Redis分布式
如果要实现redis数据的分片,有三种方案。
第一种是在客户端实现相关的逻辑,例如用取模或者一致性哈希对key进行分片,查询和修改都先判断key的路由。
第二种是把做分片处理的逻辑抽取出来,运行一个独立的代理服务,客户端连接到这个代理服务,代理服务做请求的转发。
第三种就是基于服务端实现。
1 客户端Sharding-ShardedJedis
RedisTemplate就是对jedis的封装。
Jedis有几种连接池。比如这里一个连接到186,一个连接到windows的redis服务。
1 | |
通过dbsize命令发现,一台服务器有44个key,一台服务器有56个key。如果是希望数据分布相对均匀的话,首先可以考虑哈希后取模(因为key不一定是整数,所以先计算哈希)。
哈希后取模
例如,hash(key)%N,根据余数,决定映射到哪个节点。这种方式比较简单,属于静态的分片规则,但是一旦节点数量变化,由于取模的N发生变化,数据需要重新分布。为了解决这个问题,又有了一致性哈希算法。ShardedJedis实际上用的就是一致性哈希算法。
一致性哈希
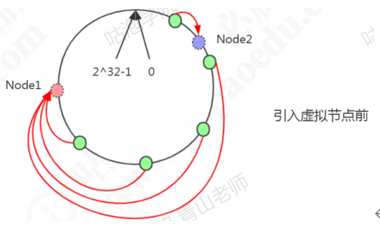
原理:把所有的哈希值空间组织成一个虚拟的圆环(哈希环),整个空间按顺时针方向组织。因为是环形空间,0和2^32-1是重叠的。假如有四台机器要哈希环来实现映射(分布数据),先根据机器的名称或者ip计算哈希值,然乎分布到哈希环中(红色圆圈)。
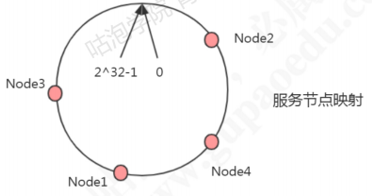
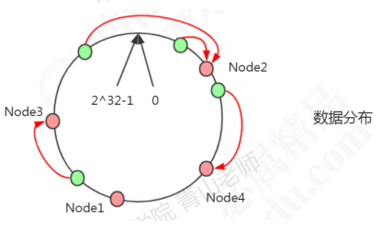
现在有4条数据或者4个访问请求,对key计算后,得到哈希环中的位置(绿色圆圈)。沿哈希环顺时针找到的第一个node,就是数据存储的节点。
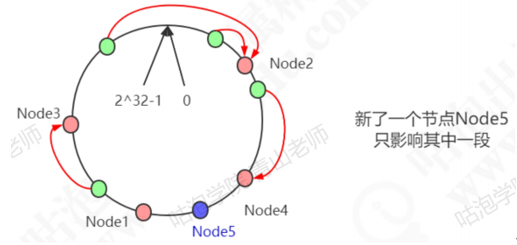
在这种情况下,新增了一个node5节点,只影响一部分数据的分布。
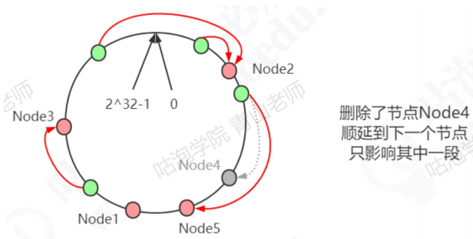
删除了一个节点node4,只影响相邻的一个节点。
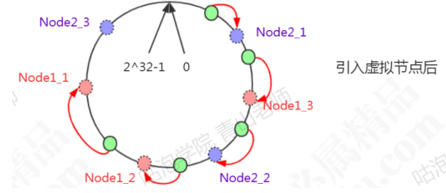
一致性哈希解决了动态增减节点时,所有数据都需要重新分布的问题,它只会影响到下一个相邻的系欸但,对其他节点没有影响。但是这样的一致性算法有一个缺点,因为节点不一定是均匀分布的,特别是在节点数比较少的情况下,所以数据不能得到均匀分布。解决这个问题的办法是引入虚拟节点(Virtual node)。
Node1设置了两个虚拟节点,node2也设置了两个虚拟节点(虚线圆圈)。这时候有3条数据分布到了node1,1条数据分布到了node2。
一致性哈希在分布式系统中,负载均衡,分库分表等场景中都有应用,跟LRU一样,是一个基础的算法。
java源码
Redis.client.util.Sharded.initialze(),jedis实例被放到了一棵红黑树TreeMap中。
1 | |
当存取键值对时,计算键的哈希值,然后从红黑树上摘下比该值大的第一个节点上的JedisShardInfo,随后从resources去除jedis。
1 | |
获取红黑树子集,找出比它大的第一个节点
1 | |
使用ShardedJedis之类的客户端分片代码的优势是配置简单,不依赖于其他中间件,分区的逻辑可以自定义,比较灵活。但是基于客户端的方案,不能实现动态的服务增减,每个客户端需要自行维护分片则略,存在重复代码。
2 代理Proxy
典型的代理分区方案有Twitter开源的Twemproxy和国内的豌豆荚开源的Codis。
2.1 Twemproxy
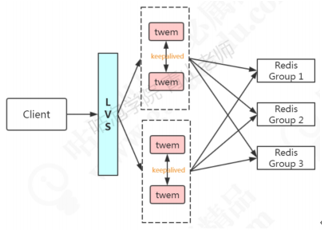
Twemproxy的优点:比较稳定,可用性高。
不足:
出现故障不能自动转移,架构复杂,需要借助其他组件(LVS/HAProxy+Keepalived)实现HA
扩缩容需要修改配置,不能实现平滑地扩缩容(需要重新分布数据)。
2.2 Codis
Codis是一个代理中间件,豌豆荚公司用Go语言开发的(快三年时间没有更新了)。跟数据库分库分表中间件的Mycat的工作层次是一样的。功能:客户端连接Codis跟连接redis没有区别。
| 功能特性 | Codis | Tewmproxy | Redis Cluster |
|---|---|---|---|
| 重新分片不需要重启 | yes | yes | yes |
| pipeline | yes | yes | – |
| 多key操作的hash tags {} | yes | yes | yes |
| 重新分片时的多key操作 | yes | – | no |
| 客户端支持 | 所有 | 所有 | 支持cluster协议的客户端 |
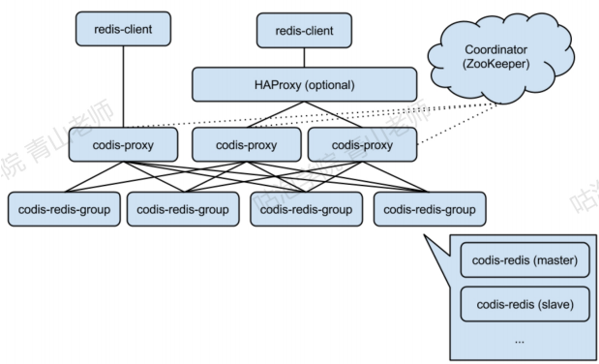
分片原理:Codis把所有的key分成了N个槽(例如1024),每个槽对应一个分组,一个分组对应于一个或者一组Redis实例。Codis对key进行CRC32运算,得到一个32位的数字,然后模拟N(槽的个数),得到余数,这个就是key对应的槽,槽后面就是redis实例(跟Mycat的先哈希后范围的算法思想类似)。比如4个槽:
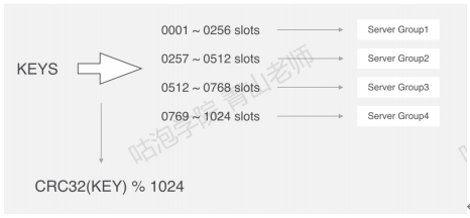
Codis的槽位映射关系是保存在proxy中的,如果要解决单点的问题,Codis也要做集群部署,多个Codis节点同步槽和实例的关系需要运行一个Zookeeper(或者etcd/本地文件)。
在新增节点的时候,可以为节点指定特定的槽位。Coids也提供了自动均衡策略。Codis不支持事务,其他的一些命令也不支持。获取数据原理(mget)在redis中的各个实例里获取到符合的key,然后再汇总到Codis中。Codis是第三方提供的分布式解决方案,再官网的集群功能稳定之前,Coids也得到了大量的应用。
3 Redis Cluster
Redis Cluster是在Redis3.0版本正式推出的,用来解决分布式的需求,同时也可以实现高可用。跟Codis不一样,它是去中心化的,客户端可以连接到任意一个可用节点。数据分片有几个关键的问题需要解决:
数据怎么相对均匀的分片
客户端怎么访问到相应的节点和数据
重新分片的过程,怎么保证正常服务
3.1 架构
Redis Cluster可以看成是由多个Redis实例组成的数据集合。客户端不需要关注数据到底存储在哪个节点,只需要关注这个集合整体。以3主3从为例,节点之间两两交互,共享数据分片,节点状态等信息。
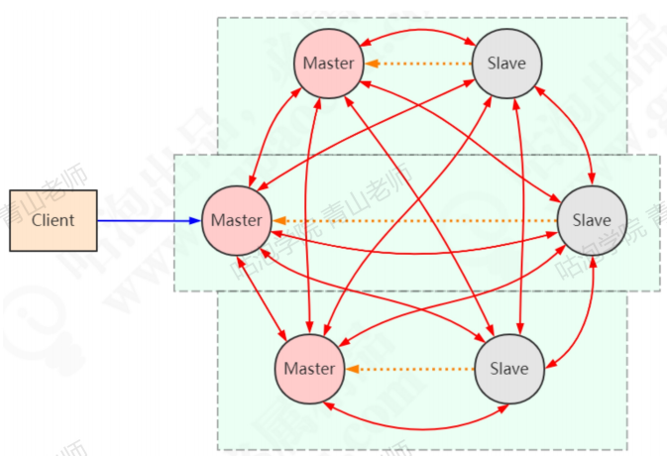
3.2 搭建
| 类型 | 命令 |
|---|---|
| 集群 | cluster info:打印集群的信息 cluster nodes:列出集群当前已知的所有节点,以及这些节点的相关信息 |
| 节点 | cluster meet <ip cluster forget<node_id cluster replicate<node_id cluster saveconfig:将节点的配置文件保存到硬盘中 |
| 槽(slot) | cluster addslots<slot cluster delslots<slot cluster flushslots:移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点 cluster setslot<slot cluster setslot<slot cluster setslot<slot cluster setslot<slot |
| 键 | cluster keyslot <key cluster countkeysinslot <slot cluster getkeysinslot<slot |
