Redis入门
1 redis定位与特性
1.1 SQL与NoSQL
大部分时候,我们都会首先考虑用关系型数据库来存储我们的数据,比如SQLServer,Oracle,MySQL 等等。关系型数据库的特点:
1.它以表格的形式,基于行存储数据,是一个二维的模式。
2.它存储的是结构化的数据,数据存储有固定的模式(scheme),数据需要适应表结构。
3.表与表之间存在关联(Reletionship)。
4.大部分关系型数据库都支持SQL(结构化查询语句)的操作,支持复杂的关联查询。
5.通过支持事务(ACID)来提供严格或者实时的数据一致性。
但是使用关系型数据库也存在一些限制,比如:
1.要实现扩容的话,只能向上(垂直)扩展,比如磁盘限制了数据的存储,就要扩大磁盘容量,通过堆硬件的方式,不支持动态的扩缩容。水平扩容需要复杂的技术来实现,比如分库分表。
2.表结构修改困难,因此存储的数据格式也收到限制。
3.在高并发和高数据量的情况下,关系型数据库通常会把数据持久化到磁盘,基于磁盘的读写压力比较大。
为了规避关系型数据库的一系列问题,就有了非关系型的数据库,一般把它叫做“non-relational”或者“Not Only SQL”。NoSQL 最开始是不提供SQL 的数据库的意思,但是后来意思慢慢地发生了变化。
非关系型数据库的特点:
1、存储非结构化的数据,比如文本、图片、音频、视频。
2、表与表之间没有关联,可扩展性强。
3、保证数据的最终一致性。遵循BASE(碱)理论。Basically Available(基本可用); Soft-state(软状态); Eventually Consistent(最终一致性)。
4、支持海量数据的存储和高并发的高效读写。
5、支持分布式,能够对数据进行分片存储,扩缩容简单。
对于不同的存储类型,又有各种各样的非关系型数据库,比如有几种常见的类型:
1 、KV 存储, 用Key Value 的形式来存储数据。比较常见的有Redis 和MemcacheDB。
2、文档存储,MongoDB。
3、列存储,HBase。
4、图存储,这个图(Graph)是数据结构,不是文件格式。Neo4j。
5、对象存储。
6、XML 存储等等等等。
这个列举了各种各样的NoSQL 数据库http://nosql-database.org/ 。NewSQL 结合了SQL 和NoSQL 的特性(例如PingCAP 的TiDB)。
1.2Redis特性
官网介绍:https://redis.io/topics/introduction
中文网站:http://www.redis.cn
硬件层面有CPU 的缓存;浏览器也有缓存;手机的应用也有缓存。把数据缓存起来的原因就是从原始位置取数据的代价太大了,放在一个临时位置存储起来,取回就可以快一些。
1.为什么要把数据放在内存中?
1)内存的速度快,10w QPS
2)减少计算的时间,减轻数据库的压力
2.如果是用内存的数据结构作为缓存,为什么不用HashMap或者Memcached?
1)更丰富的数据类型
2)进程内与跨进程;单机与分布式
3)功能丰富:持久化机制、内存淘汰策略,事务,发布订阅,pipeline,lua
4)支持多种编程语言
5)高可用,集群
注:Memcached只能存储KV,没有持久化机制,不支持主从复制,是多线程的。
2 redis安装启动
2.1 服务端安装
1、Linux 安装
CentOS7 安装Redis 单实例https://gper.club/articles/7e7e7f7ff7g5egc4g6b
Docker 安装Redishttps://gper.club/articles/7e7e7f7ff7g5egc5g6c
主要是注意配置文件几处关键内容(后台启动、绑定IP、密码)的修改,配置别名
2、Windows 服务端安装
自行百度
2.2 服务启动
src 目录下,直接启动 ./redis-server
后台启动(指定配置文件)1、redis.conf ->修改两行配置daemonize yes ;bind 0.0.0.0
2、启动Redis -> redis-server /usr/local/soft/redis-5.0.5/redis.conf
总结:redis 的参数可以通过三种方式配置,一种是redis.conf,一种是启动时–携带的参数,一种是config set。
2.3 基本操作
Redist默认有16个库(0-15).可以在配置文件redis.conf中修改 database 16
