Raft算法
概括:
Leader选举。选择一台服务器作为leader,心跳监测,如果Leader崩溃则选择一台服务器作为Leader
系统正常运行(日志复制)
Leader变化后的安全性和一致性
处理旧Leader
客户端和服务端的交互
配置的变更
服务的状态:
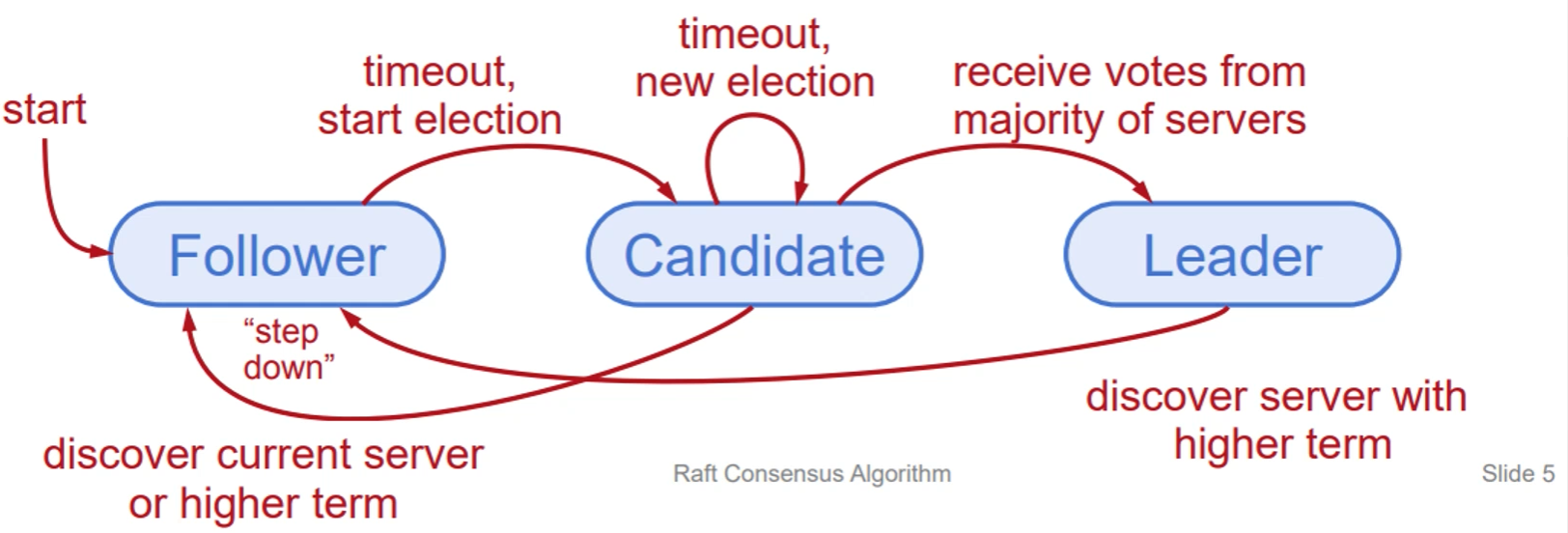
在任何时候,每个服务器都处于三种状态之一:
- Leader:处理所有客户端交互、日志复制。同时只能有一个Leader
- Follower:被动处理Leader发送的请求(被动响应传入的RPC、不主动发起RPC)
- Candidate:用来重新选举领导人
正常情况下:1个Leader,n-1个Follower
Terms-任期
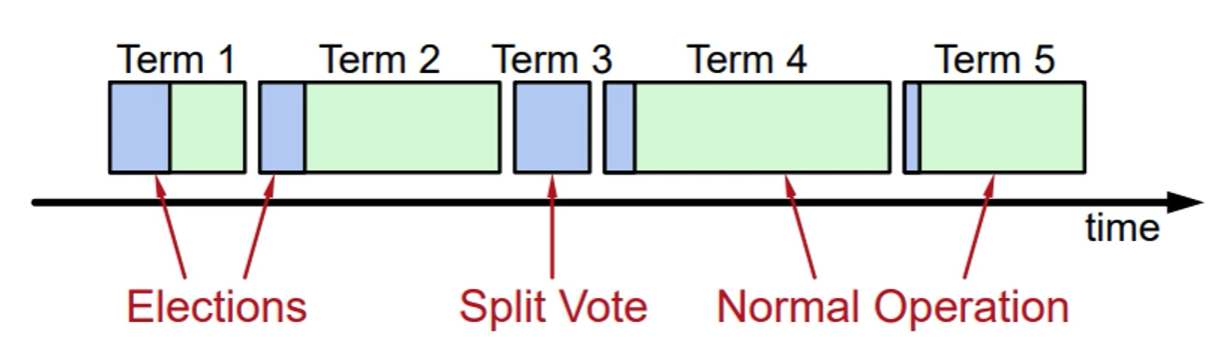
以时间来作为划分条件
每届只能有一个Leader
有些任期可能会没有Leader,选举失败
每个服务器都保存当前的Term值
Terms作用:识别过时的信息
Leader选举:心跳和超时
服务器作为Followers启动
Followers等待接收来自Leader或Candidates的RPC请求
Leader必须发送心跳(一个空的AppendEntries RPC)以维护自己的权限
