Redis常见问题
1 数据一致性问题
1.1 缓存使用场景
针对读多写少的高并发场景,可以使用缓存来提升查询速度。使用redis作为缓存的时候,一般流程是这样的:
- 如果数据在redis存在,应用就可以直接从redis拿到数据,不用访问数据库。

- 应用新增了数据,只保存在数据库中,这个时候redis没有这条数据。如果redis里面没有,先到数据库查询,然后写入到redis,再返回给应用。

1.2 一致性问题的定义
因为数据最终是以数据库为准的(这是原则),如果redis没有数据,就不存在这个问题。当redis和数据库都有同一条记录,而这条记录发生变化的时候,就可能出现一致性问题。一旦被缓存的数据发生变化(比如修改,删除)的时候,既要操作数据库的数据,也要操作redis的数据,才能让redis和数据库保持一致。所以问题来了。现在有两种选择:
1.先操作redis的数据再操作数据库的数据
2.先操作数据库的数据再操作redis的数据
首先需要明确的是,不管选择哪一种方案,肯定是希望两个操作要么都成功,要么都不成功。但是,redis的数据和数据库是不可能通过事务达到统一的,只能根据相应的场景和所需要付出的代价来采取一些措施降低数据不一致的问题出现的概率,在数据一致性和性能之间取得一个权衡。
比如,对于数据库的实时性一致性要求不是特别高的场合,比如T+1的报表,可以采用定时任务查询数据库数据同步到redis的方案。由于是以数据库的数据为准的,所以给缓存设置一个过期时间,删除redis的数据,也能保证最终一致性。既然提到了Redis和数据库一致性的问题,一般是希望尽可能靠近实时一致性,操作延迟带来的不一致的时间越少越好。
1.3 方案选择
1.3.1 redis:删除还是更新?
这里补充一点:当存储的数据发生变化,redis的数据也要更新的时候,有两种方案,一种就是直接更新redis数据,调用set;还有一种是直接删除redis数据,让应用在下次查询的时候重新写入。
更新缓存之前,是不是要经过其他表的查询,接口调用,计算才能得到最新的数据,而不是直接从数据库拿到的值。如果是的话,建议直接删除,这种方案更加简单,而且避免了数据库的数据和缓存不一致的情况。在一般情况下,也推荐使用删除的方案。所以,更新操作和删除操作,只要数据变化,都用删除。
1.3.2 先更新数据库,再删除缓存
正常情况:更新数据库成功,删除缓存成功。
异常情况:
1. 更新数据库失败,程序捕获异常,不会走到下一步,数据不会出现不一致。
2. 更新数据成功,删除缓存失败。数据库是新数据,缓存是旧数据,发生了不一致的情况。
对于这个问题,可以提供一个重试机制。比如:如果删除缓存失败,捕获这个异常,把需要删除的key发送到消息队列。然后自己创建一个消费者消费,尝试再次删除这个key。这种方式有个缺点,会对业务代码造成入侵。
所以有了第二种方案(异步更新缓存):因为更新数据库时会往binlog写入日志,所以可以通过一个服务来监听binlog的变化(比如阿里的canal),然后在客户端完成删除key的操作。如果删除失败的话,在发送到消息队列。https://gper.club/articles/7e7e7f7ff3g59gc6g6d (canal)。总之,对于后删除缓存失败的情况,我们的做法是不断地重试删除,直到成功。无论是重试还是异步删除,都是最终一致性地思想。
1.3.3 先删除缓存,再更新数据库
正常情况:删除缓存成功,更新数据库成功。
异常情况:
1.删除缓存,程序捕获异常,不会走到下一步,数据不会出现不一致。
2.删除缓存成功,更新数据库失败。因为以数据库的数据为准,所以不存在数据不一致的情况。
看起来好像没有问题,但是如果有程序并发操作的情况下:
1)线程A需要更新数据,首先删除了redis缓存
2)线程B查询数据,发现缓存不存在,到数据库查询旧值,写入redis,返回