因为没有完全隔离,不像数据库的database,不适合把不同的库分配给不同的业务使用。默认使用第一个库db0。在集群中只能使用第一个db。
1 | |
Redis的存储叫做key-value存储,或者叫做字典结构。key的最大长度限制是512M,值得限制不同,有的是用长度限制,有的是用个数限制。先从key的基本操作入手。
1 | |
3 redis基本数据类型
3.1 String字符串
存储类型
可以用来存储INT(整数),float(单精度浮点数),String(字符串)
操作命令
1 | |
存储实现原理
1.数据模型
Redis是KV的数据库,Key-value一般会用哈希表来存储它。Redis的最外层是通过hashtable实现的(把这个叫做外层的哈希)。在redis里面。这个哈希表怎样实现呢?看一下C语言的源码(dict.h 47行),每一个键值对都是一个dictEntry(怪不得叫远程字典服务),通过指针指向key的存储结构和value的存储结构,而且next 存储了指向下一个键值对的指针。
1 | |
实际上最外层是redisDb,redisDb里面放的是dict。源码server.h 661行
1 | |
以set hello world为例,因为key是字符串,Redis自己实现了一个字符串类型,叫做SDS,所以hello指向一个SDS的结构。
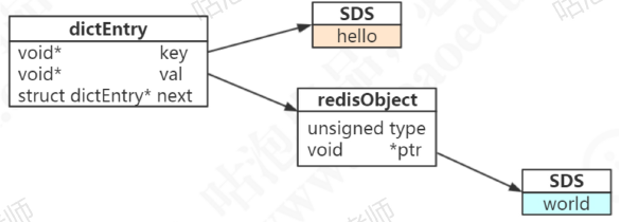
value是world,同样是一个字符串,当value存储一个字符串时,Redis并没有直接使用SDS存储,而是存储在redisObject中,实际上五种常用的数据类型的任何一种value,都是通过redisObject来存储的。最终redisObject再通过一个指针指向实际的数据结构,比如字符串或者其他。来看一下redisObject怎么定义的:redisObject:源码src/server.h 622行
1 | |
用type命令看到的类型就是type的内容。
为什么一个value会有一种对外的类型,还有一种实际的编码呢?我们刚才说字符串会用SDS存储,那这个redisObject的value就会指向一个SDS:
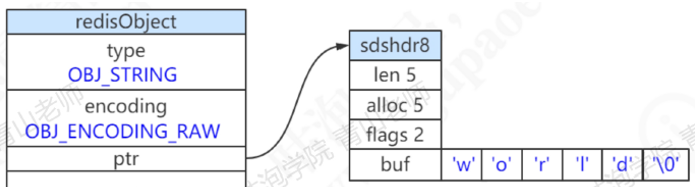
2.内部编码
用的String的命令,但是出现了三种不同的编码。这三种编码有什么区别?
(1)int,存储8个字节的长整型(long, 2^63-1)
(2)embstr,代表embstr格式的SDS,存储小于44个字节的字符串
(3)raw,存储大于44个字节的字符串
问题1,SDS是什么?
Redis中字符串的实现,Simple Dynamic String简单动态字符串。源码:sds.h 47行
1 | |
本质上其实还是字符数组。SDS又有多种结构(sds.h):sdshdr5,sdshdr8,sdshdr32,sdshdr32,sdshdr64,用于存储不同长度的字符串,分贝代表2^5=32byte,2^8=256byte, 2^16=65536byte=64KB, 2^32byte=4GB。
问题2:为什么Redis要用SDS是实现字符串?
因为C语言本身没有字符串类型,只能用字符串数组char[]实现。
(1)使用字符串数组必须先给目标变量分配足够的空间,否则可能会溢出
(2)如果要获取字符长度,必须遍历字符数组,时间复杂度是O(n)
(3)C字符长度的变更会对字符数组做内存重分配
(4)通过从字符串开始到结尾碰到的第一个‘\0’来标记字符串的结束,因此不能保存图片,音频,视频,压缩文件等二进制(bytes)保存的内容,二进制不安全。
SDS的特点:
1.不用担心内存溢出问题,如果需要会对SDS进行扩容
2.获取字符串长度时间复杂度为O(1),因为定义了len属性
3.通过“空间预分配”(sdsMakeRoonFor)和“惰性空间释放”,防止多次重分配内存
4.判断是否结束的标志是len属性,可以包含‘\0‘(它同样以’\0’结尾是因为这样就可以使用C语言中函数库操作字符串的函数了)
| C字符数组 | SDS |
|---|---|
| 获取字符串长度的复杂度为O(N) | 获取字符串长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
问题3:embstr和raw编码的区别?为什么要为不同大小设计不同编码?
