Hadoop安装
1 本地模式
1.1 介绍
本地模式,即运行在单台机器上。没有分布式的思想,使用的是本地文件系统。使用本地模式主要是用于对MapReduce的程序的逻辑进行调试,确保程序的正确性。由于在本地模式下测试和调试MapReduce程序较为方便,因此,这种模式适合用在开发阶段。
1.2 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
1.3 安装JDK
卸载之前的JDK
1
2
3# 卸载之前的原因,主要是需要保证安装的JDK版本的正确性。
[root@qianfeng01 ~]# rpm -qa | grep jdk # 如果有,请卸载
[root@qianfeng01 ~]# rpm -e xxxxxxxx --nodeps # 将查询到的内置jdk强制卸载上传JDK安装包到指定的路径
1
使用MobaXterm或者FinalShell直接上传即可,上传到 /root/softwares 下解压JDK到指定安装路径
1
[root@qianfeng01 ~]# cd /root/softwares && tar -zxvf jdk-8u321-linux-x64.tar.gz -C /usr/local配置环境变量
1
2
3
4
5
6[root@qianfeng01 local]# vim /etc/profile
...上述内容省略,在末尾添加即可...
# Java Environment
export JAVA_HOME=/usr/local/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin重新引导,使得环境变量生效
1
[root@qianfeng01 local]# source /etc/profile验证JDK是否配置完成
1
[root@qianfeng01 local]# java -version
1.4 安装Hadoop
上传Hadoop到指定的路径
1
使用MobaXterm或者FinalShell上传到 /root/softwares 下即可解压安装
1
[root@qianfeng01 ~]# cd /root/softwares && tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local配置环境变量
1
2
3
4
5[root@qianfeng01 ~]# vim /etc/profile
...上述内容省略,在最下方添加即可...
# Hadoop Environment
export HADOOP_HOME=/usr/local/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin重新引导,使得环境变量生效
1
[root@qianfeng01 ~]# source /etc/profile验证是否配置成功
1
[root@qianfeng01 ~]# hadoop version
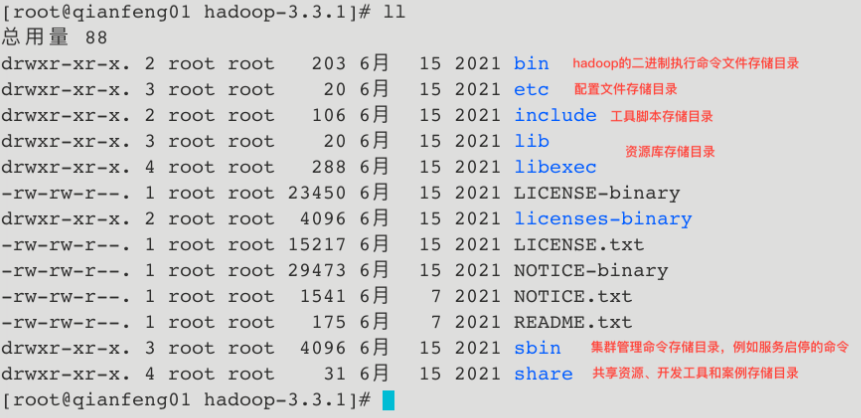
1.5 Hadoop目录说明
1.6 案例演示:wordcount
新建一个目录,存放文本文件
1
2# 将若干个存储单词的文件放入这个目录下
[root@qianfeng01 ~]# mkdir ~/input执行wordcount
1
[root@qianfeng01 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount ~/input ~/output查看结果
1
[root@qianfeng01 ~]# cat ~/output/*
1.7 案例演示:pi
直接计算pi的结果
1 | |
2 伪分布式模式
2.1 介绍
伪分布式模式也是只需要一台机器,但是与本地模式的不同,伪分布式使用的是分布式的思想,具有完整的分布式文件存储和分布式计算的思想。只不过在进行存储和计算的时候涉及到的相关的守护进程都运行在同一台机器上,都是独立的Java进程。因而称为伪分布式集群。比本地模式多了代码调试功能,允许检查内存使用情况、HDFS输入输出、以及其他的守护进程交互。总结来说: 伪分布式集群就是只有一个节点的分布式集群。
2.2 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
2.3 安装JDK
同1.3
2.4 安装Hadoop
同1.4
2.5 搭建环境准备
总纲
1
2
3
4
51. 确保防火墙是关闭状态。
2. 确保NAT模式和静态IP的确定 (192.168.10.101)
3. 确保/etc/hosts文件里, ip和hostname的映射关系
4. 确保免密登陆localhost有效
5. jdk和hadoop的环境变量配置防火墙关闭
1
2
3
4
5
6
7
8
9
10[root@qianfeng01 ~]# systemctl stop firewalld
[root@qianfeng01 ~]# systemctl disable firewalld
[root@qianfeng01 ~]# systemctl stop NetworkManager
[root@qianfeng01 ~]# systemctl disable NetworkManager
#最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled
[root@qianfeng01 ~]# vi /etc/selinux/config
.........
