5-数据流
1 读流程的详解
1 | |
详细图解
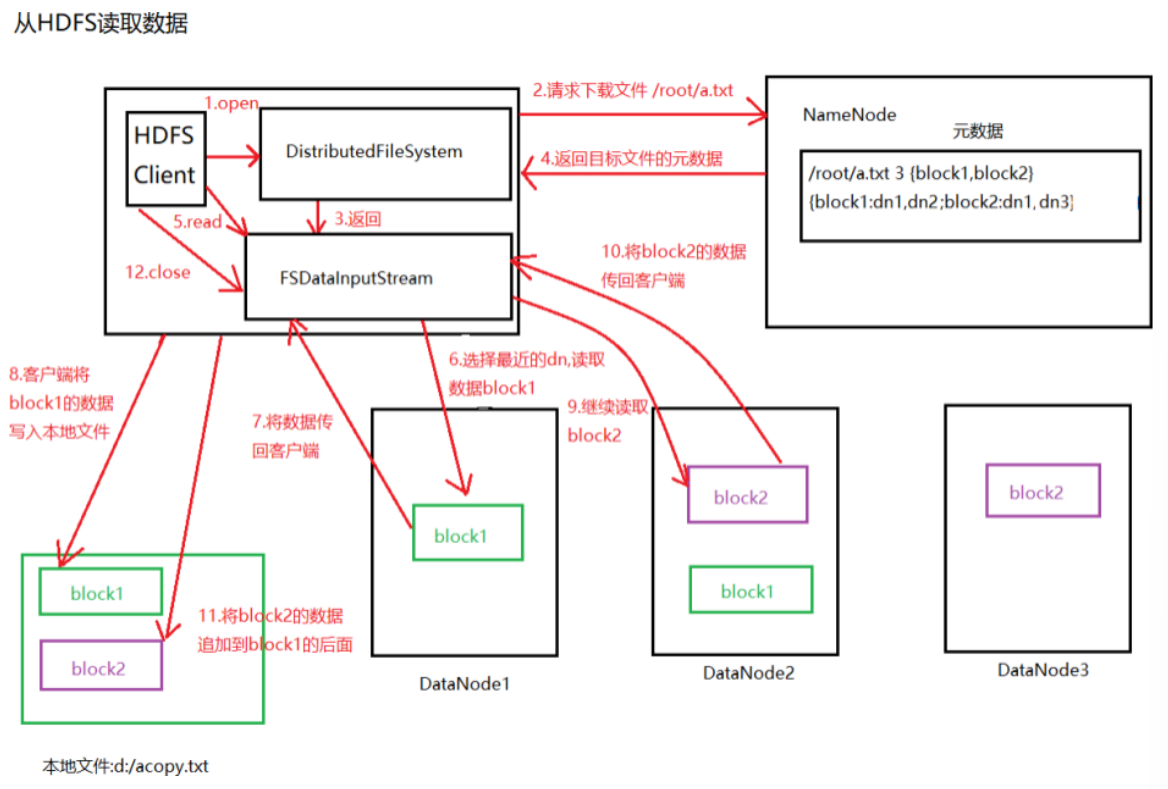
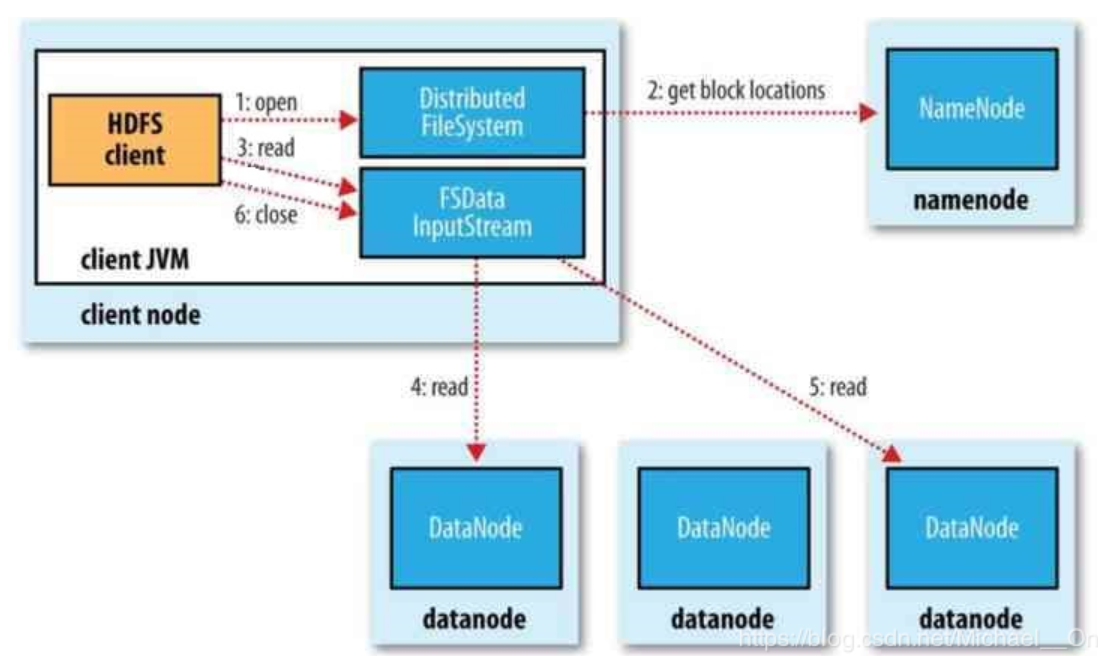
客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是DistributedFileSystem,它通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置
对于每一个块,NameNode返回存有该块副本的DataNode地址,并根据距离客户端的远近来排序。
DistributedFileSystem实例会返回一个FSDataInputStream对象(支持文件定位功能)给客户端以便读取数据,接着客户端对这个输入流调用read()方法
FSDataInputStream随即连接距离最近的文件中第一个块所在的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端
当读取到块的末端时,FSInputStream关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode
客户端从流中读取数据时,块是按照打开FSInputStream与DataNode的新建连接的顺序读取的。它也会根据需要询问NameNode来检索下一批数据块的DataNode的位置。一旦客户端完成读取,就对FSInputStream调用close方法
