Kafka原理分析以及特性总结
1 生产者原理
源码地址:https://github.com/apache/kafka/tree/trunk/clients
1.1 生产者发送消息
消息发送的整体流程。生产端主要由两个线程协调运行。这两条线程分别为main线程和sender线程(发送线程)。
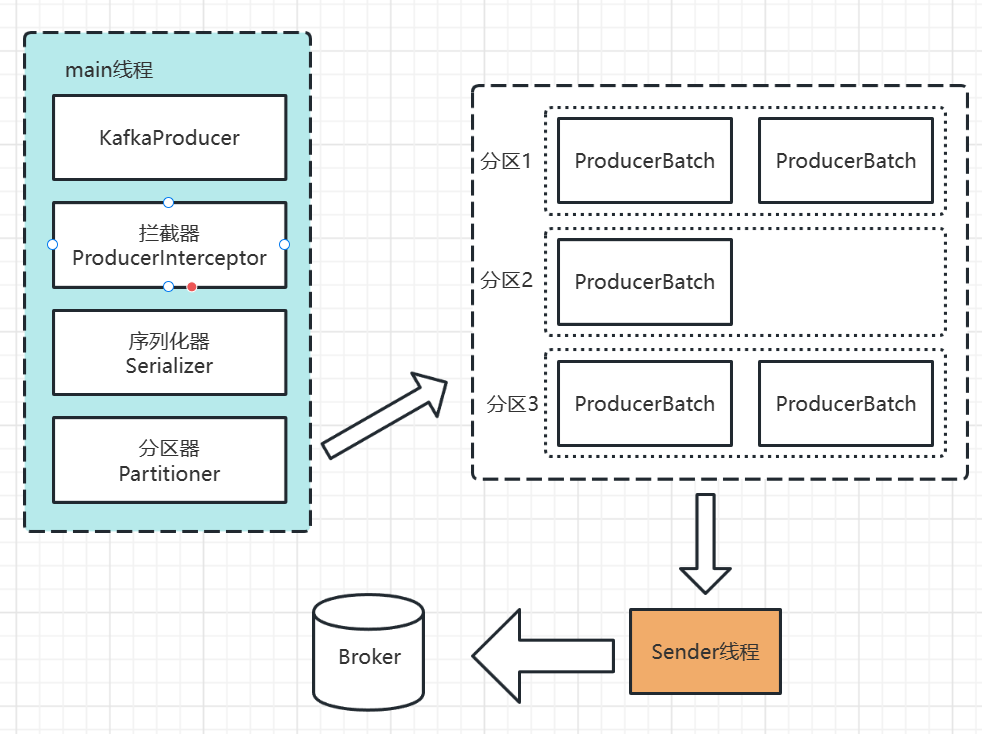
1 | |
在创建KafkaProducer的时候,创建了一个Sender对象,并且启动了一个IO线程。
1 | |
1.1.1 拦截器
接下来执行拦截器的逻辑,在producer.send方法中
1 | |
拦截器的作用是实现消息的定制化(类似于Spring Interceptor、Mybatis的插件,Quartz的监听器)。这个拦截器定义的位置是在:
1 | |
可以在生产者的属性中指定多个拦截器,形成拦截器链。举个例子,假设发送消息的时候要扣钱,发一条消息1分钱(把这个功能叫做按量付费),就可以用拦截器实现。
1 | |
1.1.2 序列化
调用send方法后,第二步是利用指定的工具对key和value进行序列化
1 | |
Serializer.java——kafka针对不同的数据类型自带了相应的序列化工具。除了自带的序列化工具之外,可以使用如Avro,JSON,Thrift,Prorobuf等,或者使用自定义类型的序列化器来实现,实现Serializer接口即可。
1.1.3 路由指定-分区器
然后是路由指定
1 | |
一条消息会发送到哪个partition呢?它返回的是一个分区的编号,从0开始。首先分一下有四种情况:
1、指定了partition;
2、没有指定partition,自定义了分区器
3、没有指定partition,没有自定义分区器,但是key不为空
4、没有指定partition,没有自定义分区器,但是key是空的
第一种情况:指定partition的情况下,直接将指定的值直接作为partition值;
1 | |
第二种情况:自定义分区器,将使用自定义的分区器算法选择分区,比如SimplePartitioner,用ProducerAutoPartition指定,发送消息
1 | |
第三种情况:没有指定partition值但是有key的情况下,使用默认分区器DefaultPartitioner,将key的hash值与topic的partution数进行取余得到partition值;
1 | |
第四种情况:既没有partition值又没有key值得情况下,第一次调用时随机生成一个证书(后面每次调用在这个整数上自增),将这个值与topic可用得partition总数取余得到partition值,也就是常说得round-robin算法
1 | |
1.1.4 消息累加器
选择分区后并没有直接发送消息,而是把消息放入了消息累加器。
1 | |
RecordAccumulator本质上是一个ConcurrentMap,一个partition一个Batch。batch满了之后,会唤醒Sender线程,发送消息。
1 | |
小结一下:可以在拦截器中自定义消息处理逻辑,也可以选择自己喜欢得序列化工具,还可以自由选择分区。
1.2 服务端响应ack
1.2.1 响应策略
kafka服务端应该要有一种响应客户端的方式,只有在服务端确认以后,生产者才发送下一轮的消息,否则重新发送数据。因为消息是存储在不同的partition中的,所以是写入到partition之后响应生产者。
当然,单个partition(leader)写入成功,还是不够可靠,如果有多个副本,follower也要写入成功才可以。服务端发送ACK给生产者总体上有两种思路:
第一种是需要有半数以上的follower节点完成同步,这样的话客户端等待的时间就短一些,延迟低。
第二种需要所有的follower全部完成同步,才发送ACK给客户端,延迟相对来说高一些,但是节点挂掉的影响相对来说小一些,因为所有的节点数据都是完整的。
kafka选择了第二种方案。部署同样机器数量的情况下,第二种方案的可靠性更高。例如部署5台机器,那么第一种方案最多可能会有2台机器丢失数据,第二种都不会丢失。而且网络延迟对kakfa的影响不大。
1.2.2 ISR
