jvm调优
1 常用命令
1. jps—查看java进程
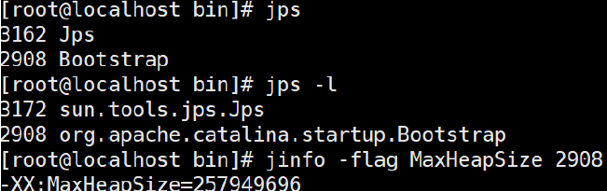
2. jinfo:
(1)实时查看和调整JVM配置参数
(2)用法:jinfo -flag name PID 查看某个java进程的name属性的值
例:jinfo -flag MaxHeapSize PID
jinfo -flag UseG1GC PID
(3)修改:参数只有被标记为manageable的flags可以被实时修改
例:jinfo -flag [+|-] PID
jinfo -flag
(4)查看曾今赋过值的一些参数
jinfo -flags PID
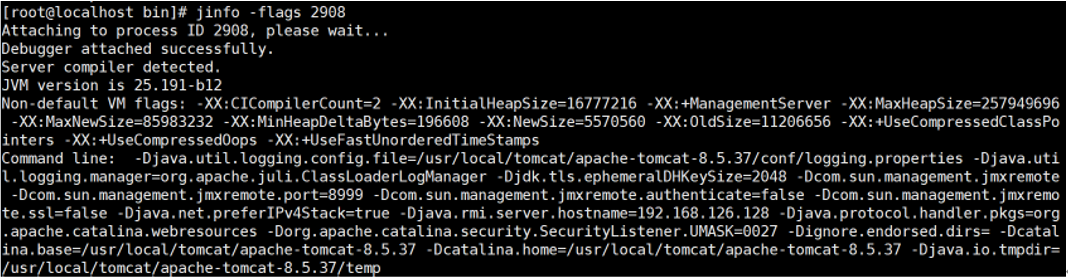
3. jstat
(1)查看虚拟机性能统计信息
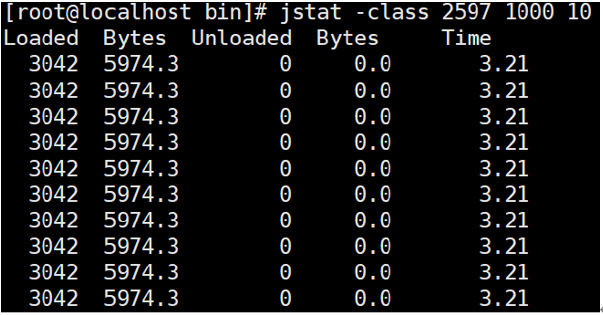
(2)查看类装载信息:
jstat -class PID 1000 10 查看某个java进程的类装载信息,每1000毫秒输出一次,共输出10次
(3)查看垃圾收集信息 :jstat -gc PID 1000 10
4. jstack
(1)查看线程堆栈信息
(2)用法:jstack PID
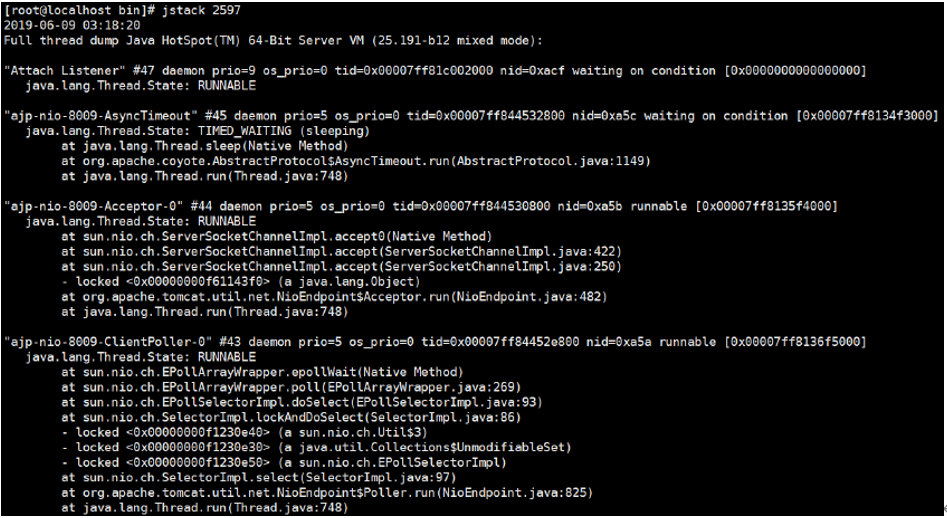
(3)排查死锁案例
1 | |

jstack分析:
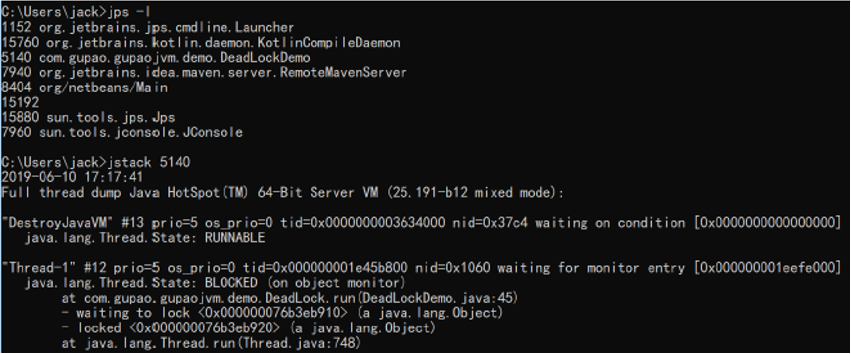
把打印信息拉到最后发现
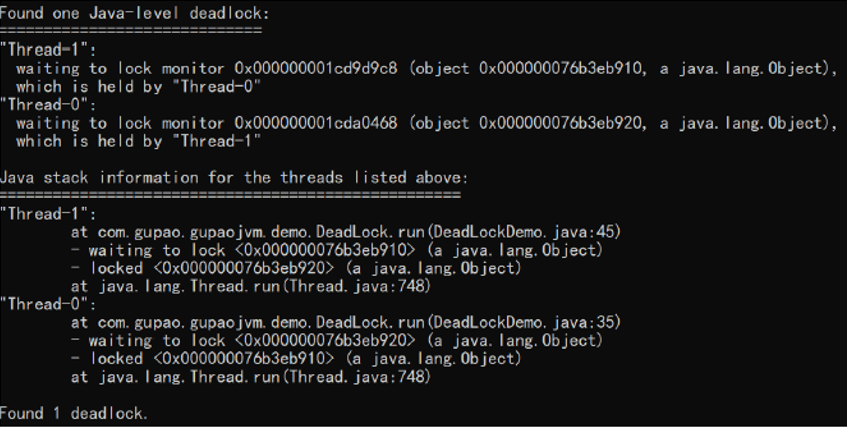
5. jmap
(1)生成堆转储快照
(2)打印出堆内存相关信息
jmap -heap PID
jinfo -flag UsePSAdaptiveSurvivorSizePolicy 35352
-XX:SurvivorRatio=8
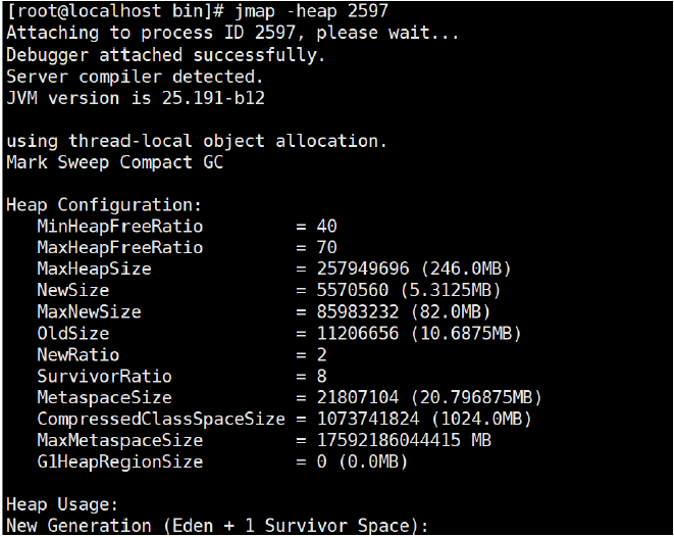
(3)dump出堆内存相关信息
jmap -dump:format=b,file=heap.hprof PID

(4)要是在发生堆内存溢出的时候,能自动dump出该文件就好了
一般在开发中,JVM参数可以加上下面两句,这样内存溢出时,会自动dump出该文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.hprof
设置堆内存大小: -Xms20M -Xmx20M
启动,然后访问localhost:9090/heap,使得堆内存溢出
2 执行引擎
Person.java源码文件是Java这门高级开发语言,对程序员友好,方便我们开发。
