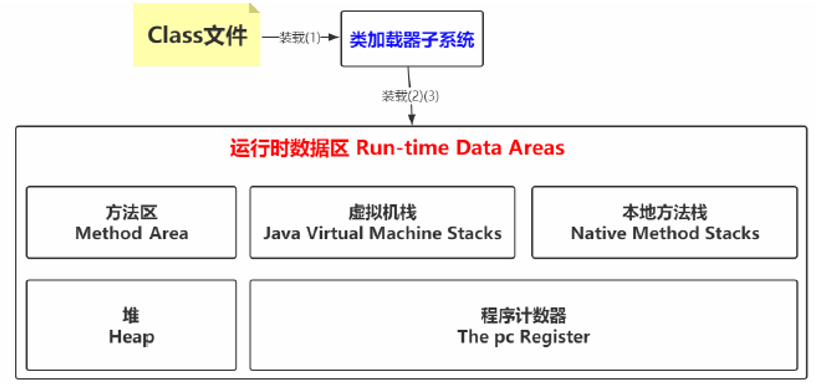
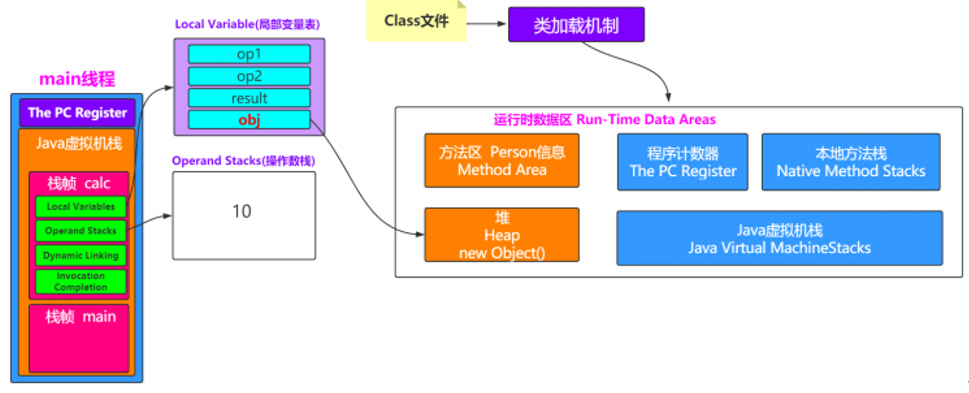
运行时数据区
在加载阶段的第二三步可以发现由运行时数据,堆,方法区等名词。第二步将这个字节流所代表的静态存储机构转化为方法区的运行时数据结构。第三步在java堆中生成一个代表这个类的java.lang.Class对象,作为方法区中这些数据的访问入口。说白了就是类文件被类加载器加载进来之后,类中的内容(比如变量,常量,方法,对象等这些数据得要有个去处,也就是要存起来,存储的位置肯定是JVM中有对应的空间)
1 官网概括
https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
2 图解

3 常规理解
3.1 常量池
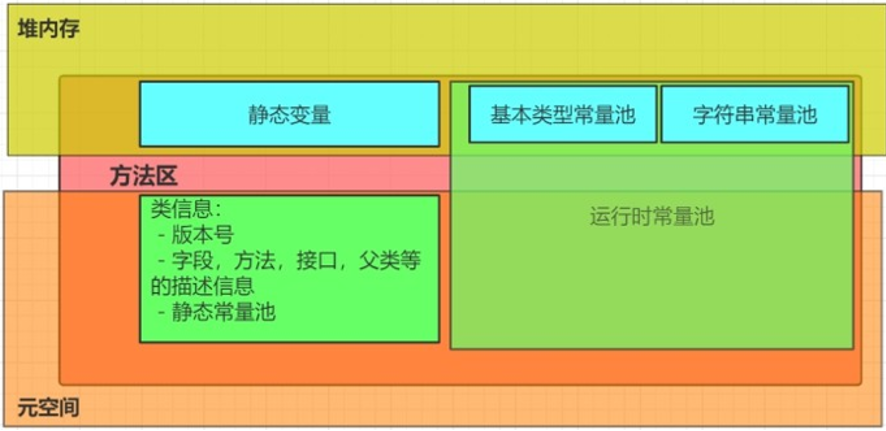
常量池分为静态常量池,运行时常量池,还有字符串常量池。
静态常量池:其实储存的就是字面量以及符号引用。
运行时常量池:运行时常量池就是每个类以及每个接口在JVM进行run的过程中所在内存中开辟出来 的一块用来储存静态常量池部分数据的一块特殊区域。
字符串常量池:包含在动态常量池中。
Jdk8中各常量池在内存中的划分:
3.2 方法区(Method Area)
方法区是各个线程共享的内存区域,在虚拟机启动时创建。用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译后的代码等数据。虽然java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目的是与java堆区分开。当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
此时回看加载阶段的第二步:将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。如果这时候把从class文件到装载的第一二步合并起来理解的话,可以画个图:

方法区在JDK8中就是Metaspace(直接内存,也就是系统内存),在JDK6或7中就是Perm Space。JVM在使用类加载器时会为其分配一个内存列表,会进行线性分配,内存列表的大小取决与类加载器。在GC时1.7之前会对内存列表进行线性卸载,而1.8会对类加载器和其所属的内存列表整个卸载。
3.3 堆(Heap)
java堆是java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。java对象实例以及数组都在堆上分配。此时回看装载阶段的第三步:在java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