embstr的使用值分配一次内存空间(因为RedisObject和SDS是连续的),而raw需要分配两次内存空间(分别为RedisObject和SDS分配空间)。embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
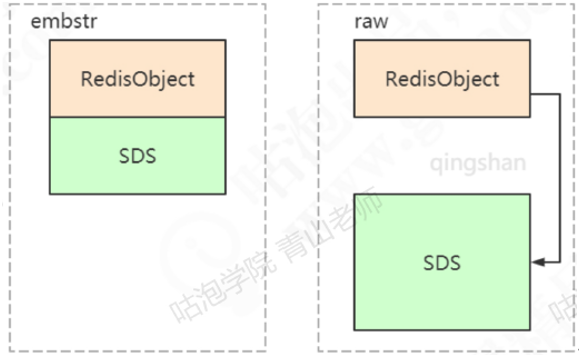
而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个RedisObject和SDS都需要重新分配空间,因此Redis中的embstr实现为只读(这种编码的内容是不能修改的)。
问题4:int和embstr什么时候转化为raw?
int数据不再是整数——raw
int大小超过了long的范围(2^63-1)——embstr
embstr长度超过了44个字节——raw
明明没有超过44个字节,为什么变成raw了?
对于embstr,由于它的实现是只读的,因此在对embstr对象进行修改时,都会先转化为raw再进行修改。因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
问题5:当长度小于阈值时,会还原吗?
关于Redis内部编码的转换,都符合一下规律:编码转换在Redis写入数据时完成,且转换过程不可逆转,只能从小内存编码向大内存编码转换。
问题6:为什么要对底层的数据结构使用redisObject进行一层包装呢?
其实无论是设计redisObject,还是对存储字符设计这么多的SDS,都是为了根据存储的不同内容选择不同的存储方式,这样可以实现尽量地节省内存空间和提升查询速度的目的。
应用场景
1.缓存
String类型,缓存热点数据。例如明星出轨,网站首页,报表数据等等。可以显著提升热点数据的访问速度。
2.分布式数据共享
String类型,因为Redis是分布式的独立服务,可以在多个应用之间共享
3.分布式锁
String类型的setnx方法,只有不存在时才能添加成功,返回true。
1 | |
4.全局ID
INT类型,INCRBY,利用原子性(分库分表的场景,一次性拿一段)
5.计数器
INT类型,INCR方法。例如:文章的阅读量,微博点赞数,允许一定的延迟,先写入Redis再定时同步到数据库
6. 限流
INT类型,INCR方法。以访问者的IP和其他信息作为key,访问一次再增加一次计数,超过次数则返回false。
3.2 Hash哈希
存储类型
Hash用来存储多个无序的键值对。最大存储数量2^32-1(40亿左右)。
注意:前面说Redis所有的KV本身就是键值对,用dictEntry实现的,叫做外层的哈希,现在我们讲的是内层的哈希。
注意:Hash的value只能是字符串,不能是嵌套其他类型,比如hash或者list。
同样是存储字符串,Hash和String的主要区别?
把所有相关的值聚集到一个key中,节省内存空间
只使用一个key,减少key中途
当需要批量获取值的时候,只需要使用一个命令,减少内存IO/CPU的消耗
Hash不适合的场景:
Field不能单独设置过期时间
需要考虑数据量分布的问题(field非常多的时候,无法分布到多个节点)
操作命令
1 | |
存储(实现)原理
Redis的Hash本身也是一个KV结构,内层哈希底层可以使用两种数据结构实现:
(1)Ziplist: OBJ_ENCODING_ZIPLIST(压缩列表)
(2)Hashtable:OBJ_ENCODING_HT(哈希表)
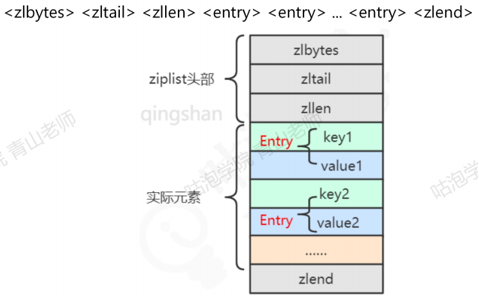
1.ziplist压缩列表
ziplist是一个经过特殊编码的,由连续内存块组成的双向链表。它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,这样读写可能会慢一些,因为你要去算长度,但是可以节省内存,是一种时间换空间的思想。
Ziplist的内部结构-源码ziplist.c第16行的注释:
1 | |
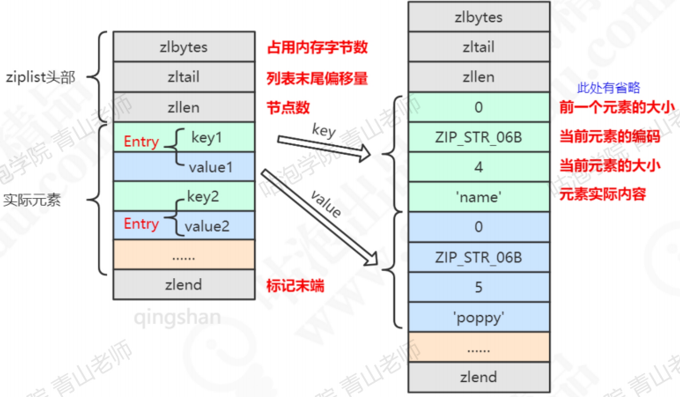
编码类型:
1 | |
问题:什么时候使用ziplist存储?