不是所有的follower都有权力让我等待。应该把那些正常和leader保持同步的replica维护起来,放到一个动态set中,这个就叫做in-sync replica set (ISR)。现在只要ISR中的follower同步完数据之后,就给客户端发送ACK。对于经常性迟到,睡觉还关手机的太子,看来他不关心国事,也不能指望他了,把他从太子早会微信群移除了。如果一个follower长时间不同步数据,就要从ISR剔除。这个时间由参数replica.lag.time.max.ms决定(默认值30秒)。如果leader挂了,就会从ISR重新选举leader。
1.2.3 ACK应答机制
kafka为客户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择响应的配置。
acks=0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接受到还没写入磁盘就已经返回,当broker故障时有可能丢失数据;
acks=1(默认):producer等待broker的ack,partition的leader落盘成功后返回ack,如果follower同步成功之前leader故障,那么将会丢失数据;
acks=-1(all):producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。
三种机制,性能依次递减(producer吞吐量降低),数据健壮性则依次递增。可以根据业务场景使用不同的参数。(类比:MySQL的binlog主从复制——同步,异步,半同步)
2 Broker存储原理
2.1 文件的存储结构
配置文件:config/server.properties -> logs.dir配置,默认/tmp/kafka-logs
2.1.1 partition分区
为了实现横向扩展,把不同的数据存放在不同的Broker上,同时降低单台服务器的访问压力,把一个topic中的数据分隔成多个partition。一个partition中的消息是有序的,顺序写入,但是全局不一定有序。在服务器上,每个partiton都有一个物理目录,topic名字后面的数据标号即代表分区。
2.1.2 replica副本
为了提高分区的可靠性,kafka又设计了副本机制。创建topic的时候,通过指定replication-factor确定topic的副本数。注意:副本数必须小于等于节点数,而不能大于Broker的数量,否则会报错。这样就可以保证,绝对不会有一个分区的两个副本分布在同一个节点上,不然副本机制也失去了备份的意义了。
这些所有的副本分为两种角色,leader对外提供读写服务。follower唯一的任务就是从leader异步拉取数据。读写都发生在leader节点,就不存在读写分离带来的一致性问题了。这个叫做单调读一致性。
2.1.3 副本在Broker的分布
分配策略是由AdminUtils.scala的assignReplicasToBrokers函数决定的。规则如下:
1)first of all,副本因子不能大于Broker的个数
2)第一个分区(编号为0的分区)的第一个副本放置位置是随机从brokerList选择的(Brokers2的副本)
3)其他分区的第一个副本放置位置相对于第0个分区依次往后移,也就是说:如果有5个Broker,5个分区,假设第一个分区的第一个副本放在第四个Broker上,那么第二个分区的第一个副本将会放在第五个Broker上;第三个分区的第一个副本将会放在第一个Broker上;第四个分区的第一个副本将会放在第二个Broker上,以此类推;
4)每个分区剩余的副本相对于第一个副本放置位置其实是nextReplicaShift决定的,而这个数也是随机产生的。
在每个分区的第一个副本错开之后,一般第一个分区的第一个副本(按Broker编号排序)都是leader。leader是错开的,不至于一挂影响太大。bin目录下的kafka-reassign-partitons.sh可以根据Broker数量变化情况重新分配分区。
2.1.4 segment
为了防止log不断追加导致文件过大,导致检索消息效率变低,一个partition又被划分成多个segment来组织数据(MySQL也有segment的逻辑概念,叶子节点就是数据段,非叶子节点就是索引段)。在磁盘上,每个segment由一个log文件和两个index文件组成。