SELINUX=disabled
.........修改host映射
1
2
3
4
5
6# 进入hosts文件,配置一下ip和hostname
[root@qianfeng01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 qianfeng01 # 添加本机的静态IP和本机的主机名之间的映射关系确保ssh对localhost的免密登录认证有效
1
2
3
4
5
6# 1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
[root@qianfeng01 ~]# ssh-keygen -t rsa
# 2. 进入~/.ssh目录下,使用ssh-copy-id命令
[root@qianfeng01 .ssh]# ssh-copy-id root@qianfeng01
# 3. 进行验证,去掉第一次的询问(yes/no)
[hadoop@qianfeng01 .ssh]# ssh localhost确保JDK与Hadoop已经安装完成,并且已经配置好环境变量
2.6 配置文件修改
core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qianfeng01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.1/tmp</value>
</property>
</configuration>hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>qianfeng01:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>qianfeng01:9870</value>
</property>
</configuration>hadoop-env.sh
1
2
3
4
5
6export JAVA_HOME=/usr/local/jdk1.8.0_321
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
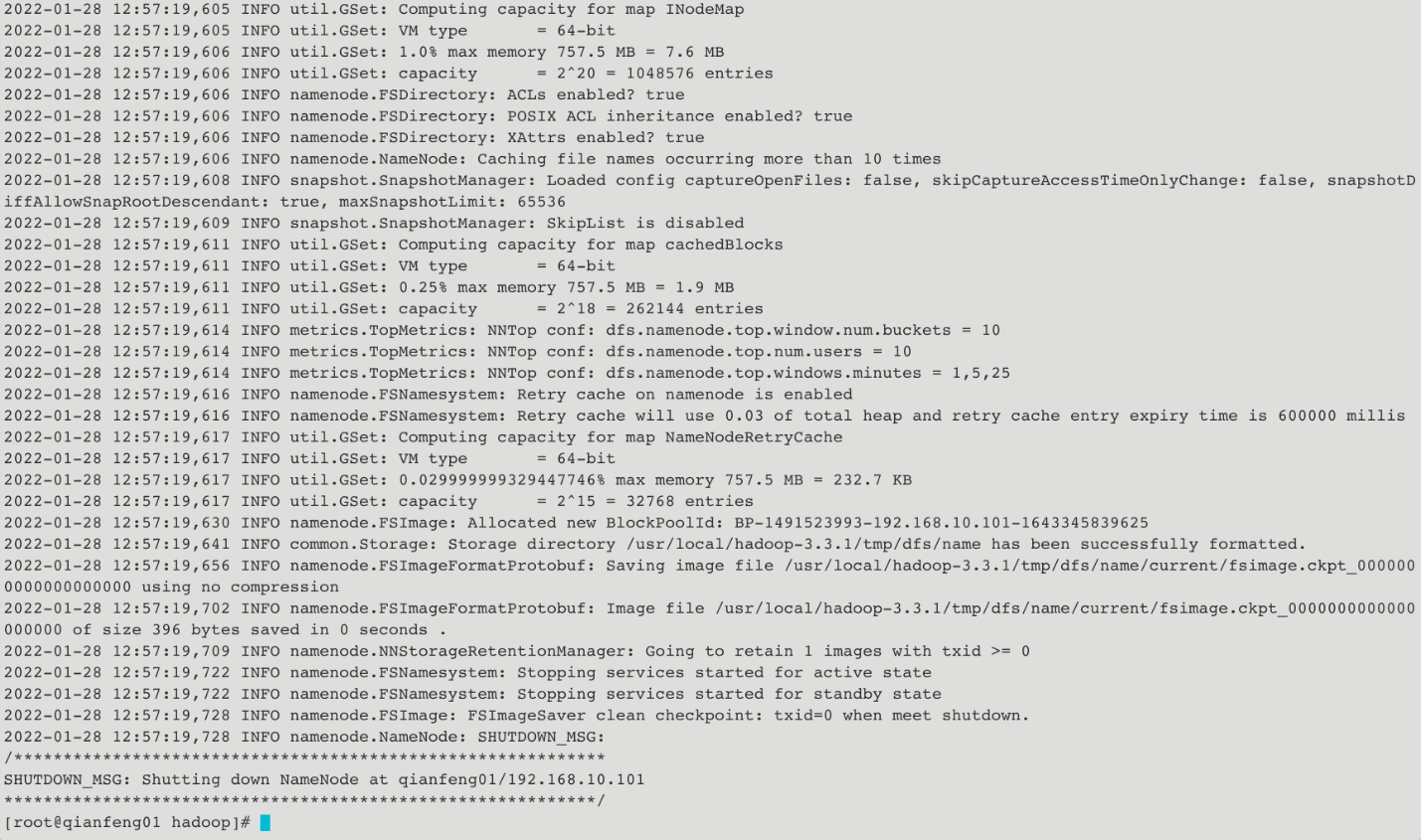
2.7 格式化集群
**注意事项:**在core-site.xml中配置过hadoop.tmp.dir的路径,在集群格式化的时候需要保证在这个路径不存在!如果之前存在数据,先将其删除,再进行格式化!
1 | |
2.8 启动集群
1 | |
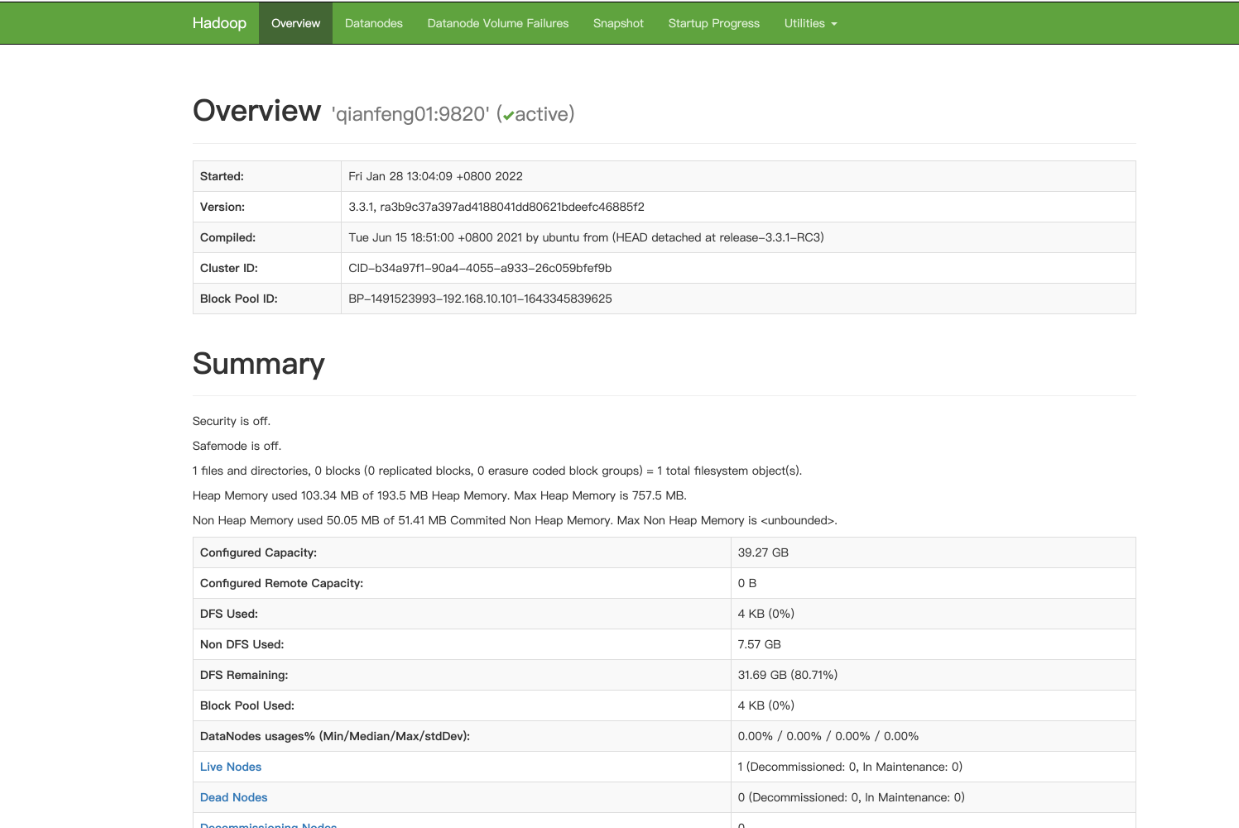
2.9 WebUI查看
在电脑的浏览器中输入虚拟机的IP地址,如果做过了主机名映射,可以直接使用主机名http://192.168.10.101:9870
2.10 案例演示 wordcount
数据准备
1
2
3
4
5
6
7[root@qianfeng01 ~]# mkdir input && cd input
[root@qianfeng01 input]# echo "hello world hadoop linux hadoop" >> file1
[root@qianfeng01 input]# echo "hadoop linux hadoop linux hello" >> file1
[root@qianfeng01 input]# echo "hadoop linux mysql linux hadop" >> file1
