Redis哨兵(Sentinel)
1 原理
怎么实现高可用?第一个对于服务器来说,能够实现主从自动切换;第二个,对于客户端来说,如果发生了主从切换,它需要获取最新的master节点。这个怎么实现呢?这里面应该要有一个管理redis节点状态的角色,而且具备路由功能。比如RocketMQ是通过nameserver来实现的。思路:创建一台监控服务器来监控所有redis服务节点的状态,比如,master节点超过一定时间没有给监控服务器发送心跳报文,就把master标记为下线,之后把某一个slave变成master,应用每一次都是从这个监控服务器拿到master的地址。
Redis的高可用是通过哨兵Sentinel来保证的。它的思路就是通过运行监控服务器来保证服务的可用性。从redis2.8版本起,提供了一个稳定版本的哨兵,用来解决高可用的问题。我们会启动奇数个的哨兵服务(通过src/redis-sentinel)。可以同sentinel的脚本启动,也可以用redis-server的脚本加sentinel参数启动。
1 | |
它的本质上只是一个运行在特殊模式之下的redis。Sentinel通过info命令得到被监听redis机器的master,slave信息。
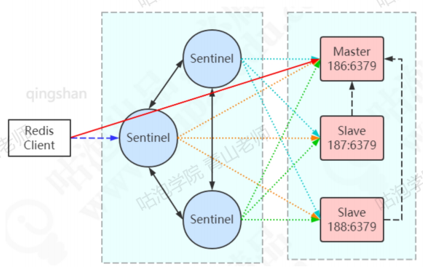
为保证监控服务器的可用性,会对Sentinel做集群的部署。Sentinel既监控所有的redis服务,Sentinel相互之间也监控。注意:Sentinel本身没有主从之分,地位是平等的,只有redis服务节点有主从之分。sentinel唯一的联系,就是监控相同的master,sentinel节点是怎么知道其他的Sentinel节点的存在的?因为Sentinel是一个特殊状态的redis节点,它也有发布订阅的功能。哨兵上线时,给所有的redis节点的名字为_sentinel_:hello的channle发送消息。每个哨兵都订阅了所有redis节点为_sentinel_:helo的channle,所以能相互感知对方的存在,而进行监控。
1.1 服务下线
sentinel默认以每秒钟1次的频率向redis服务节点发送ping命令。如果在指定时间内没有收到有效回复,sentinel会将该服务器标记为下线(主观下线)。由这个参数控制:
1 | |
默认是30秒。但是,只有发现master下线,并不代表master真的下线了。也有可能是网络出问题了。所以,这个时候第一个发现master下线的sentinel节点会继续询问其他的sentinel节点,确认这个节点是否下线,如果多数sentinel节点都认为master下线,master才真正被确认下线(客观下线)。确定master下线后,就需要重新选举master。Kafka有会在Broke里面选一个Controller出来。RocketMQ用Dledger技术选举(基于Raft协议)。
1.2 故障转移
Redis的选举和故障转移都是由sentinel完成的,故障转移流程的第一步就是在sentinel集群选择一个leader,由leader完成故障转移流程。Sentinel通过Raft算法,实现sentinel选举。
Raft算法
只要有了多个副本,就必然要面对副本一致性的问题。如果要所有的节点达成一致,必然要通过复制的方式实现。所以数据保持一致需要两个步骤:领导选举,数据复制。数据复制在redis主从复制中说过了,这里关注一下选举的实现。
Raft算法是一个共识算法(consensus algorith)。Spring cloud的注册中心解决方案Consul也用到了Raft协议。Raft的核心思想:先到先得,少数服从多数。sentinel的raft实现跟原生的算法有所区别,但是大体思想一致。
分布式环境中的节点有三个状态: Follower,Candidate,Leader.
一开始所有的节点都是Follower状态.如果follower连接不到leader(leader挂了),它就会成为candidate。candidate请求其他节点的投票,其他的节点会投给它,如果它得到了大多数节点的投票,它就成为了主节点.这个过程就叫做leader election。
现在所有的写操作需要在leader节点上发生。leader会记录操作日志,没有同步到其他follower节点的日志,状态是uncommitted。等到超过半数的follower同步了这条记录,日志状态就会变成committed。leader会通知所有的follower日志已经committed,这个时候所有的节点就达成了一致,这个过程叫log replication。
在raft协议中,选举的时候有两个超时时间。第一个叫election timeout,也就是说,为了防止同一时间大量节点参与选举,每个节点在变成candidate之前需要随机等待一段时间,时间范围是150ms and 300ms之间。第一个变成candidate的节点会先发起投票,它会先投给自己,然后请求其他节点投票(request vote)。
如果还没有收到投票结果,又到了超时时间,需要重置超时时间,只要有大部分节点投给了一个节点,他就会变成leader。
成为leader之后,它会发消息来同步数据(append entries),发消息的间隔是由heartbeat timeout的计时。
只要follower收到了同步数据的信息,代表leader没挂,他们就会清除heartbeat timeout的计时。
但是一旦followers在heartbeat timeout时间之内没有收到append entries消息,它就会认为leader挂了,开始让其他节点投票,成为新的leader。
必须超过半数以上节点投票,保证只有一个leader被选出来。
如果两个follower同时变成了candidate,就会出现分割投票,比如有两个节点同时变成candidate,而且各自有一个投票请求先达到了其他的节点。加上他们给自己的投票,每个candidate手上有两票。但是,因为他们的election timeout不同,在发起新的一轮选举的时候,有一个节点收到了更多的投票,所以它变成了leader。
总结:sentinel的raft算法和raft论文略有不同.
