RocketMQ保证消息可靠性
1 Producer保证消息高可靠
(1)尽量采用同步或者异步的方式发送消息,最好不要使用oneway的方式发送,也就是说当把消息发到broker之后,一定要得到broker的响应
(2)建立数据库消息发送表,防止消息还没来得及发送当前系统就宕机了,这样等系统恢复的时候,可以根据消息发送表中的记录决定是否需要重新发送,发送成功之后要将对应表中的记录删除或者更新成发送成功状态,可以避免重复发送消息
(3)消息发送的重试机制,当producer向broker发送消息时,因为网络原因或者broker挂了,这样情况下肯定得不到broker的 响应,解决方案就是要做好重试机制,默认重试的次数是2,如果2次依然不能满足要求,这时候可以考虑开启一个定时任务,不断重试,或者人工补偿。
1 | |
(4)消息最大大小为4M,如果消息超过了这个大小,发送会有限制,并且在broker端其实对于消息的处理默认上线也是4MB, 所以producer要发送的消息如果超过4M,记得做划分。
1 | |
2 集群保证消息高可靠
2.1 集群搭建
(1)NameServer集群部署在不同的节点上:可以防止单点故障
(2)Broker集群部署[比如采用双主双从架构]:可以防止单点故障、提高读写性能、增加消息的可靠性等
(3)Producer、Consumer、Broker都要设置好nameserver的集群地址,防止获取不到最新的路由信息
2.2 Broker主从复制策略
两种选择:同步复制[同步双写]和异步复制
一般情况下,broker的刷盘策略选择异步刷盘,而复制策略选择同步双写,这样做是为了在消息可靠性与性能之间能够平衡一下
2.3 Broker刷盘策略
两种选择:同步刷盘和异步刷盘
在同步刷盘的策略下,只要producer收到了SEND_OK,那么消息一定是被持久化到了broker的磁盘中,以commitlog的形式保存,这样消息就不容易丢失了
而在异步刷盘的策略下,即使producer把消息发送到broker,但是不能完全保证消息被持久化到了磁盘,所以消息可能会丢失
这两种方式虽然同步刷盘的消息可靠性更高,但是在一般场景下,为了追求更好的性能,通常采用异步刷盘的方式
2.4 Broker磁盘选择
https://zh.wikipedia.org/wiki/RAID
Broker磁盘的存储介质可以选择RAID 10或者分布式存储,避免磁盘损坏导致消息丢失
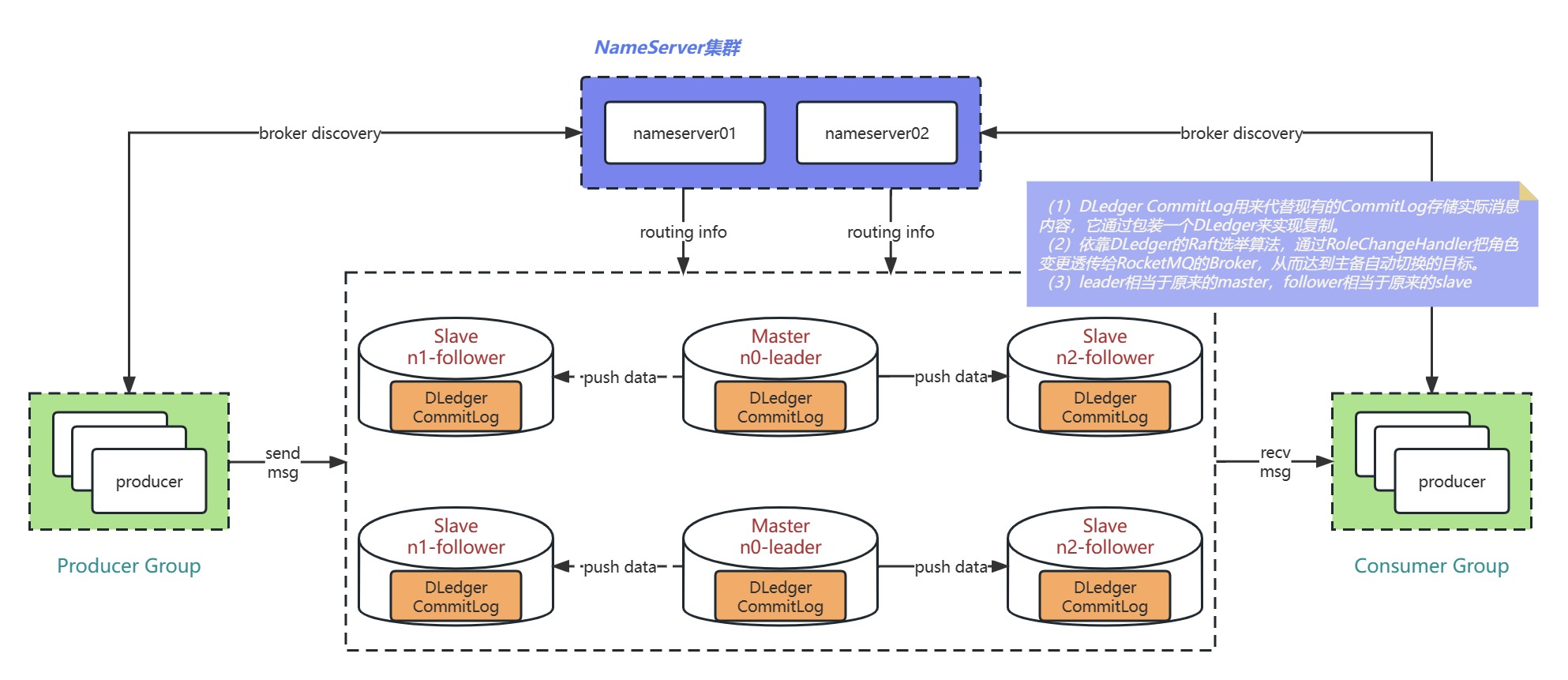
3 DLedger
DLedger,它是基于RAFT协议的commitlog存储库,解决了自动选举brokermaster和日志复制的问题。
https://github.com/openmessaging/dledger
DLedger作为RocketMQ的消息存储
搭建:https://rocketmq.apache.org/zh/docs/bestPractice/02dledger
4 Consumer保证消息高可靠性
4.1 消息重试机制
当一条消息初次消费失败,消息队列 RocketMQ 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列 RocketMQ 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。在消息队列 RocketMQ 中,这种正常情况下无法被消费的消息称为死信消息(Dead-LetterMessage)
存储死信消息的特殊队列称为死信队列 (Dead-Letter Queue)。 一条消息进入死信队列,意味着某些因素导致消费者无法正常消费该消息,因此,通常需要对其进行特殊处理。排查可疑因素并解决问题后,可以在消息队列 RocketMQ控制台重新发送该消息,让消费者 重新消费一次。
4.2 给Broker一个反馈
1 | |
4.3 消费消息幂等处理
如何避免消息重复消费?可以使用唯一的msgid,或者业务id,比如orderid,利用数据库日志表或 redis主键进行幂等处理。
5 如何处理消息积压
(1)消费者出错,肯定是程序或者其他问题导致的,如果容易修复,先把问题修复,让consumer恢复正常消费
(2)如果时间来不及处理很麻烦,做转发处理,写一个临时的consumer消费方案,先把消息消费,然后再转发到一个新的topic和MQ资源,这个新的topic的机器资源单独申请,要能承载住当前积压的消息
(3)处理完积压数据后,修复consumer,去消费新的MQ和现有的MQ数据,新MQ消费完成后恢复原状
(4)增加consumer的数量
(5)限流