[root@qianfeng01 input]# echo "hadoop linux hadoop linux hello" >> file1
[root@qianfeng01 input]# echo "linux hadoop good programmer" >> file2
[root@qianfeng01 input]# echo "good programmer qianfeng good" >> file2上传到集群
1
2
3
4
5
6
7
8# 因为伪分布式集群也应用到了分布式的思想,分布式的存储。任务处理的数据是HDFS的数据,而并不是Linux本地的。
[root@qianfeng01 input]# hdfs dfs -put ~/input/ /
# 检查是否已经上传成功
[root@qianfeng01 input]# hdfs dfs -ls -R /
drwxr-xr-x - root supergroup 0 2022-01-28 13:11 /input
-rw-r--r-- 1 root supergroup 31 2022-01-28 13:11 /input/file
-rw-r--r-- 1 root supergroup 127 2022-01-28 13:11 /input/file1
-rw-r--r-- 1 root supergroup 59 2022-01-28 13:11 /input/file2执行任务
1
[root@qianfeng01 input]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output查看结果
1
2
3
4
5
6
7
8
9
10[root@qianfeng01 input]# hdfs dfs -cat /output/*
good 3
hadoop 9
hadop 2
hello 3
linux 10
mysql 2
programmer 2
qianfeng 1
world 1
3 完全分布式模式
3.1 介绍
在真实的企业环境中,服务器集群会使用到多台机器,共同配合,来构建一个完整的分布式文件系统。而在这样的分布式文件系统中,HDFS相关的守护进程也会分布在不同的机器上,例如:
- NameNode守护进程,尽可能的单独部署在一台硬件性能较好的机器中。
- 其他的每台机器上都会部署一个DataNode守护进程,一般的硬件环境即可。
- SecondaryNameNode守护进程最好不要和NameNode在同一台机器上。
3.2 平台软件说明
| 平台&软件 | 说明 |
|---|---|
| 宿主机操作系统 | Windows / MacOS |
| 虚拟机操作系统 | CentOS 7 |
| 虚拟机软件 | Windows: VMWare MacOS: Parallels Desktop |
| 虚拟机 | 主机名: qianfeng01, IP地址: 192.168.10.101 主机名: qianfeng02, IP地址: 192.168.10.102 主机名: qianfeng03, IP地址: 192.168.10.103 |
| SSH工具 | Windows: MobaXterm / FinalShell MacOS: FinalShell / iTerm2 |
| 软件包上传路径 | /root/softwares |
| 软件安装路径 | /usr/local |
| JDK | X64: jdk-8u321-linux-x64.tar.gz ARM: jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | X64: hadoop-3.3.1.tar.gz ARM: hadoop-3.3.1-aarch64.tar.gz |
