Dubbo-高级应用
官网:https://cn.dubbo.apache.org/zh-cn
https://www.processon.com/view/link/6343917be0b34d40be5a3daf
1 服务注册与发现
Apache Dubbo天然就支持服务注册发现,最早开源的时候,官方建议使用 Apache Zookeeper作为注册中心。 因此到现在仍然还有很多公司是Dubbo+Zookeeper这样一个架构。 随着Apache Dubbo重新迭代,从Apache Dubbo2.7.x版本开始,支持的注册中心增加了很多,包括: Consul、Etcd、Nacos、Sofa、Zookeeper、Eureka、Redis。 但是在Dubbo3.x版本里面,默认只支持Nacos和Zookeeper两种,其他的注册中心被分离出来作为独立的组件,如果需要用到,则需要单独增加这些组件的依赖。
https://cn.dubbo.apache.org/zh-cn/docs/new-in-dubbo3/#扩展点分离
1.1 Dubbo多注册中心支持
Dubbo 支持同一服务向多注册中心同时注册,或者不同服务分别注册到不同的注册中心上去,甚至可以同时引用注册在不同注册中心上的同名服务。
修改application.properties文件
1 | |
1 | |
在Dubbo3开始,增加了应用级别的服务注册发现,默认情况下,服务端会自动开启接口级和应用级的双重注册,这也是为了兼容Dubbo2.x版本考虑。但是如果生产者和消费者都升级到了Dubbo3,就建议开启应用级别的注册以及关闭接口级的订阅。 可以通过下面这个配置来设置:
1 | |
还可以通过注册中心地址上配置参数registry-type=service来显示指定该注册中心为应用级服务发现的注册中心,带上此配置的注册中心将只进行应用级服务发现:
1 | |
2 服务接口的版本支持
可以通过version这个属性的配置,设置接口或者方法的版本。在进行功能迭代,可能存在新的功能对老版本不兼容的时候,就可以 通过版本号来过度。具体过程是:
- 在低压力时间段,先升级一半提供者为新版本
- 再将所有消费者升级为新版本
- 然后将剩下的一半提供者升级为新版本
1 | |
消费端进行消费的时候,可以在@DubboReference上指定消费的版本号。 如果不需要区分版本号,可以使用version=“*”。
1 | |
3 负载均衡策略
Apache Dubbo不需要像Spring Cloud那样需要单独引入Ribbon或者 LoadBalancer组件来实现负载。 它默认就集成了负载均衡算法,默认的算法是random。
| 算法 | 特性 | 备注 |
|---|---|---|
| Weighted Random | 加权随机 | 默认算法,默认权重相同 |
| RoundRobin | 加权轮询 | 借鉴于Nginx的平滑加权轮询算法,默认权重相同 |
| LeastActive | 最少活跃优先+加权随机 | 背后是能者多劳的思想 |
| Shortest-Response | 最短响应优先+加权随机 | 更加关注响应速度 |
| ConsistentHash | 一致性哈希 | 确定的入参,确定的提供者,适用于有状态请求 |
| P2C | Power of Two Choice | 随机选择两个节点后,继续选择连接数较小的那个节点 |
| Adaptive | 自适应负载均衡 | 在P2C算法基础上,选择两者中load最小的那个节点 |
使用方法:
1 | |
3.1 Weighted
- 加权随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
- 缺点:存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上
3.2 RoundRobin
- 加权轮询,按公约后的权重设置轮询比率,循环调用节点
- 缺点:同样存在慢的提供者累积请求的问题。
加权轮询过程过程中,如果某节点权重过大,会存在某段时间内调用过于集中的问题。 例如 ABC 三节点有如下权重:{A: 3, B: 2, C: 1} 那么按照最原始的轮询算法,调用过程将变成:A A A B B C
对此,Dubbo 借鉴 Nginx 的平滑加权轮询算法,对此做了优化,调用过程可抽象成下表:
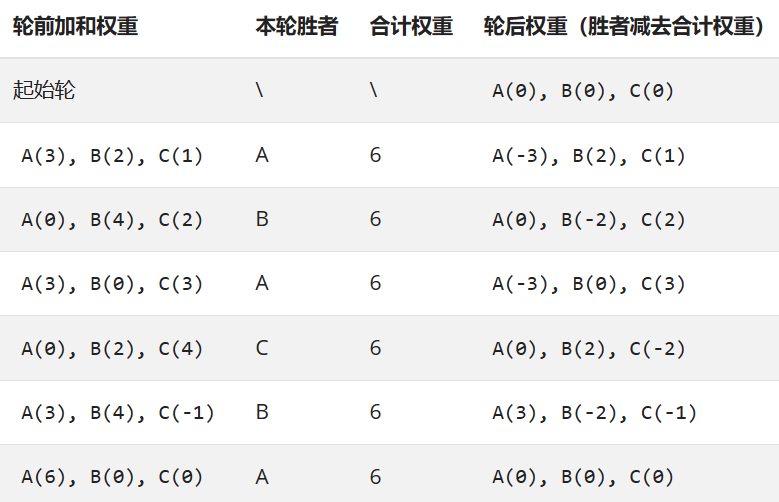