当哈希对象同时满足一下两个条件的时候,使用ziplist编码:
1) 哈希对象保存的键值对数量<512个
2) 所有的键值对的键和值的字符串长度都<64byte(一个英文字母一个字节)
src/redis.conf配置
1 | |
如果超过这两个阈值的任何一个,存储接后就会转换为hashtable。总结:字段个数少,字段值小,用ziplist。
2.hashtable(dict)
在redis中,hashtable被称为字典(dictionary)。前面我们知道了,Redis的KV结构是通过一个dictEntry来实现的。在hashtable中,又对dictEntry进行了多层的封装。源码位置Ldict.h 47行。首先有一个dictEntry:
1 | |
dictEntry放到了dictht(hashtable里面):
1 | |
Ht放到了dict里面:
1 | |
从最底层到最高层dictEntry——dictht——dict。它是一个数组+链表的结构,展开一下,哈希的整体存储结构:
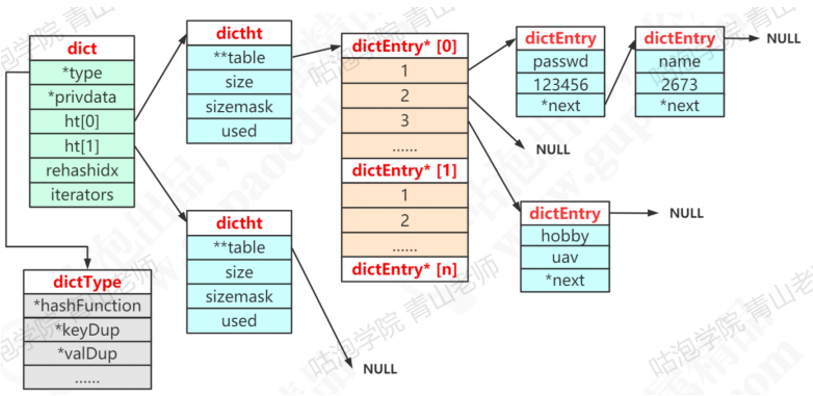
注意:dictht后面是null说明第二个ht还没有用到。DictEntry*后面是Null说明没有hash到这个地址。DictEntry后面是NULL说明没有发生哈希冲突。
问题:为什么要定义两个哈希表,其中一个不同呢?
Redis的哈希默认使用的是ht[0],ht[1]不会初始化和分配空间。哈希表dictht是用链地址法来解决碰撞问题的。在这种情况下,哈希表的性能取决于它的大小(size属性)和它锁保存的节点的数量(used属性)之间的比率:
*比率在1:1时(一个哈希表ht只储一个节点entry)哈希表的性能最好。
*如果节点数量比哈希表的大小要大很多的话(这个比率用ratio表示,5标识平均一个ht存储5个entry),那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在。
如果单个哈希表的节点数量过多,哈希表的大小需要扩容。Redis里面的这种操作叫做rehash。步骤:
为字符ht[1]哈希表分配空间,ht[1]的大小为第一个大于等于ht[0].used*2的2的N次方幂。比如已经使用了10000,那就是16384.