3)线程A更新了数据库
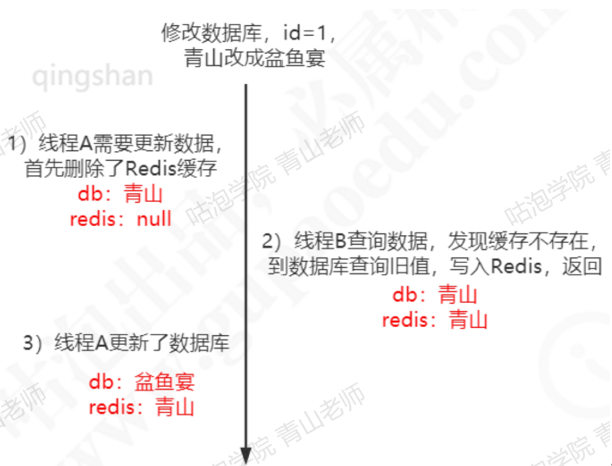
这个时候,redis 是旧值,数据库是新的值,发生了数据不一致的情况。
这个是由线程并发造成的问题,能不能让对同一条数据的访问串行化呢?代码肯定保证不了,因为有多个线程,即使做了任务队列也可能有多个应用实例(应用做了集群部署)。数据库也保证不了,因为会有多个数据库的连接。只有一个数据库只提供一个连接的情况下,才能保证读写的操作的串行的,或者我们把所有的读写请求放到同一个内存队列当中,但是强制串行操作,吞吐量太低了。
所以有一种延时双删的策略,在写入数据之后,再删除一次缓存。
A线程:1)删除缓存。 2)更新数据库。 3)休眠500ms(这个时间,依据读取数据的耗时而定)。 4)再次删除缓存。 伪代码:
1 | |
2 高并发问题
在redis存储的所有数据中,有一部分是被频繁访问的。有两种情况可能会导致热点问题的产生,一个是用户集中访问的数据,比如抢购商品,明星结婚和明星出轨的微博。还有一种就是在数据进行分片的情况下,负载不均衡,超过了单个服务器的承受能力。热点问题可能引起缓存服务的不可用,最终造成压力堆积到数据库。出于存储和流量优化的角度,必须要找到这些热点数据。
2.1 热点数据发现
2.1.1 客户端
比如可不可以在所有调用了get,set方法的地方,加上key的计数。但是这样的话,每一个地方都要修改,重复代码也多。如果用的是Jedis的客户端,可以修改Jedis的源码,在jedis的connection类的sendCommand()里面,用一个HashMap进行key的计数。但是这种方式有几个问题:
1.会对客户端的代码造成入侵
2.不知道要存多少个key,可能发生内存泄漏的问题。
3.只能统计当前客户端的热点key。
2.1.2 代理层
第二种方式就是在代理层实现,比如TwemProxy或者Codis,但是不是所有的项目都使用了代理的架构。
2.1.3 服务端
第三种就是在服务端统计,redis有一个monitor的命令,可以监控到所有redis执行的命令。
1 | |
Facebook的开源项目redis-faina就是基于这个原理实现的。它是一个python脚本,可以分析monitor的数据。
https://github.com/facebookarchive/redis-faina.git
这种方法也会有两个问题:1)monitor命令在高并发的场景下,会影响性能,所以不适合长时间使用。2)只能统计一个redis节点的热点key。
2.1.4 机器层面
还有一种方法就是机器层面的,通过对TCP协议进行抓包,也有一些开源的方案,比如ELK的packetbeat插件。发现了热点key之后,来看下热点数据在高并发的场景下可能会出现的问题,以及怎么去解决。
2.2 缓存雪崩
2.2.1 什么是缓存雪崩
缓存雪崩就是Redis的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候redis请求的并发量又很大,就会导致所有的请求落到数据库。
2.2.2 缓存雪崩的解决方案
1)加互斥锁或者使用队列,针对同一个key只允许一个线程到数据库查询
2)缓存定时预先更新,避免同时失效
3)通过加随机数,使得key在不同的时间过期
4)缓存永不过期
2.3 缓存穿透
2.3.1 缓存穿透何时发生

在这里redis起到了提升查询速度和保护数据库的作用。还有一种情况,数据在数据库和redis里面都不存在,可能是一次条件错误的查询。在这种情况下,因为数据库值不存在,所以肯定不会写入redis,那么下一次查询相同的key的时候,肯定还是会再到数据库查一次。那么这种循环查询数据库中不存在的值,并且每次使用的是相同的key的情况,该怎么避免应用到数据库查询?
