 是启动的状态。最终会在目标路径下生成归档文件。
归档文件在 HDFS 的体现形式其实是一个文件夹,其中包含了元数据信息(_index, _masterindex)和数据文件(part_xxx)
注意:创建归档之后,原来的小文件不会被删除!
6.3 查看归档 如果要查看某一个归档文件中都有什么文件,需要通过特定的 URI 进行查看。在 HDFS 中,归档文件默认使用的是 har://
1 2 3 4 5 6 [root@qianfeng01 ~]# hdfs dfs -ls -R har:///archive/files.har
6.4 解归档 归档文件在 HDFS 的映射是一个文件夹,可以透明的访问其中的文件。因此如果我们需要将归档文件中的小文件解出来的话,直接进行拷贝即可。但是需要注意归档文件的 URI 是 har://
1 2 3 4 5 6 7 8 # 1. 在 HDFS 上创建一个文件夹,用来接收解归档之后的文件 # 2. 拷贝归档中的文件到指定目录 # 3. 也可以使用分布式拷贝命令实现拷贝
6.5 归档特性总结
归档文件本身不支持压缩
创建归档的时候使用到的小文件和目录都不会自动删除,如果需要删除,需要手动删除
归档文件是不可变的,如果想要在归档文件中新增小文件或者删除小文件,需要重新创建归档文件
归档文件只是用来减少小文件带来的 NameNode 过高的内存占用,对于 MapReduce 来说没有优化。并不会减少分片的数量,也就无法减少 MapTask 的数量。