如果在electionTimeOut过期了还没有收到来自Leader的RPC,Followers认为Leader崩溃了,Followers会开始新的Leader选举,electionTimeOut通常为100~500ms
Leader选举的基本原理
递增current Term
把状态更改为Candidate
投票给自己
发送RequestVote RPCs给所有的其他服务器,不断重试直到:
(1)从大多数的服务器接收到投票:成为leader,发送AppendEntries心跳给其他所有服务器
(2)发现存在有效的Leader:把状态修改为Follower
(3)没有人成为Leader(选举超时):增加Term,开始新德一轮选举
Leader选举的安全性和有效性
- 安全性:每个Term只能允许一台机器成为Leader,每台机器每个Term只能投一票(持久化到磁盘上),两个不同得Candidate不能在同一个Term中同时获得多数投票
- 有效性(活性):确保某个Candidate获胜,选择随机的ElectionTimeOuts范围在[T,2T]之间,一台服务器通常在其他服务器超时醒来之前赢得选举,如果T >> 广播时间是比较友好的
日志结构
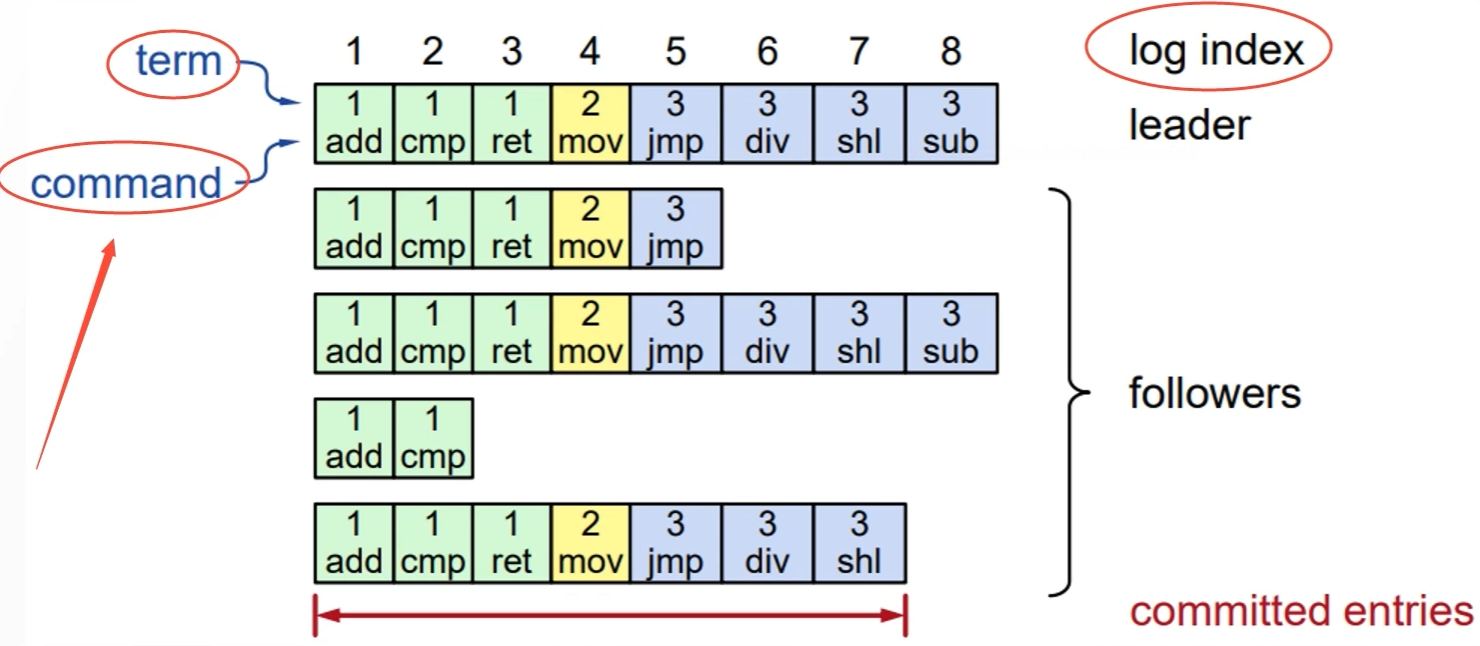
- log entry = index,term,command