javac编译器将Person.java源码文件编译成class文件[我们把这里的编译称为前期编译],交给JVM运行,因为JVM只能认识class字节码文件。同时在不同的操作系统上安装对应版本的JDK,里面包含了各自屏蔽操作系统底层细节的JVM,这样同一份class文件就能运行在不同的操作系统平台之上,得益于JVM。这也是Write Once,Run Anywhere的原因所在。
最终JVM需要把字节码指令转换为机器码,可以理解为是0101这样的机器语言,这样才能运行在不同的机器上,那么由字节码转变为机器码是谁来做的呢?说白了就是谁来执行这些字节码指令的呢?这就是执行引擎。
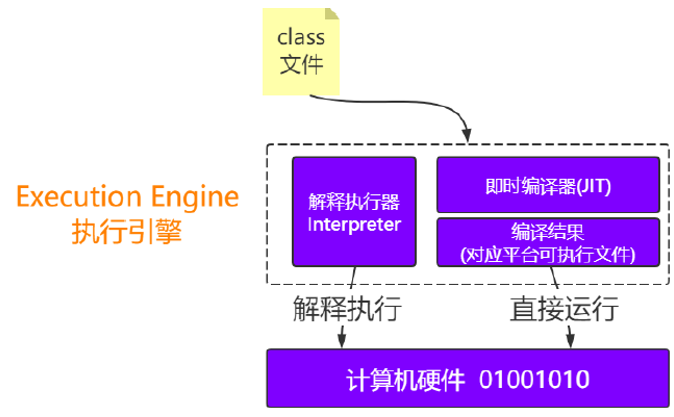
1. 解释执行
Interpreter,解释器逐条把字节码翻译成机器码并执行,跨平台的保证。 刚开始执行引擎只采用了解释执行的,但是后来发现某些方法或者代码块被调用执行的特别频繁时,就会把这些代码认定为“热点代码”。
2. 即时编译器
Just-In-Time compilation(JIT),即时编译器先将字节码编译成对应平台的可执行文件,运行速度快。即时编译器会把这些热点代码编译成与本地平台关联的机器码,并且进行各层次的优化,保存到内存中。
3. JVM采用哪种方式
JVM采取的是混合模式,也就是解释+编译的方式,对于大部分不常用的代码,不需要浪费时间将其编译成机器码,只需要用到的时候再以解释的方式运行;对于小部分的热点代码,可以采取编译的方式,追求更高的运行效率。
4. 即时编译器类型
(1)HotSpot虚拟机里面内置了两个JIT:C1和C2
C1也称为Client Compiler,适用于执行时间短或者对启动性能有要求的程序
C2也称为Server Compiler,适用于执行时间长或者对峰值性能有要求的程序
(2)Java7开始,HotSpot会使用分层编译的方式
也就是会结合C1的启动性能优势和C2的峰值性能优势,热点方法会先被C1编译,然后热点方法中的热点会被C2再次编译。
5. AOT和Graal VM
(1)AOT
在Java9中,引入了AOT(Ahead-Of-Time)编译器,即时编译器是在程序运行过程中,将字节码翻译成机器码。而AOT是在程序运行之前,将字节码转换为机器码。
优势:这样不需要在运行过程中消耗计算机资源来进行即时编译
劣势:AOT 编译无法得知程序运行时的信息,因此也无法进行基于类层次分析的完全虚方法内联,或者基于程序 profile 的投机性优化(并非硬性限制,我们可以通过限制运行范围,或者利用上一次运行的程序 profile 来绕开这两个限制)
(2)Graal VM