(1)缓存空数据 (2)缓存特殊字符串,比如&&
可以在数据库缓存一个空字符串,或者缓存一个特殊的字符串。那么在应用里面拿到这个特殊字符串的时候,就知道数据库没有值了,也没有必要再到数据库查询了。但是这里需要设置一个过期时间,不然的话数据库已经新增了这一条记录,应用也还是拿不到值。
这个是应用重复查询同一个不存在的值的情况,如果应用每一次查询的不存在的值是不一样的?即使每次都缓存特殊字符串也没用,因为它的值不一样,比如我们的用户系统登陆的场景,如果是恶意的请求,它每次都生成了一个符合ID规则的账号,但是这个账号在数据库是不存在的,那redis就完全失去了作用。这种因为每次查询的值都不存在导致的redis失效的情况,应该怎么去解决?
2.3.2 经典面试题
其实它也是一个通用的问题,关键就在于怎么知道请求的key在数据库中是否存在,如果数据量特别大的话,怎么去快速判断。
这也是一个非常经典的面试题:如何在海量元素中(例如10亿无序,不定长,不重复)快速判断一个元素是否存在?
如果是缓存穿透的这个问题,要避免到数据库查询不存在的数据,肯定要把这10亿放在别的地方。为了加快检索速度,要把数据放到内存里面来判断,问题来了:如果直接把这些元素的值放到基本的数据结构(List,Map,Tree)里面,比如一个元素一字节的字段,10亿的数据大概需要900G的内存空间,这个对于普通的服务器来说是承受不了的。所以,存储着几十亿个元素,不能直接存值,应该找到一种最简单的最节省空间的数据结构,用来标记这个元素有没有出现。(比如签到表顺序打勾)
这个东西叫做位图,它是一个有序的数组,只有两个值,0和1:0代表不存在,1代表存在。

对于这个映射方法,有几个基本的要求:
1)因为值长度是不固定的,希望不同长度的输入,可以得到固定长度的输出。
2)转换成下标的时候,希望他在我的这个有序数组里面是分布均匀的,不然的话全部挤到一对去了,也没办法判断哪个元素存了,哪个元素没存。
这个就是哈希函数,比如MD5,SHA-1等等这些都是常见的哈希算法。
比如这6个元素,经过哈希函数和位运算,得到了相应的下标。

2.3.3 哈希碰撞
这个时候,Tom和Mic经过计算得到的哈希值是一样的,那么再经过位运算得到的下标肯定是一样的,把这种情况叫做哈希冲突或者哈希碰撞。如果发生过了哈希碰撞,这个时候对于容器存值肯定是由影响的,从数据结构和映射方法这两个角度来分析,可以通过哪些方式去降低哈希碰撞的概率呢?
第一种是扩大数组的长度或者说位图容量。因为函数是分布均匀的,所以,位图容量越大,再同一位置发生哈希碰撞的概率越小。是不是位图的容量越大越好?不管存多少个元素,都创建一个几万亿大小的位图,可以吗?当然不行,因为越大的位图容量,意味着越多的内存消耗,所以要建立一个合适大小的位图容量。
除了扩大位图容量,还有第二种方法,只用一个哈希函数,现在对于每一个要存储的元素都用多个哈希函数计算,这样每次计算出来的下标都相同的概率就小很多了。
同样的,可以引入很多个哈希函数,也会有问题,第一个就是它会填满位图的更多空间,第二个是计算是需要消耗时间的。
所以总的来说,既要节省空间,又要很高的计算效率,就必须在位图容量和函数个数之间找到一个最佳的平衡。
2.3.4 布隆过滤器(BF)原理
当然,这个事情早就有人研究过了,在1970年的时候,有一个叫做布隆的前辈对于判断海量元素中元素是否存在的问题进行了研究,也就是到底需要多大的位图容量和多少个哈希函数,提出的这个容器就叫做布隆过滤器。
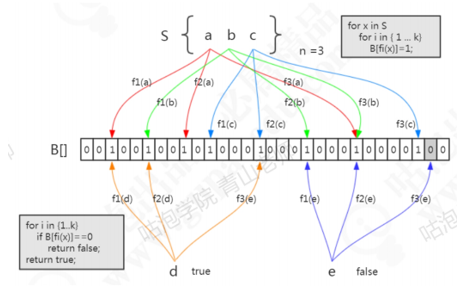
布隆过滤器的工作原理:首先,布隆过滤器的本质就是刚才分析的,一个位数组码和若干个哈希函数。

集合中有三个元素,要把它存到布隆过滤器中去,怎么做?首先是a元素,这里用3次计算。b,c元素也一样。元素已经存进去之后,现在要来判断一个元素在这个容器里面是否存在,就要使用同样的三个函数进行计算。比如d元素,用第一个函数f1计算,发现这个位置上是1,没问题。第二个位置也是1,第三个位置也是1.如果经过三次计算得到的下标位置都是1,这种情况下,能不能确定d元素一定在这个容器中呢?实际上是不能的。比如这张图里面,这三个位置分别是把abc存进去的时候置成1的,所以即使d元素之前没有存进去,也会得到1,判断返回true。
所以,这个是布隆过滤器的一个很重要的特性,因为哈希碰撞不可避免,所以它会存在一定的误判率。这种把本来不存在布隆过滤器中的元素误判为存在的情况,把它叫做假阳性(False Positive Probability,FPP)。
再来看另一个元素,e元素。要判断它在容器中是否存在,一样的要用这三个函数去计算。第一个位置是1,第二个位置是1,第三个位置是0。E元素是不是一定不在这个容器中呢?可以确定一定不存在,如果说但是已经把e元素存到布隆过滤器中去了,那么这三个位置肯定是1,不会出现0.