leader-epoch-checkpoint中保存了每一任leader开始写入消息时的offset。
(1).log日志文件(日志就是数据)
在一个segment文件里面,日志是追加写入的。如果满足一定条件,就会切分日志文件,产生要给新的segment。
第一种是根据日志文件大小。当一个segment写满之后,会创建一个新的segment,用最新的offset作为名称。这个例子可以通过往一个Topic发送大量消息产生。segment的默认大小是1G,由这个参数控制:log.segment.bytes
第二种是根据消息的最大时间戳,和当前系统时间戳的差值。有一个默认的参数,168小时(一周):log.roll.hours=168。意味着:如果服务器上次写入消息是一周之前,旧的segment就不写了,现在要创建一个新的segment。还可以从更加精细的时间单位进行控制,如果配置毫秒级别的日志切分间隔,会优先使用这个单位。否则就用小时的。log.roll.ms
第三种是offset索引文件或者timestamp索引文件达到了一定的大小,默认是10M。如果要减少日志文件的切分,可以把这个值调大一点。log.index.size.max.bytes
以及:索引文件写满了,数据文件也要跟着拆分,不然这一套东西对不上。另外两个是索引文件,单独来看:
(2).index偏移量(offset)索引文件
(3).timeindex时间戳(timestamp)索引文件
2.1.5 索引
由于一个segment的文件中可能存放很多消息,如果要根据offset获取消息,必须要有一个快速检索消息的机制。这个就是索引。在kafka中设计了两种索引。偏移量索引文件记录的是offset和消息物理地址(在log文件中的位置)的映射关系。时间戳索引文件记录的是时间戳和offset的关系。
当然,内容是二进制地文件,不能以纯文本形式查看。bin目录下dumplog工具。
kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引sparse index(DB2和MongoDB中都有稀疏索引)。
消息的大小来控制索引的产生,默认是4KB:
1 | |
只要写入的消息超过了4KB,偏移量索引文件.index和时间戳索引文件.timeindex就会增加一条索引记录(索引项)。这个值设置越小,索引越密集/值设置的越大,索引越稀疏。相对来说,越稠密的索引检索数据更快,但是会消耗更多的存储空间。越稀疏索引占用存储空间越小,但是插入和删除时所需的维护开销也小。Kafka索引的时间复杂度为O(log2n) + O(m),n是索引文件里索引的个数,m是稀疏程度。
第二种索引类型是时间戳索引。首先消息是必须要记录时间戳的。客户端封装的ProducerRecord和ConsumerRecord都有一个long timestamp属性。
1、如果要基于时间切分日志文件,必须要记录时间戳。
2、如果要基于时间清理消息,必须要记录时间戳
注意时间戳有两种,一种是消息创建的时间戳,一种是消费在Broker追加写入的时间。到底用哪个时间由一个参数来控制:
1 | |
默认是创建时间。如果要改成日志追加时间,则修改LogAppendTime。
kafka如何基于索引快速检索消息:
- 消费的时候是能够确定分区的,所以第一步是找到在哪个segment中。segment文件是用base offset命名的,所以可以用二分法很快确定
- 这个segment有对应的索引文件,它们是成套出现的。所以现在要在索引文件中根据offset找position
- 得到position之后,到对应的log文件开始查找offset,和消息的offset进行比较,直到找到消息
kafka是写多,查少。如果kafka用B+Tree,首先会出现大量的B+Tree,大量插入数据带来的B+tree的调整会非常消耗性能。
2.2 消息保留(清理)机制
2.2.1 开关与策略
Kafka中提供了两种方式,一种是直接删除delete,一种是对日志进行压缩compact。默认是直接删除。
1 | |
2.2.2 删除策略
日志删除是通过定时任务实现的。默认5分钟执行一次,看看有没有需要删除的数据。