master客观下线触发选举,而不是过了election timeout时间开始选举。
leader并不会把自己成为leader的消息发送给其他sentinel。其他sentinel等待leader从slave选出master后,检测到新的master正常工作后,就会去掉客观下线的标识,从而不需要进入故障转移流程。
到达这里,从所有的sentinel节点里面选出来一个leader,也就是所谓选举委员会主席,下面才是真正的选举。
故障转移
对于所有的slave节点,一共有四个因素影响选举的结果,分别是断开连接时长、优先级排序、复制数量、进程id。
如果与哨兵连接断开的比较久,超过了某个阈值,就直接失去了选举权。
如果拥有选举权,那就看谁的优先级高,这个在配置文件里可以设置(replica-priority 100),数值越小优先级越高。
如果优先级相同,那就看谁从master中复制的数据最多(复制偏移量最大),选最多的那个。
如果复制量也相同,就选进程id最小的那个。
Master节点确定之后,让其他的节点变成它的从节点:
选出sentinel leader之后,由sentinel leader向某个节点发送slaveof no one命令,让他成为独立节点。
然后向其他节点发送slaveof x.x.x.x xxxx(本机ip端口),让它们成为这个节点的从节点,故障转移完成。
2 功能总结
监控:sentinel会不断检查主服务器和从服务器是否正常运行。
通知:如果某一个被监控的实例出现问题,sentinel可以通过命令发出通知。
自动故障转移(failover):如果主服务器发生故障,sentinel可以启动故障转移过程,把某台服务器升级为主服务器,并发出通知。
配置管理:客户端连接到sentinel,获取当前的redis主服务器的地址。
3 实战
3.1 Sentinel配置
为了保证sentinel的高可用,sentinel也需要做集群部署,集群中至少需要三个sentinel实例(推荐奇数个,防止脑裂).
| hostname | ip地址 | 节点角色&端口 |
|---|---|---|
| master | 192.168.44.186 | Master: 6379 / Sentinel: 26379 |
| slave1 | 192.168.44.187 | Slave: 6379 / Sentinel: 26379 |
| slave2 | 192.168.44.188 | Slave: 6379 / Sentinel: 26379 |
以redis的安装路径/user/local/soft/redis-6.0.9/为例,在187和188的src/redis.conf配置文件中添加
1 | |
在186,187,188创建sentinel配置文件(安装后根目录下默认有sentinel.conf),三台服务器内容相同:
1 | |
上面出现了4个’redis-master’,这个名称要统一,并且使用客户端(比如jedis)连接的时候要使用这个名字。
| 配置 | 作用 |
|---|---|
| protected-mode | 是否允许外部网络访问,yes不允许 |
| dir | sentinel的工作目录 |
| sentinel monitor | sentinel监控的redis主节点 |
| sentinel down-after-milliseconds(毫秒) | master宕机多久,才会被sentinel主观认为下线 |
| sentinel failover-timeout(毫秒) | 1.同一个sentinel对同一个master两次failover之间的间隔时间 2.当一个slave从一个错误的master那里同步数据开始计算时间,知道slave被纠正为向正确的master那里同步的数据时间。 3.当想要取消一个正进行的failover所需要的时间。 4.当进行failover时,配置所有slaves指向新的master所需的最大时间 |
| sentinel parallel-syncs | 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是这个数字越大,就意味着越多的slave因为replication而不可用,可以通过将这个值设为1来保证每次只有一个slave处于不能处理命令请求的状态 |
3.2 Sentinel验证
启动redis服务和sentinel,查看集群状态
1 | |
模拟宕机,在主节点执行
1 | |
某个节点会被选为新的master,只有一个slave节点。注意看sentinel.conf里面的redis-master被修改了!模拟原master恢复,启动redis-server。master又有两个slave了。
3.3 Sentinel连接使用
Jedis连接sentinel,master name来自于sentinel.conf的配置
1 | |
Springboot连接sentinel:
1 | |
无论是jedis还是springbot(2.x版本默认是Lettuce),都只需要配置全部哨兵的地址,由哨兵返回当前的master节点地址。
4 不足
主从切换的过程中会丢失数据,因为只有一个master。只能单点写,没有解决水平扩容的问题。如果数据量非常大,这个时候就要对redis的数据进行分片了。这个时候需要多个master-slave的group,把数据分布到不同的group中。