官网:https://www.oracle.com/tools/graalvm-enterprise-edition.html
在Java10中,新的JIT编译器Graal被引入
它是一个以Java为主要编程语言,面向字节码的编译器。跟C++实现的C1和C2相比,模块化更加明显,也更加容易维护。
Graal既可以作为动态编译器,在运行时编译热点方法;也可以作为静态编译器,实现AOT编译。
除此之外,它还移除了编程语言之间的边界,并且支持通过即时编译技术,将混杂了不同的编程语言的代码编译到同一段二进制码之中,从而实现不同语言之间的无缝切换。
3 工具
3.1 jconsole
jconsole工具是JDK自带的可视化监控工具。查看java应用程序的运行概况、监控堆信息、永久区使用情况、类加载情况等。命令行中输入:jconsole。
3.2 jvisualvm
命令行中输入:jvisualvm。Visual GC插件下载地址:https://visualvm.github.io/pluginscenters.html。
监控本地进程:可以监控本地的java进程的CPU,类,线程等
监控远端java进程:
1)在visualvm中选中“远程”,右击“添加”
2)主机名上写服务器的ip地址,比如39.100.39.63,然后点击“确定”
3)右击该主机”39.100.39.63”,添加“JMX”,就是通过JMX技术具体监控远端服务器哪个Java进程
4)要想让服务器上的tomcat被连接,需要改一下Catalina.sh这个文件。
注意下面的8998不要和服务器上其他端口冲突。
5)在../conf文件中添加两个文件jmxremote.access和jmxremote.password
jmxremote.access:guest readonly
manager readwrite
jmxremote.password:guest guest
manager manager
授予权限:chmod 600 jmxremot
6)将连接服务器地址改为公网ip地址
7)设置上述端口对应的阿里云安全策略和防火墙策略
8)启动tomcat,来到bin目录:./startup.sh
9)查看tomcat启动日志以及端口监听
tail -f ../logs/catalina.out lsof -i tcp:8080
10)查看8998监听情况,可以发现多开了几个端口
lsof -i:8998 得到PID netstat -antup | grep PID
11)在刚才的JMX中输入8998端口,并且输入用户名和密码则登录成功
3.3 arthas
https://github.com/alibaba/arthas
Arthas 是Alibaba开源的Java诊断工具,采用命令行交互模式,是排查jvm相关问题的利器。