将所有的ht[0]上的节点rehash到ht[1]上,重新计算hash值和索引,然后放入指定的位置。
当ht[0]全部迁移到了ht[1]之后,释放ht[0]的空间,将ht[1]设置为ht[0]表,并创建新的ht[1],为下次rehash做准备。
问题:什么时候触发扩容?
负载因子(源码dict.c)
1 | |
总结一下,Redis的Hash类型,可以用ziplist和hashtables来实现。
应用场景
1. 跟String一样
String可以做的事情。Hash都可以做
2.存储对象类型的数据
比如对象或者一张表的数据,比String节省了更多key的空间,也更加便于集中管理。
3.3 List列表
存储类型
存储有序的字符串(从左到右),元素可以重复。最大存储数量2^32-1(40亿左右)。

操作命令
1 | |
存储(实现)原理
在早期的版本中,数据量较小时用ziplist存储(特殊编码的双向链表),达到临界值时转换为linkedlist进行存储,分别对应OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_LINKEDLIST。3.2版本之后,统一用quicklist来存储。quicklist存储了一个双向链表,每个节点都是一个ziplist,所以是ziplist和linkedlist的结合体。
quicklist:总体结构:
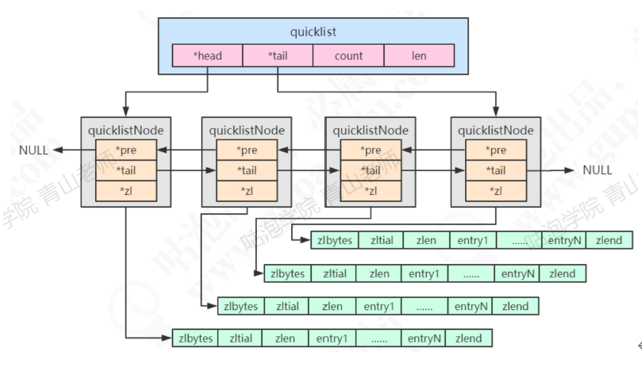
1 | |
redis.conf相关参数:
| 参数 | 含义 |
|---|---|
| list-max-ziplist-size (fill) | 正数表示单个ziplist最多所包含的entry个数 负数表示单个ziplist的大小,默认8K |
| list-compress-depth (compress) | 压缩深度,默认为0。 1:首尾的ziplist不压缩;2:首尾第一第二个ziplist不压缩,以此类推 |
quicklist.h 46行:
1 | |
应用场景
list主要用在存储有序内容的场景。
1.列表
例如用户的消息列表,网站的公告列表,活动列表,博客的文章列表,评论列表等等。思路:存储所有字段,LRANGE取出一页,按顺序显示。
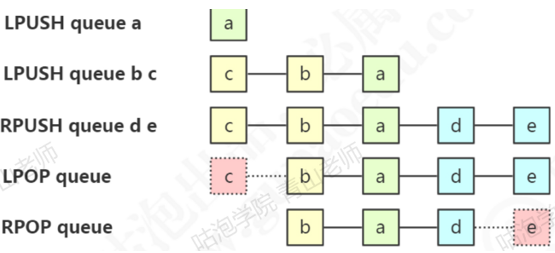
2.队列/栈
list还可以当作分布式环境的队列/栈使用。list提供了两个阻塞的弹出操作:BLPOP/BRPOP,可以设置超时时间(单位:秒).
BLPOP:BLPOP key 1 timeout移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOP:BRPOP key 1 timeout移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。

队列:先进先出:rpush blpop,左头右尾,有便进入队列,左边出队列。
栈:先进后出:rpush brpop
总结一下:List存储有序的内容,用quicklist实现,本质上是数组——链表。Hashtable也是数组+链表,只是内部编码结构不一样。
3.4 Set集合
存储类型
Set存储String类型的无序集合,最大存储数量2^32-1(40亿左右)。
操作命令
1 | |
存储(实现)原理
Redis用inset或hashtable存储set。如果元素都是整数类型,就用inset存储。inset.h 35行
1 | |
如果不是整数类型,就用hashtable(数组+链表的存储结构),如果元素超过512个,也会用hashtable存储,跟一个配置有关
1 | |
问题:set的key没有value,怎么用hashtable存储?value存null就好了。
应用场景
抽奖:随机获取元素:spop myset。点赞,签到,打卡。商品标签。商品筛选。用户关注,推荐模型
3.5 ZSet有序集合
存储类型
sorted set存储有序的元素。每个元素有个score,按照score从小到大排名。score相同时,按照key的ASCII码排序。
| 数据结构 | 是否允许存在重复元素 | 是否有序 | 与有序实现方式 |
|---|---|---|---|
| 列表list | 是 | 是 | 索引下标 |
| 集合set | 否 | 否 | 无 |
| 有序集合zset | 否 | 否 | 分值score |
操作命令
1 | |
存储(实现)原理
默认使用ziplist编码(第三次见到了,hash的小编码,quicklist的Node,都是ziplist)。在ziplist内部,按照score排序递增来存储,插入的时候要移动之后的数据。如果元素数量大于等于128个,或者任一member长度大于等于64字节使用skiplist+dict存储。
1 | |
什么是skiplist(跳表)?