- 日志存储在稳定的存储器(磁盘)上;在崩溃恢复后能继续使用
- 如果command已经存储在大多数服务器上,则提交entry,最终由状态机去执行command
客户端和服务端的正常操作
- 客户端向Leader发送命令
- Leader将命令添加到其复制日志中
- Leader向Follower发送AppendEntries RPC
- 一旦提交新的Entry:Leader将命令传递给其状态机执行,将结果返回给客户端;Leader在后续会发送AppendEntries RPC通知Follower已提交的Entry;Follower将提交的命令传递给自身的状态机执行
- 崩溃or Follower响应缓慢:Leader不断发送重试RPC,直到成功为止
- 在以下情况性能最佳:向集群中大多数的服务器都成功发送一次的RPC,而不是全部
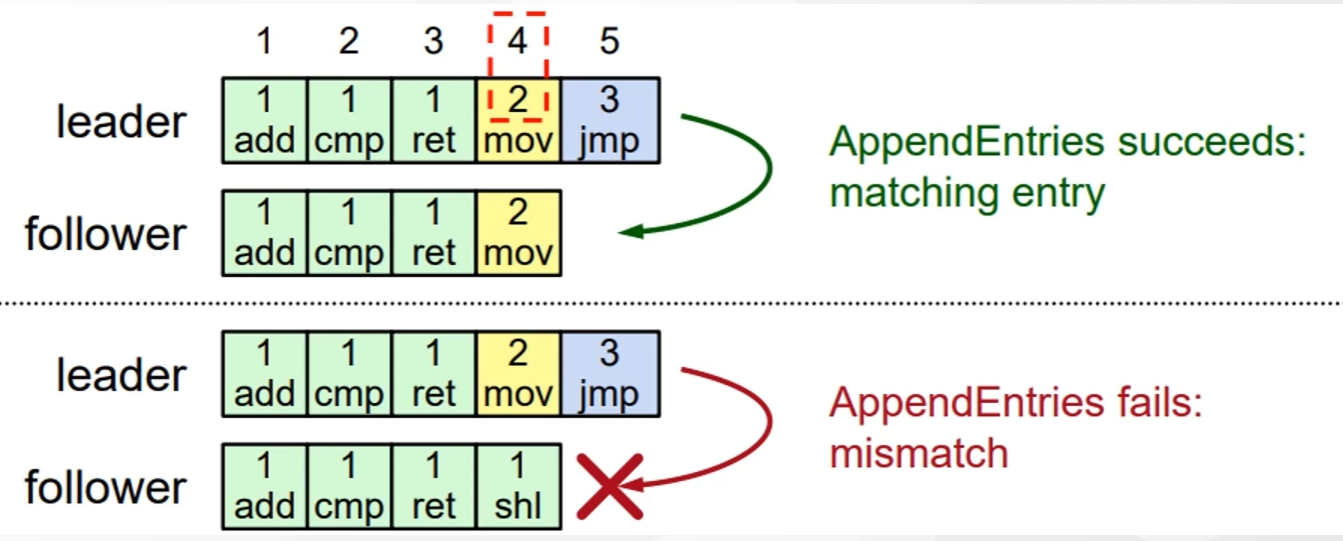
AppendEntries RPC对日志的一致性检查
- 每个AppendEntries RPC包含新条目和新条目之前的条目的索引和任期
- Follower必须包含匹配条目,否则会拒绝请求
- 执行归档步骤,确保一致性
Raft算法
http://www.zivjie.cn/2023/12/09/算法/一致性算法/Raft算法/