3.4 虚拟机栈(Java Virtual Machine Stacks)
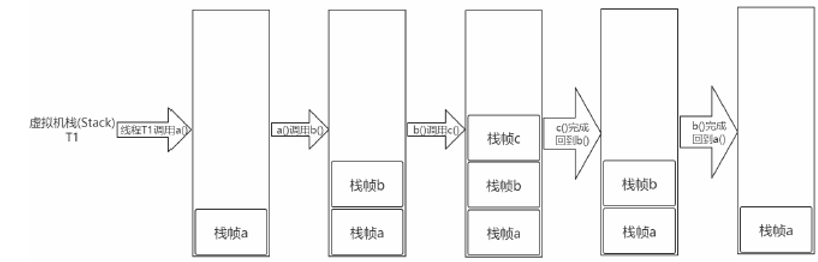
虚拟机栈是一个线程执行的区域,保存着一个线程中方法的调用状态。换句话说,一个java线程的运行状态,由一个虚拟机栈来保存,所以虚拟机栈肯定是线程私有的,独有的,随着线程的创建而创建。每一个被线程执行的方法,为该栈中的栈帧,即每个方法对应一个栈帧。调用一个方法,就会向栈中压入一个栈帧;一个方法调用完成,就会把该栈帧从栈中弹出。
官网:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.6
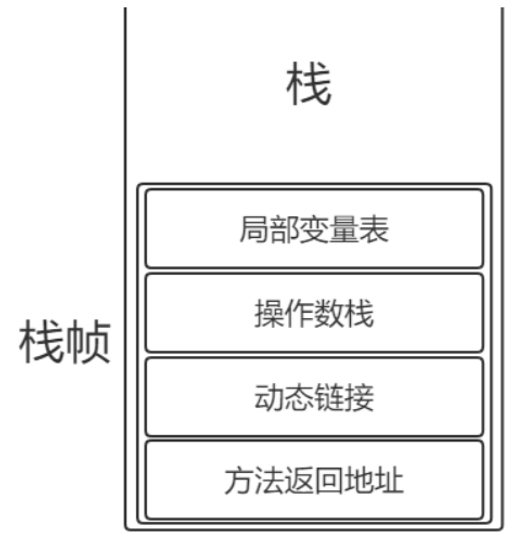
栈帧:每个栈帧对应一个被调用的方法,可以理解为一个方法的运行空间
每个栈帧中包括局部变量表,操作数栈,指向运行时常量池的引用,方法返回地址和附加信息。
(1)局部变量表 Local Variables:方法中定义的局部变量以及方法的参数存放在这张表中,局部变量表中的变量不可直接使用,如需要使用的话,必须通过相关指令将其加载到操作数栈中作为操作数使用。
(2)操作数栈 Operand Stack:以压栈和出栈的方法存储操作数的。
(3)动态链接:每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。可能发生符号引用转为直接引用。
(4)方法返回地址:当一个方法开始执行后,只有两种方式可以退出,一种是遇到方法返回的字节码指令;一种是遇到异常,并且这个异常没有在方法体内得到处理。
3.5 程序计数器(The PC Register)
一个JVM进程中有多个线程在执行,而线程中的内容是否能够拥有执行权,是根据CPU调度来的。加入线程A正在执行到某个地方,突然失去了CPU的执行权,切换到线程B了,然后当线程A再获得CPU执行权的时候,怎么能继续执行?这就是需要在线程中维护一个变量,记录线程执行到的位置。
程序计数器占用的内存空间很小,由于java虚拟机的多线程是通过线程轮流切换,并分配处理器执行时间的方式来实现的。在任意时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能够恢复到正确的执行位置,每条线程需要有一个独立的程序计数器(线程私有)。
如果线程正在执行java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是native方法,则这个计数器为空。