(1)下载安装
1 | |
(2)常用命令
1 | |
3.4 内存分析
- MAT
Java堆分析器,用于查找内存泄漏。Heap Dump,称为堆转储文件,是Java进程在某个时间内的快照。它在触发快照的时候保存了很多信息:Java对象和类信息。通常在写Heap Dump文件前会触发一次Full GC。
下载地址 :https://www.eclipse.org/mat/downloads.php
1)获取dump文件
手动:jmap -dump:format=b,file=heap.hprof 44808
自动:-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.hprof
2)使用
Histogram:可以列出内存中的对象,对象的个数及其大小
Class Name:类名称,java类名
Objects:类的对象的数量,这个对象被创建了多少个
Shallow Heap:一个对象内存的消耗大小,不包含对其他对象的引用
Retained Heap:是shallow Heap的总和,即该对象被GC之后所能回收到内存的总和
右击类名—>List Objects—>with incoming references—>列出该类的实例
右击Java对象—>Merge Shortest Paths to GC Roots—>exclude all …—>找到GC Root以及原因
Leak Suspects:查找并分析内存泄漏的可能原因
Top Consumers:列出大对象
3.5 GC日志分析
要想分析日志的信息,得先拿到GC日志文件才行。比如打开windows中的catalina.bat,在第一行加上
XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps
-Xloggc:$CATALINA_HOME/logs/gc.log
1.不同收集器的日志
这样使用startup.bat启动tomcat的时候就能够在当前目录下拿到gc.log文件,可以看到默认使用的是ParallelGC。
(1)Parallel GC 吞吐量优先
【2019-06-10T23:21:53.305+0800: 1.303: [GC (Allocation Failure) [PSYoungGen:65536K[Young区回 收前]->10748K[Young区回收后]76288K[Young区总大小]] 65536K[整个堆回收前]->15039K[整个堆回 收后]251392K[整个堆总大小], 0.0113277 secs] [Times:user=0.00 sys=0.00, real=0.01 secs]】