总结,布隆过滤器的特点;
从容器的角度来说:
如果布隆过滤器判断元素在集合中存在,不一定存在
如果布隆过滤器判断不存在,一定不存在
从元素的角度来说:
如果元素实际存在,布隆过滤器一定判断存在
如果元素实际不存在,布隆过滤器可能判断存在
2.3.5 Guava BF实现
谷歌的Guava中就提供了一个现成的布隆过滤器。
1 | |
创建布隆过滤器
1 | |
布隆过滤器提供的存放元素的方法是put()。布隆过滤器提供的判断元素是否存在的方法是mightContain().
1 | |
布隆过滤器把误判率默认设置位0.03,也可以在创建的时候指定。
1 | |
位图的容量是基于元素个数和误判率计算出来的
1 | |
根据位图数组的大小,进一步计算出了哈希函数的个数
1 | |
存储100万个元素只占用了0.87M的内存,生成了5个哈希函数。
2.3.6 bf在项目中的使用
布隆过滤器的工作位置
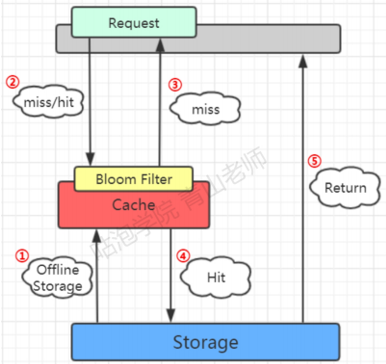
因为要判断数据库的值是否存在,所以第一步是加载数据库所有的数据。在去redis查询之前,现在布隆过滤器查询,如果bf说没有,那数据库肯定没有,也不用去查了。如果bf说有,才走之前的流程。
2.3.7 布隆过滤器的不足与变种
如果数据库删除了,布隆过滤器的数据也要删除。但是布隆过滤器里面没有提供删除的方法。为什么布隆过滤器不提供删除的方法呢?或者说,如果删除了布隆过滤器的元素,会发生什么问题?
比如把a删除了,那么三个位置都要改成0,但是再来判断b元素是否存在的时候,因为有一个位置变成了0,所以b元素也判断不存在。就是因为存在哈希碰撞,所以元素只能存入,不能删除。
那如果要实现删除的功能,怎么做?类似于HashMap的链地址法,可以在每个下标位置上增加一个计数器。比如这个位置命中了两次,计数器就是2。当删除a元素的时候,先把计数器改成1,删除b元素的时候,计数器变成0,这个时候下标对应的位才置成0。
实际上在布隆过滤器提出来的几十年中,出现了很多布隆过滤器的变种,这种通过计数器提供删除功能的bf叫做Counting Bloom Filter
2.3.8 布隆过滤器的其他应用场景
布隆过滤器解决的问题是如何在海量元素中快速判断一个元素是否存在。所以除了解决缓存穿透的问题之外,还有很多其他的用途。
比如爬虫,爬过的url不需要重复爬,那么在几十亿的url中,怎么判断一个url是不是已经爬过了?还有邮箱服务器,发送垃圾邮件的账号把它们叫做spamer,在这么多的邮箱账号中,怎么判断一个账号是不是spamer?等等一些场景,都可以使用到布隆过滤器。