3.3 数据分布
Redis既没有用哈希取模,也没有用一致性哈希,而是用虚拟槽来实现的。Redis创建了16384个槽(slot),每个节点负责一定区间的slot。比如Node1负责0-5460,Node2负责5461-10922,Node3负责10923-163838.
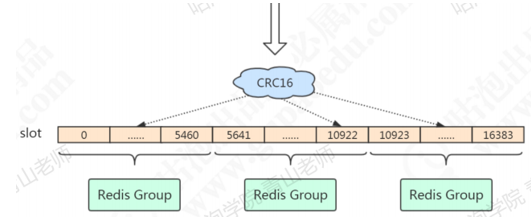
1 | |
对象分布到Redis节点上时,对key用CRC16算法计算再%16384,得到一个slot的值,数据落到负责这个slot的redis节点上。Redis的每个master节点都会维护自己负责的slot。用一个bit序列实现,比如:序列的第0位是1,就代表第一个slot是它负责;序列的第1位是0,就代表第二个slot不归它负责。查看key属于哪个slot:
1 | |
注意:key与slot的关系是永远不会变的,汇编的只有slot和redis节点的关系。
问题:怎么让相关的数据落到同一个节点上?
比如有些multi key操作是不能跨节点的,例如用户2673的基本信息和金融信息?
在key里面加入{hash tag}即可。Redis在计算槽编号的时候只会获取{}之间的字符串进行槽便哈计算,这样由于上面两个不同的键。{}里面的字符串是相同的,因此他们可以被计算出相同的槽。
3.4 客户端重定向
比如在7291端口的redis的redis-cli客户端操作:
1 | |
服务器返回MOVED,也就是根据key计算出来的slot不归7291端口管理,而是归7293端口管理,服务器返回MOVED告诉客户端去7293端口操作。这个时候更换端口,用redis-cli-p 7293操作,才会返回OK。或者用./redis-cli-c -o port的命令。Jedis等客户端会在本地维护一份slot——node的映射关系,大部分时候不需要重定向,所以叫做smart jedis(需要客户端支持)。
3.5 数据迁移
因为key和slot的关系是永远不会变的,当新增了节点的时候,需要把原有的slot分配给新的节点负责,并且把相关的数据迁移过来。
添加新节点(新增一个7297):
1 | |
新增的节点没有哈希槽,不能分布数据,在原来的任意一个节点上执行:
1 | |
输入需要分配的哈希槽的数量(比如500),和哈希槽的来源节点(可以输入all或者id)。
3.6 高可用和主从切换原理
当slave发现自己的master变成FAIL状态时,便尝试进行Failover,成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程,其过程如下:
slave发现自己的master变成Fail
将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息
其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack。
尝试failover的slave收集FAILOVER_AUTH_ACK
超过半数后变成新master
广播pong通知其他集群节点
总结:Redis Cluster既能够实现主从的角色分配,又能够实现主从切换,相当于集成了Replication和Sentinel的功能。
3.7 总结
Redis Cluster特点:
无中心架构
数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布。
可扩展性,可线性扩展到1000个节点(官方推荐不超过1000个),节点可动态添加或删除。
高可用性,部分节点不可用时,集群仍可用。通过增加Slave做standby数据副本,能够实现故障自动failover,节点之间通过gossip协议交换状态信息,用投票机制完成slave到master的角色提升。
降低运维成本,提高系统的扩展性和可用性。