注意如果回收的差值中间有出入,说明这部分空间是Old区释放出来的。
(2)CMS 停顿时间优先
参数设置:-XX:+UseConcMarkSweepGC -Xloggc:cms-gc.log
重启tomcat获取gc日志,这里的日志格式和上面差不多,不作分析。
(3)G1 停顿时间优先
G1日志格式参考链接:https://blogs.oracle.com/poonam/understanding-g1-gc-logs。
参数设置:-XX:+UseG1GC -Xloggc:g1-gc.log
-XX:+UseG1GC # 使用了G1垃圾收集器
# 什么时候发生的GC,相对的时间刻,GC发生的区域young,总共花费的时间,0.00478s,
# It is a stop-the-world activity and all
# the application threads are stopped at a safepoint during this time.
2019-12-18T16:06:46.508+0800: 0.458: [GC pause (G1 Evacuation Pause)(young), 0.0047804 secs]
# 多少个垃圾回收线程,并行的时间
[Parallel Time: 3.0 ms, GC Workers: 4]
# GC线程开始相对于上面的0.458的时间刻
[GC Worker Start (ms): Min: 458.5, Avg: 458.5, Max: 458.5, Diff: 0.0]
# This gives us the time spent by each worker thread scanning the roots
# (globals, registers, thread stacks and VM data structures).
[Ext Root Scanning (ms): Min: 0.2, Avg: 0.4, Max: 0.7, Diff: 0.5, Sum: 1.7]
# Update RS gives us the time each thread spent in updating the RememberedSets.
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
…
# 主要是Eden区变大了,进行了调整
[Eden: 14.0M(14.0M)->0.0B(16.0M) Survivors: 0.0B->2048.0K Heap: 14.0M(256.0M)->3752.5K(256.0M)]
- GCViewer
java -jar gcviewer-1.36-SNAPSHOT.jar
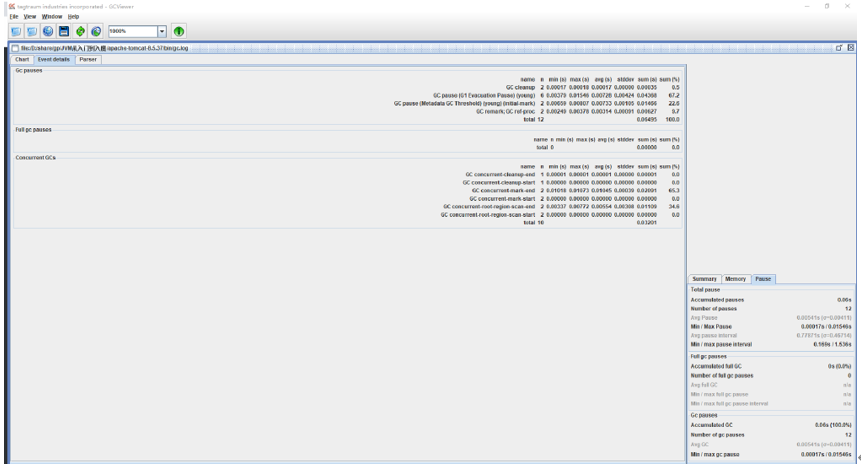
gceasy : http://gceasy.io

gcplot https://it.gcplot.com/
4 性能优化
4.1 内存
- 内存分配
正常情况下不需要设置,那如果是促销或者秒杀的场景呢?