1 | |
删除是从最老的数据开始删。关键是对老数据的定义。由一个参数控制:
1 | |
默认值是168小时(一周),也就是时间戳超过一周的数据才会删除。kafka另外提供了两个粒度更细的配置,分钟和毫秒。
1 | |
第二种删除策略是根据日志大小删除,先删除旧的消息,删到不超过这个大小为止。
1 | |
默认值是-1,代表不限制大小,想写多少就写多少。log.retention.bytes指的是所有日志问价的总大小。也可以对单个segment文件大小进行限制。
1 | |
2.2.3 压缩策略
当有了这些key相同的value不同的消息的时候,存储空间旧被浪费了。压缩就是把相同的key合并为最后一个value。这个压缩跟Compression的含义不一样。所以,这里称为压紧更加合适。Log Compaction执行过后的偏移量不再是连续的,不过这并不影响日志的查询。
2.3 高可用架构
2.3.1 Controller选举
不是所有的repalica都参与leader选举,而是由其中的一个Broker统一来指挥,这个Broker的角色就是Controller。就像Redis Sentinel的架构,执行故障转移的时候,必须要先从所有哨兵中选一个负责做故障转移的节点一样。kafka也要先从所有Broker中选出唯一的一个Controller。所有的Broker会尝试在zookeeper中创建临时节点/controller,只有要给能创建成功(先到先得)。
如果Controller挂掉了或者网络出现了问题,ZK上的临时节点会消失。其他的Broker通过watch监听到Controller下线的消息后,开始竞选新的Controller。方法跟之前的还是一样的,谁现在ZK中写入一个Controller节点,谁就成为新的Controller。
一个节点成为Controller之后,它肩上的责任也比别人重了几份,正所谓劳力越大,责任越大:监听Broker变化;监听Topic变化;监听Partition变化;获取和管理Broker、Topic、Partition的信息;管理Partition的主从信息。
2.3.2 分区副本Leader选举
一个分区所有的副本,叫做Assigned-Replicas(AR)。所有的皇太子。这些所有的副本中,跟leader数据保持一定程度同步的,叫做In-Sync Replicas(ISR)。天天过来参加早会,有希望继位的皇太子。跟leader不同步的副本,叫做Out-Sync-Replicas(OSR)。天天睡懒觉,不参加早会,没被皇帝放在眼里的皇太子。
AR=ISR+OSR。正常情况下OSR是空的,大家都正常同步,AR=ISR
默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader。
如果ISR为空呢?皇帝突然驾崩,太子们都还小,但是群龙不能无首。在这种情况下,可以让ISR之外的副本参与选举。允许ISR之外的副本参与选举,叫做unclean leader election。
1 | |
把这个参数改成true(一般情况不建议开启,会造成数据丢失)。
kafka的选举实现,最相近的是微软的PacificA算法。在这种算法中,默认是让ISR中第一个replica变成leader。比如ISR是1、5、9,优先让1成为leader。这个跟中国古代皇帝传为是一样的,优先传给皇长子。
2.3.3 主从同步
leader确定之后,客户端的读写只能操作leader节点。follower需要向leader同步数据。先说几个概念:
- LEO(Log End Offset):下一条等待写入的消息的offset(最新的offset+1)
- HW(High Watermark):ISR中最小的LEO。Leader会管理所有ISR中最小的LEO作为HW。consumer最多只能消费到HW之前的位置(消费到offset5的消息)。也就是说:其他的副本没有同步过去的消息,是不能被消费的。如果在同步成功之前就被消费了,consumer group的offset会偏大。如果leader奔溃,中间会缺失消息。
同步过程:
1、follower节点会向leader发送一个fetch请求,leader向follower发送数据后,即需要更新follower的LEO。