注意:在读取数据的时候,如果FSInputStream与DataNode通信时遇到错误,会尝试从这个块的最近的DataNode读取数据,并且记住那个故障的DataNode,保证后续不会反复读取该节点上后续的块。FInputStream也会通过校s验和确认从DataNode发来的数据是否完整。如果发现有损坏的块,FSInputStream会从其他的块读取副本,并且将损坏的块通知给NameNode
2 写流程的详解
1 | |
详细图解
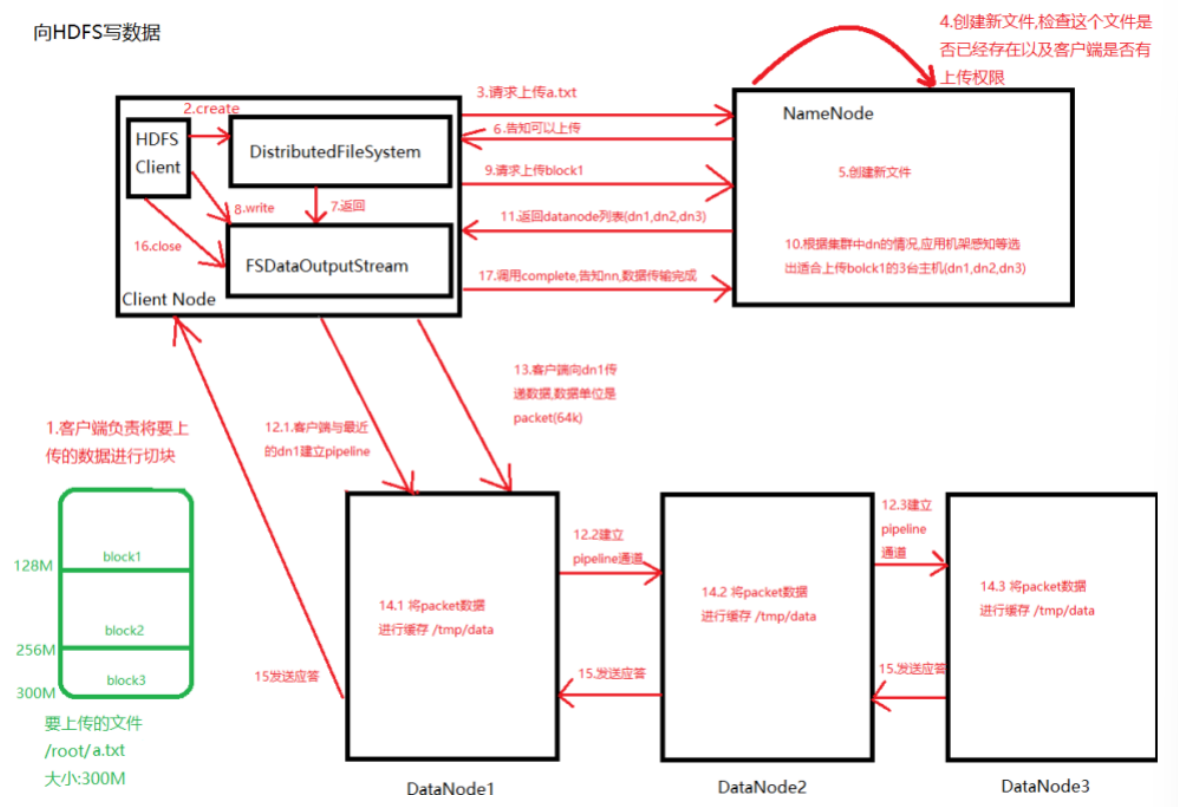
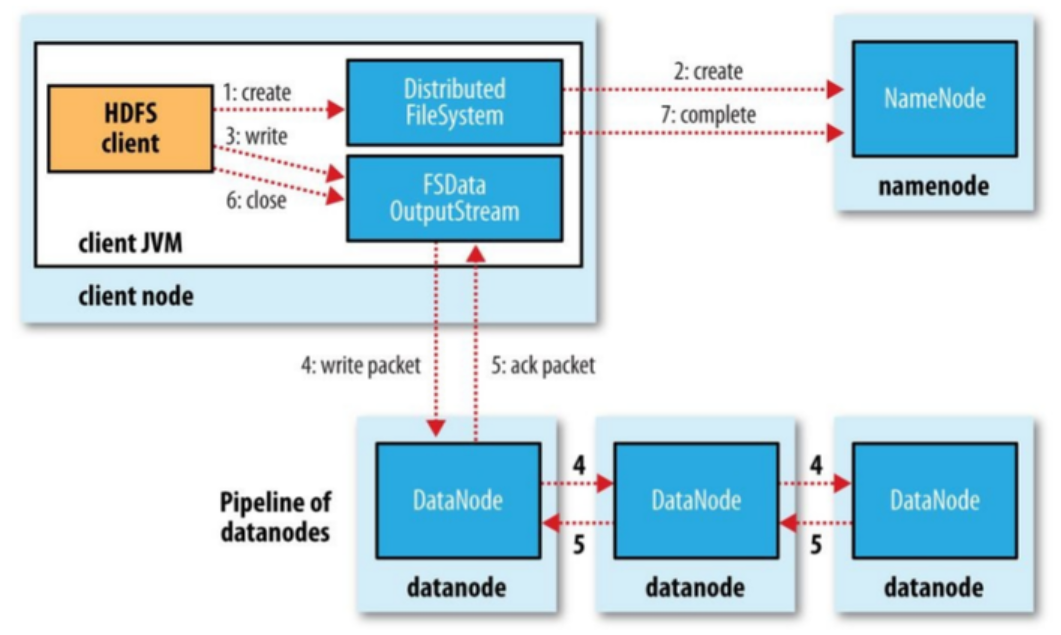
图中的1和2. 客户端(操作者)通过调用DistributedFileSystem对象的create()方法(内部会调用HDFSClient对象的
create()方法),实现在namenode上创建新的文件并返回一个FSDataOutputStream对象
- DistributedFileSystem要通过RPC调用namenode去创建一个没有blocks关联的新文件,此时该文件中还没有相应的数据块信息
- 但是在新文件创建之前,namenode执行各种不同的检查,以确保这个文件不存在以及客户端有新建该文件的权限。如果检查通过,namenode就会为创建新文件记录一条事务记录(否则,文件创建失败并向客户端抛出一个IOException异常)。DistributedFileSystem向客户端返回一个FSDataOuputStream对象
- FSDataOutputStream被封装成DFSOutputStream。DFSOutputStream能够协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据分成一个个的数据包(packet),并写入一个内部队列,这个队列称为“数据队列”(data queue)
- DataStreamer会去处理接受data quene,它先询问namenode这个新的block最适合存储的在哪几个datanode里(比方副本数是3。那么就找到3个最适合的datanode),把他们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个datanode中。第一个datanode又把packet输出到第二个datanode中。以此类推。DataStreamer在将一个个packet流式的传到第一个DataNode节点后,还会将packet从数据队列移动到另一个队列确认队列(ack queue)中.确认队列也是由packet组成,作用是等待datanode完全接收完数据后接收响应.
- datanode写入数据成功之后,会为ResponseProcessor线程发送一个写入成功的信息回执,当收到管道中所有的datanode确认信息后,ResponseProcessoer线程会将该数据包从确认队列中删除。
- 客户端写完数据后会调用close()方法,关闭写入流.
- DataStreamer把剩余的包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,客户端通过调用DistributedFileSystem对象的complete()方法来告知namenode数据传输完成.
注意点1: 如果任何datanode在写入数据期间发生故障,则执行以下操作
1 | |
注意点2
1 | |
注意点3
1 | |