每台机器配置2c4G,以每秒3000笔订单为例,整个过程持续60秒
- 内存溢出,一般会有两个原因:
(1)大并发情况下
(2)内存泄露导致内存溢出
3. 大并发【秒杀】
浏览器缓存、本地缓存、验证码
CDN静态资源服务器
集群+负载均衡
动静态资源分离、限流[基于令牌桶、漏桶算法]
应用级别缓存、接口防刷限流、队列、Tomcat性能优化
异步消息中间件
Redis热点数据对象缓存
分布式锁、数据库锁
5分钟之内没有支付,取消订单、恢复库存等
4. 内存泄漏导致内存溢出
ThreadLocal引起的内存泄露,最终导致内存溢出
1 | |
(1)上传到阿里云服务器
jvm-case-0.0.1-SNAPSHOT.jar
(2)启动
java -jar -Xms1000M -Xmx1000M -XX:+HeapDumpOnOutOfMemoryError -
XX:HeapDumpPath=jvm.hprof jvm-case-0.0.1-SNAPSHOT.jar
(3)使用jmeter模拟10000次并发
39.100.39.63:8080/tl
(4)top命令查看
top
top -Hp PID
(5)jstack查看线程情况,发现没有死锁或者IO阻塞的情况
jstack PID
java -jar arthas.jar —> thread
(6)查看堆内存的使用,发现堆内存的使用率已经高达88.95%
jmap -heap PID
java -jar arthas.jar —> dashboard
(7)此时可以大体判断出来,发生了内存泄露从而导致的内存溢出,那怎么排查呢?
jmap -histo:live PID | more
获取到jvm.hprof文件,上传到指定的工具分析,比如heaphero.io
4.2 GC(这里以G1垃圾收集器调优为例)
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/G1.html#use_cases
(1)50%以上的堆被存活对象占用
(2)对象分配和晋升的速度变化非常大
(3)垃圾回收时间比较长
G1调优
(1)使用G1GC垃圾收集器: -XX:+UseG1GC
修改配置参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(2)调整内存大小再获取gc日志分析
-XX:MetaspaceSize=100M
-Xms300M
-Xmx300M
比如设置堆内存的大小,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(3)调整最大停顿时间
-XX:MaxGCPauseMillis=200 设置最大GC停顿时间指标
比如设置最大停顿时间,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(4)启动并发GC时堆内存占用百分比
-XX:InitiatingHeapOccupancyPercent=45
G1用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比例。值为 0 则表示 “一直执行GC循环)’. 默认值为 45 (例如, 全部的 45% 或者使用了45%).
比如设置该百分比参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间

G1调优最佳实战
官网:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html#recommendations
(1)不要手动设置新生代和老年代的大小,只要设置整个堆的大小
why:https://blogs.oracle.com/poonam/increased-heap-usage-with-g1-gc
G1收集器在运行过程中,会自己调整新生代和老年代的大小,其实是通过adapt代的大小来调整对象晋升的速度和年龄,从而达到为收集器设置的暂停时间目标,如果手动设置了大小就意味着放弃了G1的自动调优
(2)不断调优暂停时间目标
一般情况下这个值设置到100ms或者200ms都是可以的(不同情况下会不一样),但如果设置成50ms就不太合理。暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。暂停时间只是一个目标,并不能总是得到满足。
(3)使用-XX:ConcGCThreads=n来增加标记线程的数量