| 用户 | root |
3.3 守护进程布局
| NameNode | DataNode | SecondaryNameNode | |
|---|---|---|---|
| qianfeng01 | √ | √ | |
| qianfeng02 | √ | √ | |
| qianfeng03 | √ |
3.4 集群搭建准备
总纲
1
2
3
4
5
61. 三台机器的防火墙必须是关闭的.
2. 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)
3. 确保/etc/hosts文件配置了ip和hostname的映射关系
4. 确保配置了三台机器的免密登陆认证(克隆会更加方便)
5. 确保所有机器时间同步
6. jdk和hadoop的环境变量配置防火墙关闭
1
2
3
4
5
6
7
8
9
10[root@qianfeng01 ~]# systemctl stop firewalld
[root@qianfeng01 ~]# systemctl disable firewalld
[root@qianfeng01 ~]# systemctl stop NetworkManager
[root@qianfeng01 ~]# systemctl disable NetworkManager
#最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled
[root@qianfeng01 ~]# vi /etc/selinux/config
.........
SELINUX=disabled
.........主机映射
1
2
3
4
5
6
7[root@qianfeng01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 qianfeng01 #添加本机的静态IP和本机的主机名之间的映射关系
192.168.10.102 qianfeng02
192.168.10.103 qianfeng03免密登录
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
[root@qianfeng01 ~]# ssh-keygen -t rsa
# 2. 使用ssh-copy-id命令
[root@qianfeng01 .ssh]# ssh-copy-id root@qianfeng01
[root@qianfeng01 .ssh]# ssh-copy-id root@qianfeng02
[root@qianfeng01 .ssh]# ssh-copy-id root@qianfeng03
# 3. 进行验证
[hadoop@qianfeng01 .ssh]# ssh qianfeng01
[hadoop@qianfeng01 .ssh]# ssh qianfeng02
[hadoop@qianfeng01 .ssh]# ssh qianfeng03
# 4. 继续在qianfeng02和qianfeng03生成公钥和私钥,给三台节点拷贝。时间同步
1
参考Linux部分,可以让三台节点都同步网络时间,或者选择其中一台作为时间同步服务器。安装JDK和配置环境变量
1
参考1.3和1.4章节内容。
3.5 配置文件