2、follower接收到数据响应后,依次写入消息并且更新LEO。
3、leader更新HW(ISR最小的LEO)
kafka设计了独特的ISR复制,可以在保障数据一致性的情况下又可以提高吞吐量。
2.3.4 replica故障处理
2.3.4.1 follower故障处理
首先follower发生故障,会被踢出ISR。恢复之后,首先根据之前记录的HW(6),把高于HW的消息截掉(6、7).然后向leader同步消息。追上leader之后(30秒),重新加入ISR。
2.3.4.2 leader故障处理
首先选一个leader。为了保证数据一致,其他的follower需要把高于HW的消息截取掉(这里没有消息需要截取)。然后同步数据。注意:这种机制只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
3 消费者原理
3.1 offset维护
3.1.1 offset的存储
命令查看offset信息:
1 | |
| PARTITION | CURRENT-OFFSET | LOG-END-OFFSET | LAG | CONSUMER-ID |
|---|---|---|---|---|
| 0 | 5 | 5 | 0 | consumer-1 |
| 1 | 5 | 5 | 0 | consumer-1 |
| 2 | 5 | 5 | 0 | consumer-2 |
CURRENT-OFFSET指的是下一个未使用的offset。
Log End Offset(LEO):下一条等待写入的消息的offset(最新的offset+1)
LAG是延迟量
注意:不是一个消费者和Topic的关系。是一个consumer group和topic中的一个partiton的关系(offset在partition中连续编号而不是全局连续编号),这个对应关系是保存在服务端的。
kafka早期的版本把消费者组和partition的offset直接维护在ZK中,但是读写的性能消耗太大了。后来就放在一个特护的Topic中,名字叫_consumer_offsets,默认由50分区(offsets.topic.num.partitions默认是50),每个分区默认一个replication。
这个Topic中主要存储两种对象:
GroupMetadata:保存了消费者组中各个消费者的信息(每个消费者有编号)。
OffsetAndMetadata:保存了消费者组和各个partition的offset位移信息元数据。
确定offset在哪个分区:
1 | |
什么情况下找不到offset?就是没有消费过,没有把当前的offset上报给Broker。消费者的代码中有一个参数,用来控制如果找不到偏移量的时候从哪里开始消费。
1 | |
默认值是latest,也就是最新的消息(最后发送的)开始消费。历史消息是不能消费的。
earliest代表从最早的(最先发送的)消息开始消费。可以消费到历史消息。
none,如果consumer group在服务端找不到offset会报错。
3.1.2 offset的更新
消费者组的offset是保存在Broker的,但是是由消费者上报给Broker的,并不是消费者组消费了消息,offset就会更新,消费者必须要有一个commit的动作。就跟RabbitMQ中消费者的ACK一样。一样的,消费者可以手动提交或者自动提交,由参数控制:
1 | |
默认是true,true代表消费者消费消息以后自动提交此时Broker会更新消费者组的offset。另外还可以使用一个参数来控制自动提交的频率:
1 | |
如果要在消费完消息做完业务逻辑处理之后才commit,就要把这个值改成false,如果是false,消费者就必须要调用一个方法让Broker更新offset。有两种方式:consumer.commitSync()的手动同步提交;consumer.commitAsync()的手动异步提交。
1 | |
如果不提交或者提交失败,Broker的offset不会更新,消费者组下次消费的时候会消费到重复的消息。
3.2 消费者消费策略
通过partition.assignment.strategy设置消费策略:
1 | |
3.2.1 消费策略