IHOP如果阀值设置过高,可能会遇到转移失败的风险,比如对象进行转移时空间不足。如果阀值设置过低,就会使标记周期运行过于频繁,并且有可能混合收集期回收不到空间。IHOP值如果设置合理,但是在并发周期时间过长时,可以尝试增加并发线程数,调高ConcGCThreads。
(4)MixedGC调优
-XX:InitiatingHeapOccupancyPercent
-XX:G1MixedGCLiveThresholdPercent
-XX:G1MixedGCCountTarger
-XX:G1OldCSetRegionThresholdPercent
(5)适当增加堆内存大小
(6)不正常的Full GC
有时候会发现系统刚刚启动的时候,就会发生一次Full GC,但是老年代空间比较充足,一般是由Metaspace区域引起的。可以通过MetaspaceSize适当增加其大家,比如256M。
4.3 CPU占用率高
(1)top
(2)top -Hp PID
查看进程中占用CPU高的线程id,即tid
(3)jstack PID | grep tid
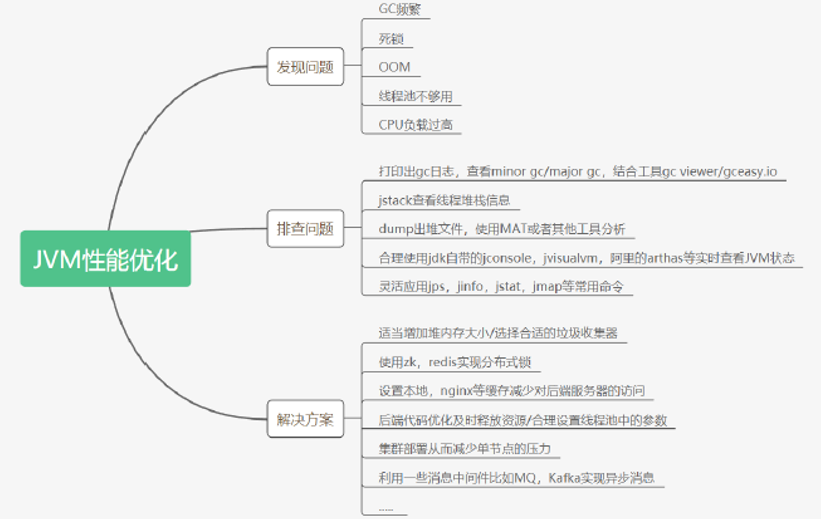
5 JVM性能优化指南
6 常见问题
- 内存泄漏与内存溢出的区别
内存泄漏是指不再使用的对象无法得到及时的回收,持续占用内存空间,从而造成内存空间的浪费。
内存泄漏很容易导致内存溢出,但内存溢出不一定是内存泄漏导致的。
- young gc会有stw吗?
不管什么 GC,都会发送 stop-the-world,区别是发生的时间长短。而这个时间跟垃圾收集器又有关系,Serial、PartNew、Parallel Scavenge 收集器无论是串行还是并行,都会挂起用户线程,而 CMS和 G1 在并发标记时,是不会挂起用户线程的,但其它时候一样会挂起用户线程,stop the world 的时间相对来说就小很多了。
- major gc和full gc的区别
Major GC在很多参考资料中是等价于 Full GC 的,也可以发现很多性能监测工具中只有 Minor GC和 Full GC。一般情况下,一次 Full GC 将会对年轻代、老年代、元空间以及堆外内存进行垃圾回收。触发 Full GC 的原因有很多:当年轻代晋升到老年代的对象大小,并比目前老年代剩余的空间大小还要大时,会触发 Full GC;当老年代的空间使用率超过某阈值时,会触发 Full GC;当元空间不足时(JDK1.7永久代不足),也会触发 Full GC;当调用 System.gc() 也会安排一次 Full GC。
- 什么是直接内存
Java的NIO库允许Java程序使用直接内存。直接内存是在java堆外的、直接向系统申请的内存空间。通常访问直接内存的速度会优于Java堆。因此出于性能的考虑,读写频繁的场合可能会考虑使用直接内存。由于直接内存在java堆外,因此它的大小不会直接受限于Xmx指定的最大堆大小,但是系统内存是有限的,Java堆和直接内存的总和依然受限于操作系统能给出的最大内存。
- 垃圾判断的方式
引用计数法:指的是如果某个地方引用了这个对象就+1,如果失效了就-1,当为0就会回收但是JVM没有用这种方式,因为无法判定相互循环引用(A引用B,B引用A)的情况。
引用链法: 通过一种GC ROOT的对象(方法区中静态变量引用的对象等-static变量)来判断,如果有一条链能够到达GC ROOT就说明,不能到达GC ROOT就说明可以回收。
- 不可达的对象一定要被回收吗?
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
- 为什么要区分新生代和老年代?
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
- G1与CMS的区别是什么
CMS 主要集中在老年代的回收,而 G1 集中在分代回收,包括了年轻代的 Young GC 以及老年代的 Mix GC;G1 使用了 Region 方式对堆内存进行了划分,且基于标记整理算法实现,整体减少了垃圾碎片的
产生;在初始化标记阶段,搜索可达对象使用到的 Card Table,其实现方式不一样。
- 方法区中的无用类回收
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。
类需要同时满足下面 3 个条件才能算是 “无用的类” :
a-该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
b-加载该类的 ClassLoader 已经被回收。
c-该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。