core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qianfeng01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.1/tmp</value>
</property>
</configuration>hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<configuration>
<!-- 块的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>qianfeng02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>qianfeng01:9870</value>
</property>
</configuration>hadoop-env.sh
1
2
3
4
5
6export JAVA_HOME=/usr/local/jdk1.8.0_321
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=rootworks
1
2
3qianfeng01
qianfeng02
qianfeng03分发
1
2
3
4
5# 我们已经完成了一个节点的环境配置,其他的节点也需要保持完全相同的配置。我们只需要将qianfeng01节点的配置拷贝到其他的节点即可。
# 分发之前,先检查自己的节点数据文件是否存在
# 如果之间格式化过集群,那么会在core-site.xml中配置的hadoop.tmp.dir路径下生成文件,先将其删除
[root@qianfeng01 ~]# stop-dfs.sh
[root@qianfeng01 ~]# rm -rf $HADOOP_HOME/tmp1
2
3
4
5
6
7
8
9[root@qianfeng01 ~]# cd /usr/local
[root@qianfeng01 local]# scp -r jdk1.8.0_321/ qianfeng02:$PWD
[root@qianfeng01 local]# scp -r jdk1.8.0_321/ qianfeng03:$PWD
[root@qianfeng01 local]# scp -r hadoop-3.3.1/ qianfeng02:$PWD
[root@qianfeng01 local]# scp -r hadoop-3.3.1/ qianfeng03:$PWD
[root@qianfeng01 local]# scp file/profile qianfeng02:/etc/
[root@qianfeng01 local]# scp file/profile qianfeng02:/etc/
3.6 格式化集群
1 | |
3.7 启动集群
1 | |
3.8 进程查看
1 | |
每次在查看集群的进程分布的时候,都需要在不同的节点之间进行切换,非常的麻烦。所以,我们可以设计一个小脚本。
1 | |
执行效果
1 | |
3.9 启动日志查看
HDFS的角色有三个: NameNode、SecondaryNameNode、DataNode,启动的时候也会有对应的日志文件生成。如果在启动脚本执行之后,发现对应的角色没有启动起来,那就可以去查看日志文件,检查错误的详情,解决问题。
日志的位置: $HADOOP_HOME/logs
日志的命名: hadoop-username-daemon-host.log
1 | |
3.10 集群常见问题
格式化集群时,报错原因
1
2
3
4
5- 当前用户使用不当