注:轮前加和权重 = 轮后权重 + 节点权重
3.3 LeastActive
- 加权最少活跃调用优先,活跃数越低,越优先调用,相同活跃数的进行加权随机。活跃数指调用前后计数差(针对特定提供者:请求发送数 - 响应返回数),表示特定提供者的任务堆积量,活跃数越低,代表该提供者处理能力越强。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大;相对的,处理能力越强的节点,处理更多的请求。
3.4 ShortestResponse
- 加权最短响应优先,在最近一个滑动窗口中,响应时间越短,越优先调用。相同响应时间的进行加权随机。
- 使得响应时间越快的提供者,处理更多的请求。
- 缺点:可能会造成流量过于集中于高性能节点的问题。
这里的响应时间 = 某个提供者在窗口时间内的平均响应时间,窗口时间默认是 30s。
3.5 ConsistentHash
- 一致性 Hash,相同参数的请求总是发到同一提供者。
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 缺省只对第一个参数 Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" /> - 缺省用 160 份虚拟节点,如果要修改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
3.6 P2C
- 对于每次调用,从可用的provider列表中做两次随机选择,选出两个节点providerA和providerB。
- 比较providerA和providerB两个节点,选择其“当前正在处理的连接数”较小的那个节点。
3.7 Adaptive
Adaptive 即自适应负载均衡,是一种能根据后端实例负载自动调整流量分布的算法实现,它总是尝试将请求转发到负载最小的节点。
4 启动时检查
在Dubbo服务中,难免会出现循环依赖的情况。而Dubbo在启动的时候,会默认去检查依赖的服务状态,并且建立通信连接。因此在这种情况下,就会导致服务无法启动的问题。 Dubbo里面提供了一个check参数,可以通过这个参数来关闭启动检查。
这个参数可以修饰在三个层面:
- @DubboReference ,直接关闭某个服务的启动检查
- dubbo.consumer.check=false,关闭消费端所有服务的启动检查
- dubbo.registry.check=false,关闭注册中心启动时检查
5 容错策略
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
- Failover Cluster:失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过
retries="2"来设置重试次数(不含第一次)。 - Failfast Cluster:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster:失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过
forks="2"来设置最大并行数。 - Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。现在广播调用中,可以通过 broadcast.fail.percent 配置节点调用失败的比例,当达到这个比例后,BroadcastClusterInvoker 将不再调用其他节点,直接抛出异常。 broadcast.fail.percent 取值在 0~100 范围内。默认情况下当全部调用失败后,才会抛出异常。 broadcast.fail.percent 只是控制的当失败后是否继续调用其他节点,并不改变结果(任意一台报错则报错)。
- Available Cluster:调用目前可用的实例(只调用一个),如果当前没有可用的实例,则抛出异常。通常用于不需要负载均衡的场景。
- Mergeable Cluster:将集群中的调用结果聚合起来返回结果,通常和group一起配合使用。通过分组对结果进行聚合并返回聚合后的结果,比如菜单服务,用group区分同一接口的多种实现,现在消费方需从每种group中调用一次并返回结果,对结果进行合并之后返回,这样就可以实现聚合菜单项。
- ZoneAware Cluster:多注册中心订阅的场景,注册中心集群间的负载均衡。