3.6 本地方法栈(Native Method Stacks)
如果当前线程执行的方法是Native类型的,这些方法就会在本地方法栈中执行。
3.7 另外
除了上面五块内存之外,其实JVM还会使用到其他两块内存:
直接内存(Direct Memory):
并不是虚拟机运行时数据区的一部分,也不是JVM规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError 异常出现。在JDK 1.4 中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O 方式,它可以使用Native 函数库直接分配堆外内存,然后通过一个存储在Java 堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能, 因为避免了在Java堆和Native堆中来回复制数据。本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存的大小及处理器寻址空间的限制。因此在分配JVM空间的时候应该考虑直接内存所带来的影响,特别是应用到NIO的场景。
其他内存:
Code Cache:JVM本身是个本地程序,还需要其他的内存去完成各种基本任务,比如,JIT 编译器在运行时对热点方法进行编译,就会将编译后的方法储存在Code Cache里面;GC等功能。需要运行在本地线程之中,类似部分都需要占用内存空间。这些是实现JVM的JIT等功能的需要,但规范中并不涉及。
4 运行时数据区各种元素的引用
4.1 栈指向谁
如果在栈帧中有一个变量,类型为引用类型,比如Object obj=new Object(),这时候就是典型的栈中元素指向堆中的对象。
4.2 方法区指向谁
方法区中会存放静态变量,常量等数据。如果是这种情况,就是典型的方法区中元素指向堆中的对象。
1 | |
4.3 堆指向方法区
方法区中会包含类的信息,堆中会有对象,对象与类进行联系即堆指向方法区
4.4 Java对象内存模型
一个Java对象在内存中包括3个部分:对象头、实例数据和对齐填充。

4.5 验证hashcode的存储方式
使用到jol工具。依赖:
1 | |
1 | |
1 | |
测试结果:
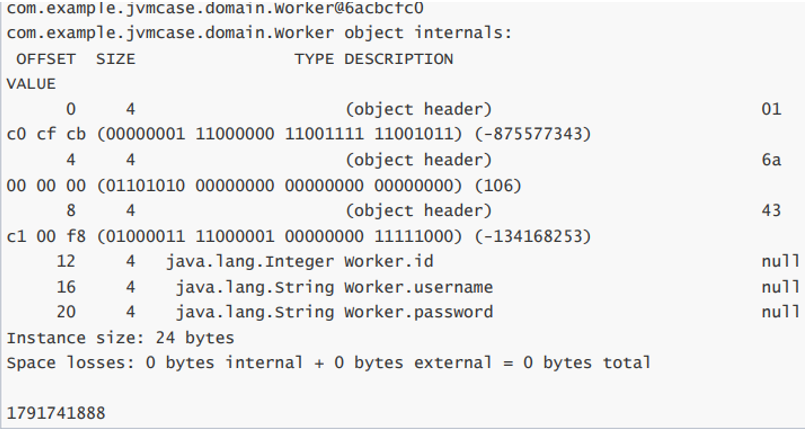
1791741888这个数字是HashCode值,转换成16进制可得6a cb cf c0,经过对比,由此可得哈希码使用的大端储存。
例如:十进制数9877,如果用小端存储表示则为:
高地址 <- - - - - - - - 低地址 10010101[高序字节] 00100110[低序字节]
用大端存储表示则为:
低地址 <- - - - - - - - 高地址 00100110[低序字节] 10010101[高序字节]
小端存储:便于数据之间的类型转换,例如:long类型转换为int类型时,高地址部分的数据可以直接截掉。
大端存储:便于数据类型的符号判断,因为最低地址位数据即为符号位,可以直接判断数据的正负号。
4.6 Class Pointer
引用定位到对象的方式有两种,一种叫句柄池访问,一种叫直接访问。
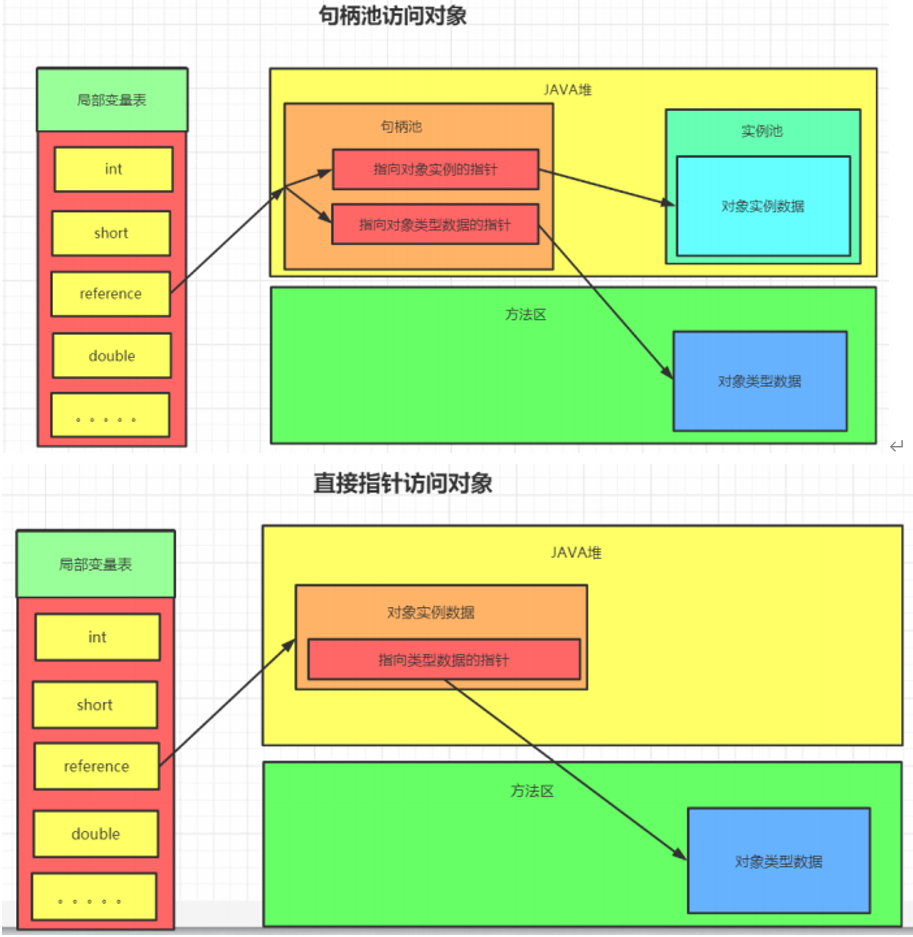
句柄池:
使用句柄访问对象,会在堆中开辟一块内存作为句柄池,句柄中储存了对象实例数据(属性值结构体)的内存地址,访问类型数据的内存地址(类信息,方法类型信息),对象实例数据一般也在heap中开辟,类型数据一般储存在方法区中。
优点:reference存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要改变。
缺点:增加了一次指针定位的时间开销。
直接访问:
直接指针访问方式指reference中直接储存对象在heap中的内存地址,但对应的类型数据访问地址需要在实例中存储。
优点:节省了一次指针定位的开销。
缺点:在对象被移动时(如进行GC后的内存重新排列),reference本身需要被修改。
指针压缩:在32位系统中,类型指针为4字节32位,在64位系统中类型指针为8字节64位,但是JVM会默认的进行指针压缩,所以上图输出结果中类型指针也是4字节32位。如果关闭指针压缩的话,就可以看到64位的类型指针了,所以通常在部署服务时,JVM内存不要超过32G,因为超过32G就无法开启指针压缩了。
关闭指针压缩 : -XX:+UseCompressedOops
对齐填充,没有对齐填充就可能会存在数据跨内存地址区域存储的情况,在没有对齐填充的情况下,内存地址存放情况如下:

因为处理器只能0x00-0x07,0x08-0x0F这样读取数据,所以想获取这个long型的数据时,处理器必须要读两次内存,第一次(0x00-0x07),第二次(0x08-0x0F),然后将两次的结果才能获得真正的数值。
那么在有对齐填充的情况下,内存地址存放情况是这样的:

现在处理器只需要直接一次读取(0x08-0x0F)的内存地址就可以获得想要的数据了。
对齐填充存在的意义就是为了提高CPU访问数据的效率,这是一种以空间换时间的做法;虽然访问效率提高了(减少了内存访问次数),但是在0x07处产生了1bit的空间浪费。但是有一种情况,父类对象的变量是不会加入到子类对象对齐填充的中间去。