- /etc/hosts里的映射关系填写错误
- 免密登录认证异常
- jdk环境变量配置错误
- 防火墙没有关闭namenode进程没有启动的原因:
1
2
3- 当前用户使用不当
- 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容
- 网络震荡,造成edit日志文件的事务ID序号不连续datanode出现问题的原因
1
2
3- /etc/hosts里的映射关系填写错误
- 免密登录异常
- 重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容,造成datanode的唯一标识符不在新集群中。上述问题暴力解决: 重新格式化
1
如果想重新格式化,那么需要先删除每台机器上的${hadoop.tmp.dir}指定路径下的所有内容,然后再格式化:最好也把logs目录下的内容也清空,因为日志内容已经是前一个废弃集群的日志信息了,留着也无用。
3.11 案例演示:wordcount
数据准备
1
2
3
4
5
6
7[root@qianfeng01 ~]# mkdir input && cd input
[root@qianfeng01 input]# echo "hello world hadoop linux hadoop" >> file1
[root@qianfeng01 input]# echo "hadoop linux hadoop linux hello" >> file1
[root@qianfeng01 input]# echo "hadoop linux mysql linux hadop" >> file1
[root@qianfeng01 input]# echo "hadoop linux hadoop linux hello" >> file1
[root@qianfeng01 input]# echo "linux hadoop good programmer" >> file2
[root@qianfeng01 input]# echo "good programmer qianfeng good" >> file2上传到集群
1
2
3
4
5
6
7
8# 将数据上传到HDFS
[root@qianfeng01 input]# hdfs dfs -put ~/input/ /
# 检查是否已经上传成功
[root@qianfeng01 input]# hdfs dfs -ls -R /
drwxr-xr-x - root supergroup 0 2022-01-28 13:11 /input
-rw-r--r-- 1 root supergroup 31 2022-01-28 13:11 /input/file
-rw-r--r-- 1 root supergroup 127 2022-01-28 13:11 /input/file1
-rw-r--r-- 1 root supergroup 59 2022-01-28 13:11 /input/file2执行任务
1
[root@qianfeng01 input]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output查看结果
1
2
3
4
5
6
7
8
9
10[root@qianfeng01 input]# hdfs dfs -cat /output/*
good 3
hadoop 9
hadop 2
hello 3
linux 10
mysql 2
programmer 2
qianfeng 1
world 1