我们先来看一下有序链表:

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止。时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。二分查找只适用于有序数组,不适用于链表。
假如我们每相邻两个节点增加一个指针,让指针指向下个节点(或者理解为有三个元素进入了第二层)。

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一般(上图中是7,19,26)
问题:是哪些元素运气这么好,进入到第二层?在插入一个数据的时候,决定要放到哪一层,取决于一个算法,源码:t_zset.c 122行
1 | |
现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再到下一层进行查找。

比如,我们想查找23,查找的路径是沿着标红的指针所指向的方向进行的:
1.23首先和7比较,再和19比较,比它们都大,继续向后比较。
2.但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与19在第一层的下一个节点22比较。
3.23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较节点数大概只有原来的一般。这就是跳表。为什么不用AVL树或者红黑树?因为skiplist更加简洁。因为level是随机的,得到的skiplist可能是这样的,有些在第四层,有些在第三层,有些在第二层,有些在第一层。

1 | |
应用场景
顺序会动态变化的列表, 比如:排行榜
3.6 其他数据结构简介
3.6.1 BitMaps
bitMaps是在字符串类型上面定义的位操作。一个字节由8个二进制位组成。

set k1 a
获取value在offset处的值(a对应的ASCII码是97,转换为二进制数据是01100001)
getbit k1 0
修改二进制数据
setbit k1 6 1
setbit k1 7 0
get k1
问题:怎么变成b了?(b对应的ASCII码是98,二进制数是01100010)
统计二进制位中1的个数
bitcount k1
获取第一个1或者0的位置
bitpos k1 1
bitpos k1 0
因为bit非常节省空间(1MB=8388608bit),可以用来做大数据量的统计。
应用场景:用户访问统计, 在线用户统计
3.6.2 Hyperloglogs
Hyperloglogs:提供了一种不太精确的基数统计方法,用来统计以集合中不重复的元素个数,比如统计网站的UV,或者应用的日活,月活,存在一定的误差。在redis中实现HyperLogLog,只需要12K内存就能统计2^54个数据。
3.6.3 Geo
消费金融,给客户使用的客户端有这么一个需求,要获取半径1公里以内的门店,那么我们就要把门店的经纬度保存起来。那个时候我们是直接把经纬度保存到数据库的,一个字段存经度一个字段存维度。计算距离比较复杂。Redis的GEO直接提供了这个方法。
操作:增加地址位置信息,获取地址位置信息,计算两个位置的距离,获取指定范围内的地理位置集合等等。
3.6.4 Streams
5.0推出的数据类型。支持多播的可持久化的消息队列,用于实现发布订阅功能,借鉴了kafka的设计。
3.7 总结
| 对象 | 对象type属性值 | type命令输出 | object_encoding |
|---|---|---|---|
| 字符串对象 | OBJ_STRING | string | int embstr raw |
| 列表对象 | OBJ_LIST | list | quicklist |
| 哈希对象 | OBJ_HASH | hash | ziplist hashtable |
| 集合对象 | OBJ_SET | set | intset hashtable |
| 有序集合对象 | OBJ_ZSET | zset | ziplist skiplist+hashtable |
应用场景总结
缓存——提升热点数据库的访问速度
共享数据——数据的存储和共享的问题
全局ID——分布式全局ID的生成方案(分库分表)
分布式锁——进程间共享数据的原子操作保证
在线用户统计和计数
队列,栈——跨进程的队列/栈
消息队列——异步解耦的消息队列
服务注册与发现——RPC通信机制的服务协调中心(Dubbo支持Redis)
购物车
新浪/Twitter 用户消息时间线
抽奖逻辑(礼物,转发)
点赞,打卡,签到
商品标签
用户(商品)关注(推荐)模型
电商产品筛选
排行榜