- RangeAssignor,默认策略。按照范围连续分配的。
- RoundRobinAssignor,随机策略
- StickyAssignor:这种策略复杂一点,但是相对来说均匀一点(每次结果都可能不一样)。原则:1)分区的分配尽可能的均匀。2)分区的分配尽可能和上次分配保持相同。
Consumer可以指定topic的某个分区消费,要用到assign而不是subscrible的接口。subscribe会自动分配消费者组的分区,而assign可以手动指定分区消费,相当于consumer group id失效了。
1 | |
3.2.2 rebalance分区重分配
有两种情况需要重新分配分区和消费者的关系:
1、消费者组的消费者数量发生变化。比如增加了消费者,消费者关闭连接
2、Topic的分区数发生变更,新增或者减少
为了让分区分配尽量地均衡,这个时候会触发rebalance机制。重新分配分成这么几步:
1、找一个话事人,它起到一个见度和保证公平地作用,每个Broker上都有要给用来管理offset,消费者组地实例,叫做GroupCoordinator。第一步就是要从所有地GroupCoordinator中找一个话事人出来。
2、第二步,清点一下认数。所有的消费者连接到GroupCoordinator报数,这个叫join group请求
3、第三步,选组长,GroupCoordinator从所有消费者中选一个leader。这个消费者会根据消费者地情况和设置地策略,确定一个方案。Leader把方案上报给GroupCoordinator,GroupCoordinator会通知给所有消费者。
4 kafka特性
顺序读写,批量读写和文件压缩,零拷贝
5 kafka消息不丢失的配置
1、producer端使用producer.send(msg,callback)带有回调的send方法,而不是producer.send(msg)方法。根据回调,一旦出现消息提交失败的情况,就可以有针对性的进行处理。
2、设置acks=all。acks是Producer的一个参数,代表“已提交”消息的定义。如果设置成all,则标名所有Broker都要接收到消息,该消息才算是“已提交”。
3、设置retries为一个较大的值。同样是Producer的参数。当出现网络抖动时,消息发送可能会失败,此时配置了retries的Producer能够自动重试发送消息,尽量避免消息丢失。
4、设置unclean.leader.election.enable = false。
5、设置replication.factor>=3。需要三个以上的副本。
6、设置min.insync.replicas>1/Broker端参数,控制消息至少要被写入到多少个副本才算是已提交。设置成大于1可以提升消息持久性。在生产环境中不要使用默认值1。确保replication.factor>min.insync.replicas。如果两者相等,那么只要有一个副本离线,整个分区就无法正常工作了。推荐设置成replication.factor = min.insync.replicas + 1。
7、确保消息消费完成再提交。Consumer端有个参数enable.auto.commit,最好设置成false,并自己来处理offset的提交更新。
6 与RabbitMQ的对比
主要区别:
1、产品侧重——kafka:流式处理、消息引擎;RabbitMQ:消息代理
2、性能:kafka有更高的吞吐量。RabbitMQ主要是push,kafka只有pull
3、消息顺序:kafka分区中的消息是有序的,同一个consumer group中的一个消费者只能消费一个partition,能保证消息的顺序性。
4、消息的路由和分发:RabbitMQ更加灵活
5、延迟消息,死信队列:RabbitMQ支持
6、消息的留存:kafka消费完之后消息会留存,RabbitMQ消费完就删除。kafka可以设置retention,清理消息。
优先选择RabbitMQ的情况:高级灵活的路由规则;消息时序控制(控制消息过期或者消息延迟);高级的容错处理能力,在消费者更有可能处理消息不成功的情景中(瞬时或者持久);更简单的消费者实现。
优先选择kafka的情况:严格的消息顺序;延长消息留存时间,包括过去消息重放的可能;传统解决方案无法满足的高伸缩能力。